At Databricks, we use and build agents extensively, from coding with them at scale to shipping agent products like Genie. But even though the capabilities of agents have gotten much better, working with them feels clunky. As users, we often have 4-5 agents open at once (coding agents, Gemini search, etc) and spend our time copy-pasting text between them and Docs, Slack, and other collaboration tools. And as agent builders, we’re on a treadmill to improve our agents by combining the latest harnesses, SDKs and models. The problem is that LLM capabilities are wrapped into an agent harness, and these harnesses have different interfaces that make combining them or swapping them difficult.
So we built Omnigent: a meta-harness that sits above the agents you already use (Claude Code, Codex, Pi, or custom agents) and makes them interoperable parts of a richer system. Omnigent targets the problems where a single harness stops: it adds easy ways to compose multiple agents, control them with advanced policies, and collaborate live with teammates.
We believe people will soon work with agents through this new layer, the meta-harness. That’s why today we’re open sourcing Omnigent under Apache 2.0.
At Databricks, we adopted coding agents early across our 5000+ member engineering team and built thousands of agents for customers. That experience convinced us that the frontier of agent engineering is moving up a level. The best results no longer come from a single model in a single harness: Harvey beat a frontier model on quality and cost by giving an open-source worker model a frontier advisor it can call, Anthropic built its research product as a lead agent orchestrating parallel subagents, and our own Genie uses different LLMs for planning, search, and code generation. Engineers are changing how they work, too: instead of prompting one agent at a time, they design loops that drive whole teams of agents.
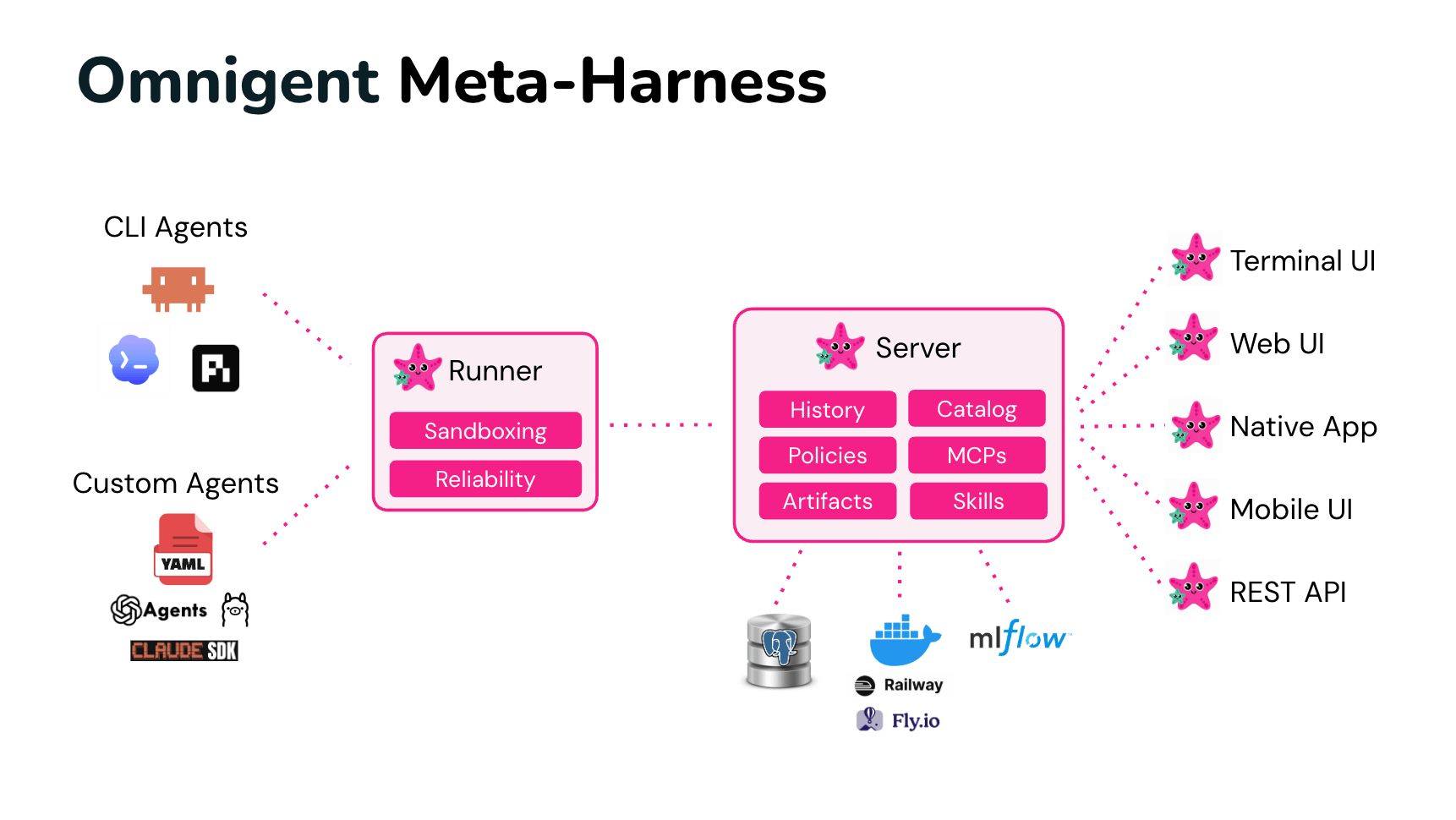
These patterns span multiple harnesses, models, and people, but each harness only understands its own sessions. To combine agents, govern them, and work on them with other people, you need a layer above the harness. Omnigent is that layer, and it provides:
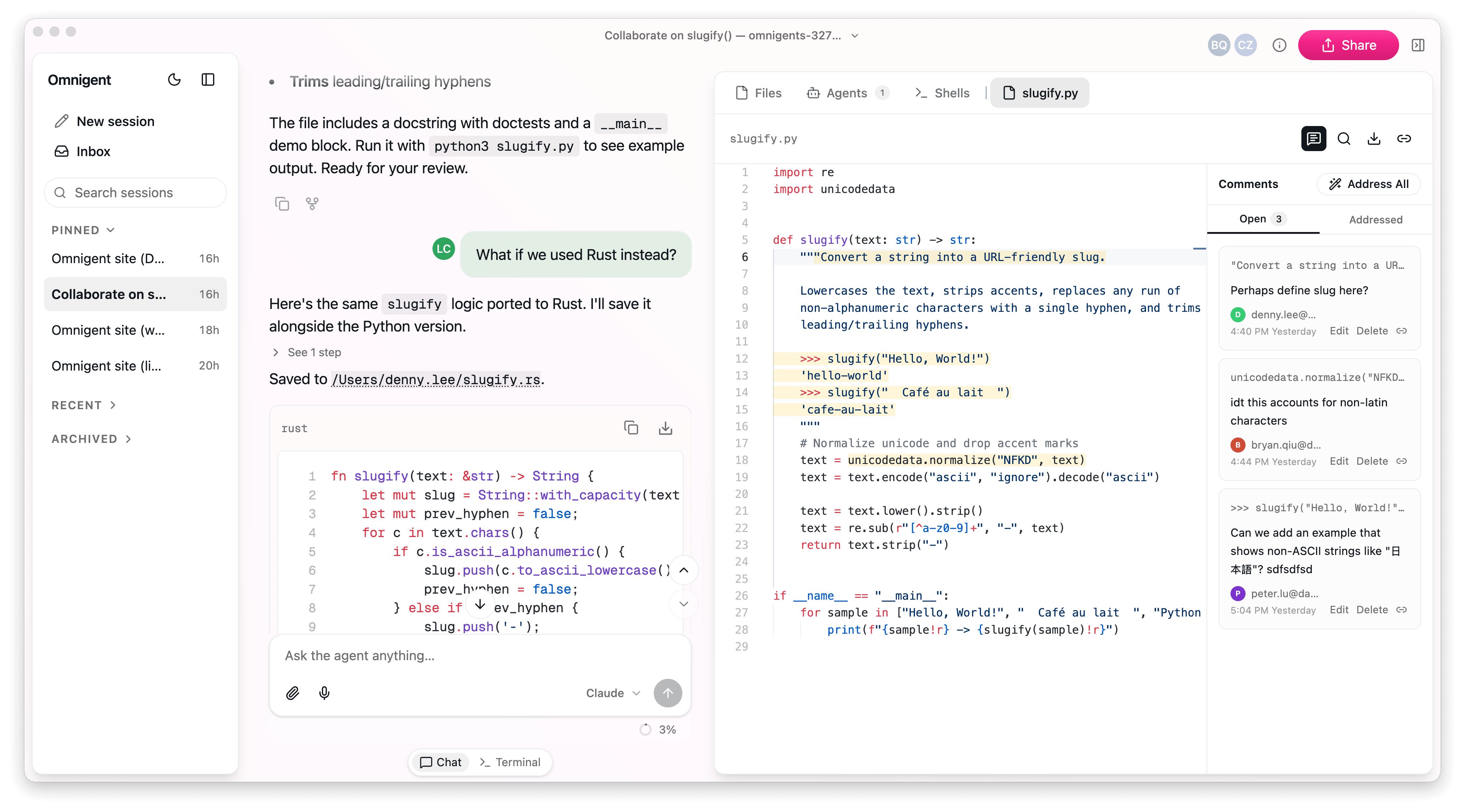
