In a recent episode of RAG Brag, Mike Heap and Alex Rainey, founders of My AskAI, shared how they use LLMs and other modern AI tech to empower SaaS businesses to create AI customer support agents using their own documentation to reduce customer support volumes and gather actionable feedback for product improvement.
Mike Heap and Alex Rainey founded My AskAI thanks to their different professional experiences and shared entrepreneurial spirit. Mike's job at Ernst & Young got him excited about AI and automation, while Alex's time at Accenture helped him learn team management and digital solutions. After working together on several small projects, they saw how AI could improve customer support. This conversation explores how it all began and the lessons they learned while building AI software.
Mike: Initially, we launched a broad-use product that allowed users to input information and get answers. This was used in various contexts, from students to law firms. However, it became challenging to prioritize features and market the product effectively. We decided to focus on customer support, which accounted for 70% of our revenue. This focus allowed us to refine our product, making it more efficient and easier to market. We rebuilt My AskAI with this focus, launching a version specifically for customer support, which has been very well received.
Mike: ChatGPT is versatile but limited in UI and prone to make-up facts. My AskAI uses Retrieval-Augmented Generation (RAG) to ground responses in domain specific information, reducing hallucinations. We offer a tailored UI for customer support that can be deployed on websites or integrated into existing platforms. Our focus on usability and customization ensures users get the most relevant and accurate responses. Additionally, our product can identify when it can't answer a question and seamlessly hand it over to a human agent if needed.

Mike: Our product stands out with several key features that make it an excellent tool for creating custom AI support agents. Our system includes a human handover capability, recognizing when it can't answer a question and seamlessly handing it over to a human agent, integrating with platforms like Intercom and Zendesk. We ensure high-quality responses by fine-tuning our prompts and retrieval processes, which are validated through rigorous testing with large businesses. Our AI-generated insights from conversations help businesses identify common issues and improve their products and documentation. Additionally, we offer third-party knowledge integration, pulling information from various sources, not just help docs, making our solution more versatile. Lastly, the same AI support can be used on customer-facing websites and internally within companies, enhancing both customer and employee experiences. These features combine to create a robust, efficient, and highly customizable AI solution for customer support.
Alex: My AskAI uses a sophisticated RAG architecture, which means we retrieve a small subset of relevant information from a wide range of data to feed into our AI model. For instance, if we scrape an entire website, we might only pull a few relevant paragraphs to answer a specific query. We use several key tools and services to achieve this. Pinecone is used for vector storage and retrieval; it’s super fast, easy to set up, and cost-effective, which is crucial since vector storage can be expensive. Bubble, a no-code editor, handles much of our front-end and some back-end work, allowing us to rapidly develop and deploy new features—like launching a new integration in just a few days. Carbon is essential for web scraping and accessing third-party information, enabling us to efficiently bring in data from various sources. Finally, PortKey, an LLM gateway, manages our AI model requests. It provides fallback models if a primary service like OpenAI goes down and allows us to cache responses, saving both time and money.
Alex: Our chunking strategy involves breaking down large texts into 400-token chunks with 20-token overlaps. This ensures that our AI models can process and retrieve information efficiently. We recently upgraded to the latest OpenAI embedding models, which improved our performance by ~20%. We use LangChain for text splitting, which helps us handle large volumes of text, like entire web pages. We’re always testing to see if our current chunking strategy is still optimal.
Alex: We focus on customer support-related data, like help docs and website content. We’ve learned that not all data works well with LLMs. For instance, tables, poorly written documents, and sparse web pages often cause issues. We minimize pre-processing and focus on optimizing our system to handle the kind of information our customers typically provide. This means prioritizing well-structured content and continually refining our retrieval strategy to ensure accuracy and relevance.
Mike: One of the biggest challenges was keeping up with the rapid pace of AI advancements. Each new model update from OpenAI significantly impacts answer quality. We have to evaluate each update’s practicality and decide whether to adopt it. Additionally, there’s a lot of noise in the AI space, with many people trying out different use cases. We focus on solving real problems for our customers and demonstrating our value to differentiate ourselves. Finding repeatable distribution channels was also challenging. Early on, AI newsletters and influencers helped, but these channels have a short lifespan. We constantly seek effective ways to convert and retain customers.
