LangChain是大语言模型应用快速搭建的框架,目前官网提出了Python和JS版本(Java版本 在github上有翻版,对比官方还是差点,后续会单独聊),目前对LangChain的技术博客不算很多,这里通过自己的思考+接合官方文档做一个输出,也是对自己思考的留痕方便后续查漏补缺。
LangChain?在 官网上对它用途介绍是:
1 | |
翻译过来就是说LangChain简化了LLM应用生命周期的每个阶段
对开发大模型的段官网定义有三个,分别是:开发、产品化、部署。这里简单画图帮助理解:

紫色部分是LangChain官方平台:
LangGraph Platfrom并且提供了基础设施,可用于快速部署Agent应用LangSmith更好的跟踪LangChain应用, 提供可观察性、评估及提示工程黑色和墨绿色部分:
LangChain模块是核心模块,是所有开发的基石,是所有开发LLM开发的基本抽象,并且支持链式调用LangGraph是一个中底级别的编排框架,在LangChain基础上用于构造、管理、部署长时间有状态的代理应用IntegrationsLangChain对业务的价值都体现在这,可以快速接入所有主流的大模型以及基础设施层的实现主要是有几个方面: 认可度、持续维度度、易用性、可扩展性、稳定版本、可观性
首先虽然目前的大模型开发一般都有官方提供的SKD,但是接入没有一个标准,开发起来很混乱,会一直不断的重复造轮子。LangChain的出现解决了这个问题,它大而全的接纳了所有大语言开发,做到了真正意思上的统一,通过几行代码就能实现复杂的AI相关的开发。
其次从自身的角度看,再牛X的程序员也要拥抱变化,AI是大势所趋,学习主流的技术才会永远不被淘汰,紧赶世界的步伐才能不断的成长。
也有人唱衰LangChain,说技术变化如此之快的年代,用 LangChain 来构建一切根本行不通,但是我觉得只要一个框架:
如果有任意两个特点就可以学习,然而明显LangChain三个都满足,所以不用担心是否过时过快。
这里更加聚焦于产品的视角,诠释LangChain的核心概念
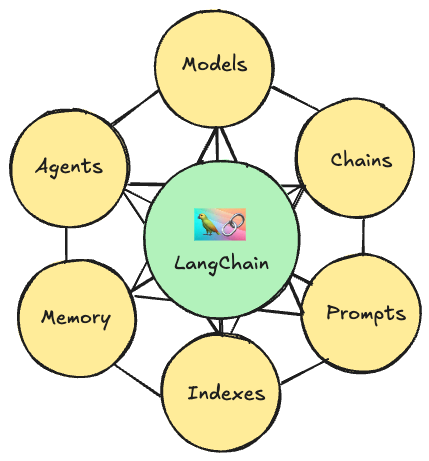
提供了与各种语言模型(如 OpenAI 的 GPT-3、GPT-4, Hugging Face 的模型等)交互的接口。它支持模型的加载、配置和使用,使得开发者可以轻松地将这些模型集成到自己的应用中。
Chains 模块允许开发者构建一系列步骤,这些步骤可以串联起来处理数据。例如,你可以创建一个链,其中包含数据预处理、模型预测、结果解释等步骤。有助于将复杂的任务分解为更小、更易管理的部分
这个模块提供了创建和管理提示(prompts)的工具。提示词是输入到语言模型中的预设文本,通过此模块能快速生成提示词用于初始化聊天上下文。
记忆模块用于在多个请求或对话之间保持上下文。这对于需要持续对话的场景特别有用,例如聊天机器人或虚拟助手。它可以帮助模型记住之前的对话内容,从而提供更加连贯和个性化的响应
Indexes 模块允许开发者将外部数据源(如文档、数据库、知识库等)与 LLM 集成。这通过创建索引来实现,使得 LLM 可以访问并利用这些外部数据源中的信息来生成回答或完成任务
Agents 模块允许创建智能体,这些智能体可以自主地与外部世界交互,并根据需要选择合适的工具或模型来执行任务。智能体可以执行复杂的任务,例如搜索信息、调用外部 API、执行复杂的逻辑决策等。
langchain-core该包包含不同组件的基本抽象以及将它们组合在一起的方法。 核心组件的接口,如大型语言模型、向量存储、检索器等在此定义。 此处未定义任何第三方集成。 依赖项故意保持非常轻量级。
langchain主要的 langchain 包含链、代理和检索策略,这些构成了应用程序的认知架构。 这些不是第三方集成。 这里的所有链、代理和检索策略并不特定于任何一个集成,而是适用于所有集成的通用策略。
此包包含由 LangChain 社区维护的第三方集成。 关键的合作伙伴包, 这包含了各种组件(大型语言模型、向量存储、检索器)的所有集成。 此包中的所有依赖项都是可选的,以保持包尽可能轻量。
使用langchain_core.prompts下的工具包,可以根据模板生成一个提示词,通过管理模板进行复用提示词
1 | |
1 | |
其实可以接入基本上当前市场上的所有主流大模型
1 | |
1 | |
LangChain中引入RunnableSerializable来支持LCEL表达式调用,方便开发,通过chain = prompt | llm | parser 直接调用,解决类回调地狱的问题
1 | |
LangChain的BaseCallbackHandler提供组件调用生命周期的钩子,方便使用者在特定的实际编制入自己的逻辑,比如日志跟踪、事件处理等等
1 | |
因为大模型每次都是新生成会话,所以如果要连贯的跟大模型对话,要带上历史消息,现在最好的实践就是窗口记忆+丢失消息进行摘要
1 | |
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。