
Security Consultant, Malware Researcher, New Technology Researcher Evangelist.

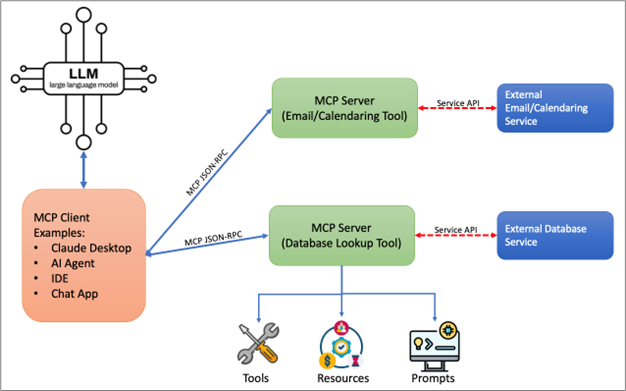
The Model Context Protocol (MCP) is a proposed open standard that provides a two-way connection for AI-LLM applications to interact directly with external data sources. It is developed by Anthropic and aims to simplify AI integrations by reducing the need for custom code for each new system. MCP provides the glue that allows an AI model to interact with external data rather than being isolated or trapped in its own bubble. In this way, MCP servers act as a proxy between an LLM and the external real-world data sources.
MCP is a client-server architecture whereby the AI application acts as a client and MCP servers deliver external service data back to the application. The protocol uses a structured JSON-RPC format to define how AI clients request capabilities and the MCP servers provide capabilities, usually in the form of software functions that can be executed.
An example use case might be vacation or trip planning. There might be one or more MCP servers dedicated to working with your calendar, email, and perhaps even performing hotel and flight booking. The AI can make client requests of these various servers based on their advertised capability during the trip planning process.
Anthropic has a dedicated repository with software development kits for multiple languages which you can find here at https://github.com/modelcontextprotocol. Language support is extensive including Typescript, Java, Python, C#, PHP, Ruby, Golang, Rust and more. Extensive documentation about MCP is published here at https://modelcontextprotocol.io.
MCP servers provide functionality through three primary building blocks.
Unfortunately, MCP was designed with functionality front of mind without addressing information security at all. Being a very open and easy-to-use specification leaves implementations vulnerable to multiple risks and attack vectors. Furthermore, it is common knowledge that developers are under pressure to enable business functionality, with security measures often taking a back seat.
It is critically important that we keep the context of these technologies in mind. AI-LLMs are by nature a probabilistic technology. The transformer generative decoder architecture produces a probabilistic distribution for next token (often “next word”) prediction but will not typically produce the same result given the same repeated prompting.
In the MCP context, we are connecting a probabilistic generative language technology to deterministic tools to take direct actions. There is already a degree of unpredictability introduced, even before the LLM makes choices as to what MCP tool to use, and what parameters to supply.
The next challenge with MCP is that trust is typically assumed but not enforced. Due to the unpredictability of the input, it is even more critical that MCP servers be implemented with strict security controls. MCP is a trust boundary because MCP directly allows AI models to:
This entire mix of capability leads to multiple potential avenues of attack.
Some possible attack scenarios and impacts include things like:
MCP servers are likely going to have items like OAuth tokens, API keys, and/or other service credentials to enable access to upstream services. This could be anything from Google account credentials, Slack credentials, or cloud storage credentials for example. It is not unusual to see developers hard code credentials directly into scripts, and/or AI prompt templates risking exposure.
MCP servers are often implemented to blindly execute an action without checking input leading to successful O/S command injection, SQL injection, and execution of any other input against any third-party API that the MCP server is leveraging. Making this worse, it is entirely feasible that the AI-LLM is fetching its prompt from something like a helpdesk ticketing system leading to a situation not dissimilar in nature from stored Cross Site Scripting (XSS). In this sort of scenario, one description is “stored prompt injection” although the ramifications go far before the prompt itself that is stored.
MCP tools by design need access to external data sources, however, there are no specific role-based access controls defined in the standard. This leaves access controls in the hands of the developer. It is not unusual to find that overprivileged tokens are used for service access, or that no controls are implemented around an operating system command execution.
Many of the tools being written today are based upon the example/reference code from Anthropic’s GitHub repository. These examples are not production-ready code. It is the responsibility of tool designers and developers to ensure that logging controls are implemented in all MCP tools. Any actions taken by the LLM in querying and controlling an MCP tool should be clearly logged, making sure that careful choices are made to avoid logging sensitive data.
Through prompting, it is feasible that an MCP tool continuously loops and consumes resources of a third-party service in the process. If there are no billing quotas and/or rate limits imposed in the implementation, this will lead to excessive usage and the associated billing with that third-party service.
Many tool implementations are written to interact with calendaring and email solutions as these are attractive services to integrate in a workflow. It is not unusual for there to exist multiple different MCP tool resources in a sort of ecosystem. Thus, it is not hard to imagine a scenario whereby sensitive data is sourced from one tool that perhaps does database lookups, and then exfiltrated via an MCP email service tool, for example.
When developing an internal MCP tool, consider the following guidelines.
There is a growing ecosystem of tools and community driven projects for assisting in MCP risk mitigation. Here are some examples.
MCPSafetyScanner is an open-source tool by the AI Assurance Lab (https://github.com/johnhalloran321/mcpSafetyScanner) that simulates attacker behavior against MCP tool manifests. This tool does the following:
MCP Guardian is a security and governance layer that provides visibility and control over how LLMs interact with external tools. It can enforce:
MCP Guardian aims to ensure that all MCP tool invocations meet your security policy criteria before execution. In essence, it is a proxy between your MCP clients and the implemented MCP tools/servers.
MCP-Scan by Invariant Labs does both static code scanning and runtime proxy enforcement. The static analysis functionality works for local MCP configurations for clients like Claude, Cursor and Windsurf. This can identify prompt injection risks, tool poisoning attacks, and “rug pull” manipulation via hash mismatch or manifest change. The runtime proxy has PII detection, custom rules, secrets blocking, and tool usage policy protection.
Naturally performing code analysis and implementing runtime proxy-style protections are a good thing, but ultimately authorization controls are required to properly define trust boundaries. The MCP Authorization specification provides a structured method to provide OAuth2-based access control for tool invocation. This helps enforce least privileges, user specific scopes, and multi-tenant separation. Some features are as follows:
Bottom line is that the authorization specification allows you to enforce principles of least privilege.
This is just a brief view of Model Context Protocol and the related challenges. As with all things in the world of AI, at present, we are sure to see rapid change and evolution as adoption continues. As cyber security practitioners, let’s hope that significantly more attention is paid to security and risk mitigation as this aspect of the AI ecosystem evolves further.
Want to keep learning from Joff? Register now for next week’s webcast taking place Thursday, 10/30, at 1:00 PM EDT:
AI Agents and MCP Security Risks

此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。