Pinecone Serverless simplifies scaling and running vector databases – once vector indexes are built and optimized. Going from unstructured data to optimized vector indexes can be challenging, So we are excited to announce that Pinecone has teamed up with Vectorize to streamline this process and make it easier to build LLM-powered applications on top of Pinecone.
For most AI engineers and RAG developers, building a vector index that delivers optimized relevancy is an exercise in trial and error. Since most vector embeddings originate from unstructured data sources, there can be considerable preprocessing that must occur before the data can be loaded into a vector database. This preprocessing involves data extraction, cleansing, and formatting tasks before it is ready for vectorization. Each of these steps is critical because errors or oversights can significantly degrade the quality of the resulting text embeddings.

Credit: Midjourney
Choosing the best embedding model and chunking strategy is a key part of this preprocessing effort.Developers must evaluate which methods best suit their specific data sets. Often, developers rely on ad-hoc scripts to evaluate various approaches, which can be difficult to compare and may result in hallucinations once in production. In order to avoid this, the best decisions on embedding models and chunking strategies should be a a quantitative, data-driven approach.
Enter Vectorize, an innovative platform designed to transform the way AI developers handle vectorization. By automating the cumbersome and often error-prone process of data preprocessing and optimization, Vectorize enables a more systematic and data-driven approach to building vector indexes.
Vectorize offers a suite of tools that empower developers to run experiments with different embedding models, chunking strategies, and retrieval settings without the need for extensive scripting or guesswork. This allows for a more precise evaluation of which combinations yield the best relevancy for specific datasets, replacing gut feel with hard data.
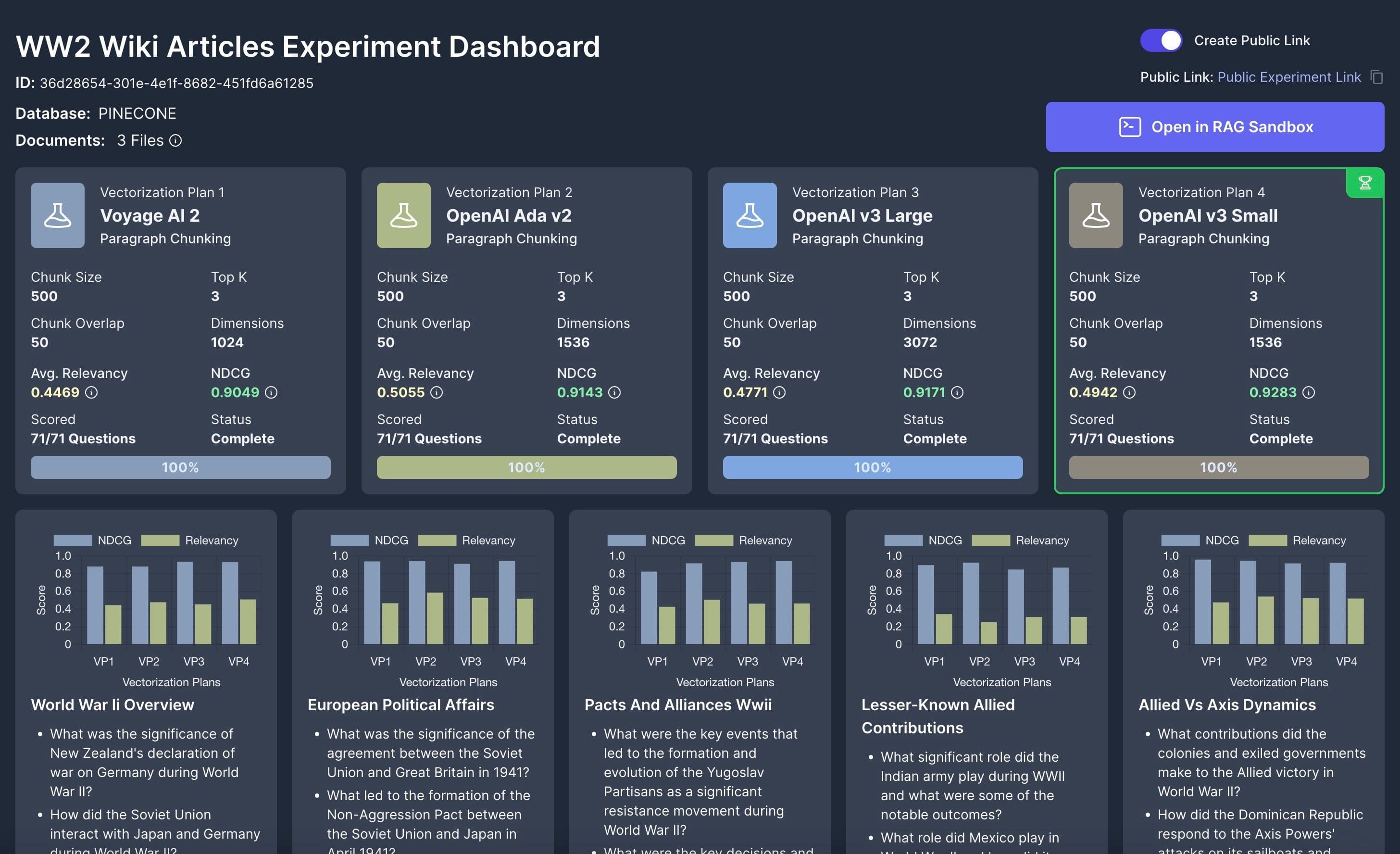
Experiments in Vectorize provide a data-driven approach to building your RAG vector pipeline.