Omnigent introduces a common interface above command-line agents and agent SDKs to let you easily combine and interchange them, and then focuses on the shared problems where a harness stops. The key insight is that however each agent harness calls into its LLM internally, the interface to users is the same: messages and files in, text streams and tool calls out. Thus we built a common API that wraps both terminal-based coding agents (Claude Code, Codex, Pi, etc) and SDKs (OpenAI Agents, Claude Agents SDK, etc).
On top of this interface, the current version of Omnigent adds the following key features:
These features are just scratching the surface of what can be done at the meta-harness layer, however, and we expect to see a lot more ideas soon from our team and the open source community. Some items on our roadmap include automatic optimization at the meta-harness level with GEPA, code-based introspection within agents similar to MemEx and RLM, an Omnigent Server MCP so agents can work across your sessions, and more harnesses. We’ve also made Omnigent easy to deploy on a wide range of infrastructure, including Fly.io, Railway, Modal and Daytona sandboxes, and many LLM providers, and we welcome patches for more integrations.

Many of the biggest shifts in our industry came from moving to a new layer of abstraction: for example, while engineers used to manage individual processes and servers, they can now manage a whole fleet via cloud systems like Kubernetes and Terraform.
We think agents are at the same point today. Each harness is its own silo, with its own context, its own controls, and its own way of running, and none of it carries over when you switch tools. Moreover, many problems intrinsically span harnesses, including composition, security and collaboration. A meta-harness lifts your work above any single harness, so your sessions, policies, and skills stay with you no matter which agent or model is running. The models and harnesses will keep changing as the field evolves; the layer you work at shouldn't have to.
We're building that layer in the open, and we'd love for you to build it with us.
Omnigent is open source in alpha today.
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。