Alex: From a technical standpoint, working with LLMs like GPT-4 or GPT-3.5 is like handling a wild beast: immensely powerful but often unpredictable. These models can be disobedient and hypersensitive, frequently ignoring instructions or behaving unexpectedly. This requires extensive and rigorous testing, as even small prompt changes can significantly impact the output. Building a business on LLMs demands patience, meticulous testing, and constant vigilance to maintain quality and reliability.
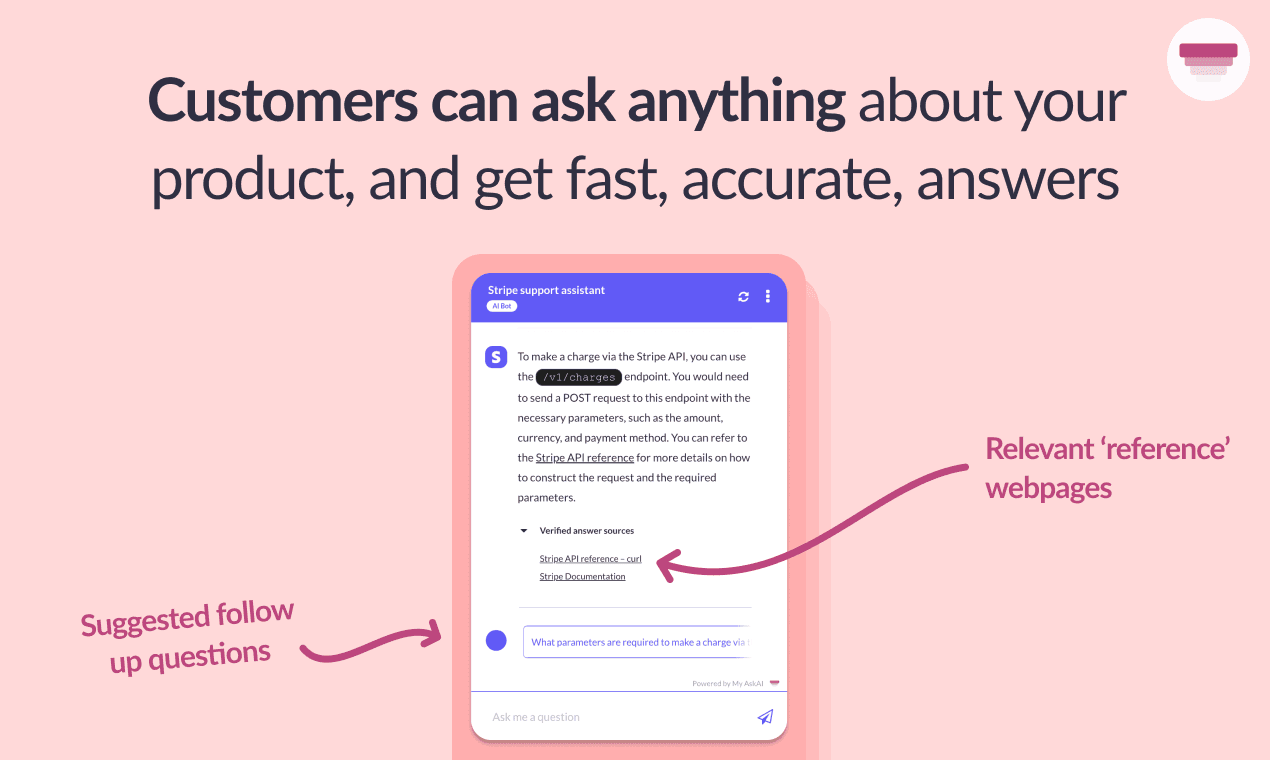
Alex: We prioritize thorough testing and continuous refinement of our prompts and processes. This helps us manage the unpredictability of LLMs. We ensure our models are well-tuned to handle the specific types of queries and data they encounter. Additionally, our use of fallback models, which act as a backup plan for situations where the main model struggles to generate a suitable response, along with response caching through PortKey, helps to maintain service reliability and efficiency, even when primary models encounter issues.
Mike: The key is to stay focused on solving real problems for your customers. The AI landscape is constantly evolving, and it’s easy to get distracted by new technologies and trends. However, it’s important to assess whether these advancements provide practical benefits for your use case or not. Building a solid, customer-centric approach and maintaining flexibility to adapt to new developments will help you succeed in the long run.
More RAG Brag
To learn more from Mike and Alex, you can watch the entire recording or visit their website. We'll be bringing you more conversations with AI industry leaders as part of our RAG Brag series. Stay tuned for upcoming episodes!
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。