While concrete data is immensely useful, you want to verify your results with your own experience. For this, Vectorize provides a RAG Sandbox, an interactive console that lets you assess the relevance of the chunks returned from your vector database and experience how well that context integrates into an end-to-end RAG LLM workflow.
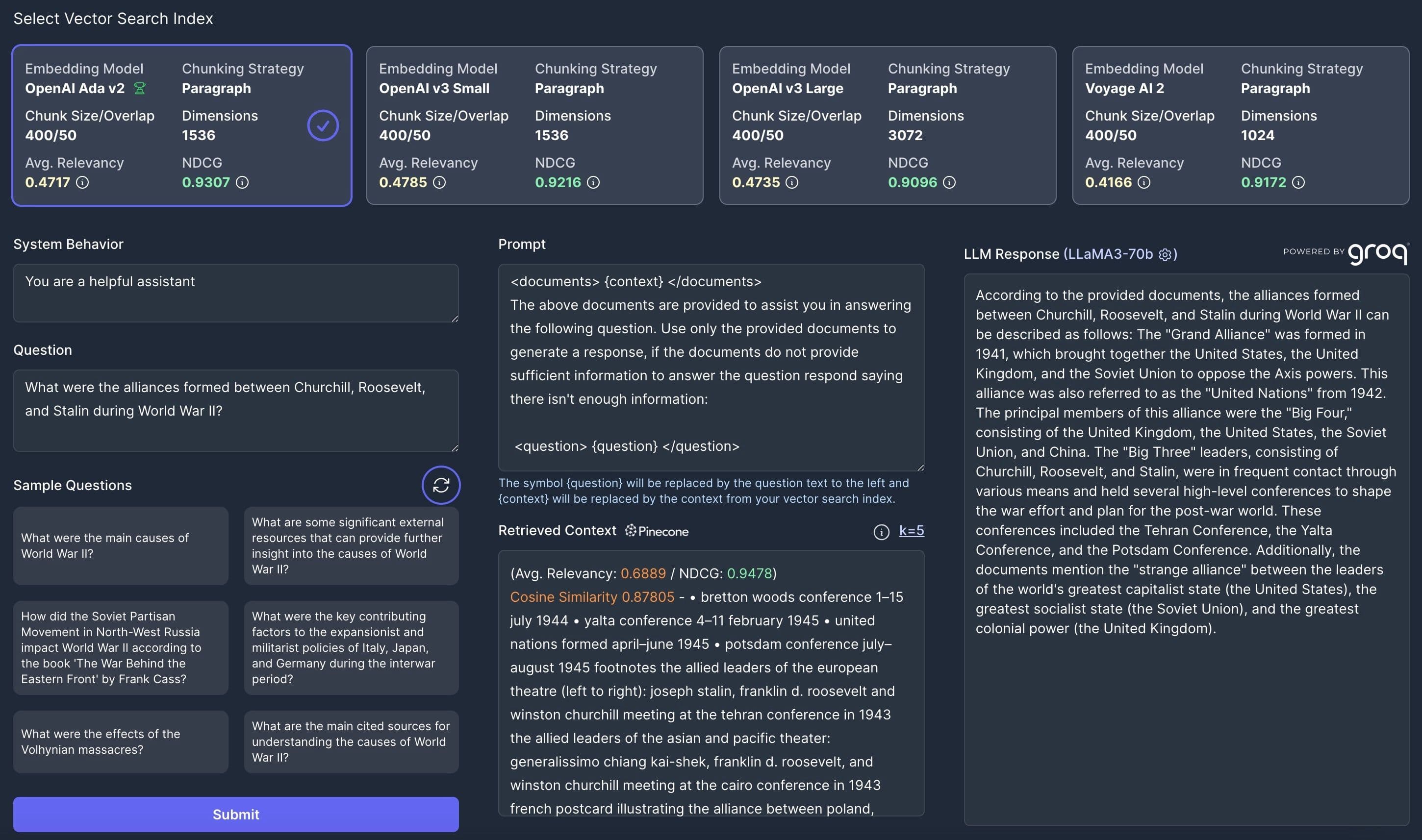
The Vectorize RAG Sandbox is a powerful tool to inspect exactly how your vector data and LLM will interact to generate responses.
With the Vectorize RAG Sandbox, you can see what context gets returned from your vector search query and how your favorite LLM will generate a response based on that context.
Best of all, Vectorize integrates seamlessly with Pinecone Serverless to ensure accuracy both in development and in production.
The Pinecone and Vectorize integration is more than just a technological innovation —it's a transformative tool that supercharges your RAG development process. It seamlessly integrates the operational superpowers of Pinecone serverless with the data-driven agility of Vectorize, AI engineers gain the capability to deliver accurate, production-ready RAG pipelines with unprecedented efficiency and accuracy.
Whether you're developing advanced customer support bots, personalized recommendation systems, or dynamic content delivery engines, the combination of Pinecone and Vectorize equips you with the tools to elevate your applications to ensure more relevant context and more accurate results.
To experience how Vectorize delivers insights into the optimal vectorization strategy for your data, sign up for a Vectorize account at https://platform.vectorize.io and visit the quickstart documentation.
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。