Mistral AI released two notable open models in early December: Mistral Large 3, announced on December 2, and Devstral 2, released on December 9. Mistral Large 3 is a frontier-class mixture-of-experts model with 41 billion active parameters out of 675 billion total, designed for strong general reasoning and long-context workloads. Devstral 2 is a developer-focused open model optimized for coding, tool use, and agent workflows, offering a more targeted option for teams building production systems. Both models are released under the Apache 2.0 license, allowing developers to run, fine-tune, and deploy them directly on their own GPU infrastructure.
Nvidia announced the Nemotron 3 family of open source models, marking a notable shift toward releasing open weights alongside its hardware and software stack. The Nemotron models target a range of use cases, from lightweight agent workflows to more capable general-purpose reasoning tasks, and are designed to run efficiently on Nvidia GPUs.
Nemotron 3 Nano 30B beat GPT-OSS and Qwen3-30B and runs 2.2–3.3× faster:
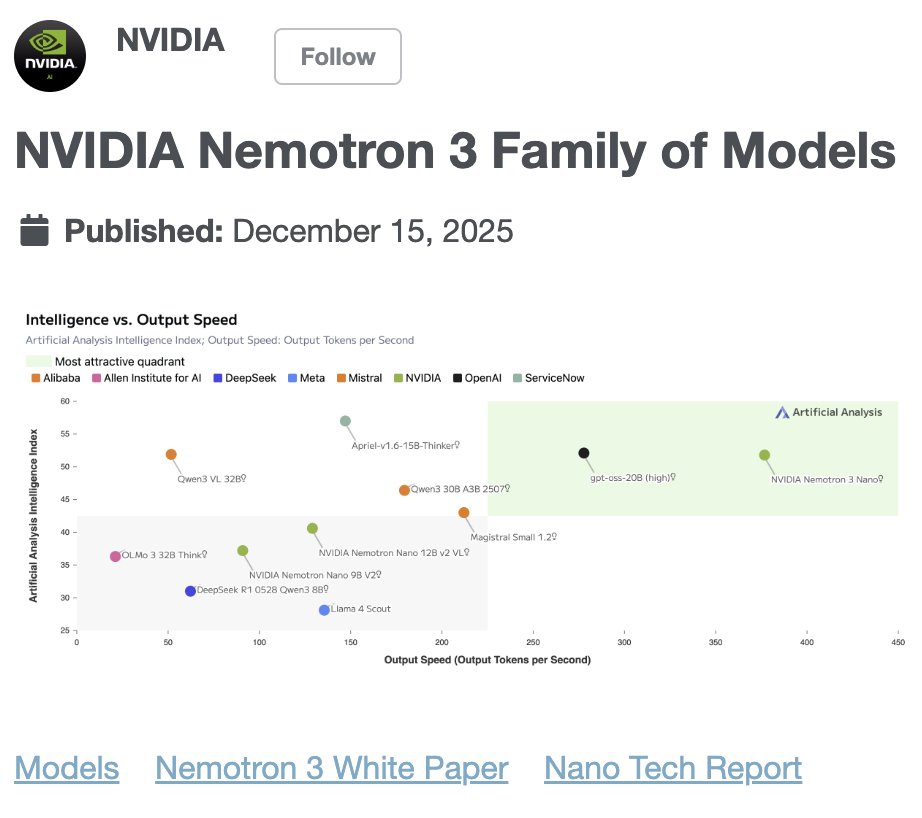
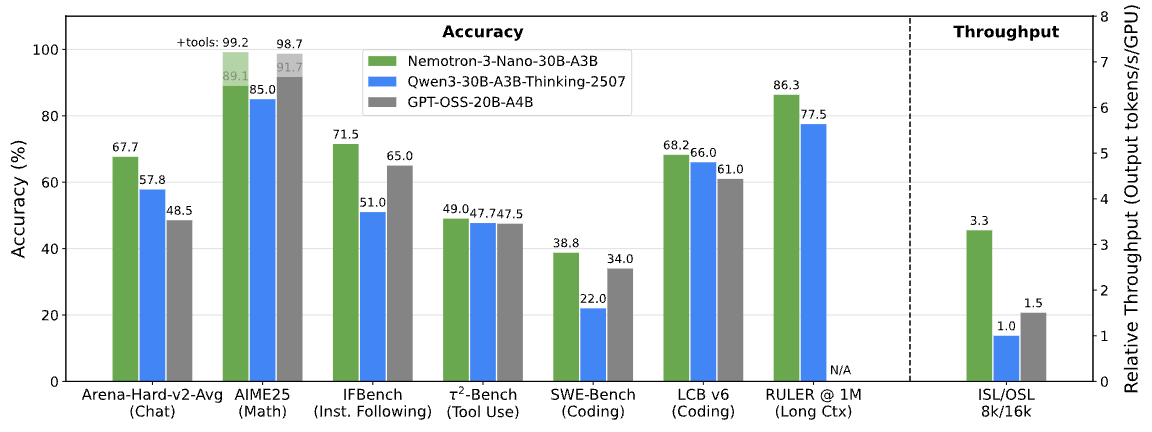
In parallel, Nvidia introduced new tooling aimed at making customization and fine-tuning easier across RTX, DGX, and data center environments. These tools focus on reducing friction for teams that want to adapt open models for specific domains or workloads.
Nvidia also announced its acquisition of SchedMD, the primary company behind the open source Slurm scheduler. Slurm remains one of the most widely used workload managers for HPC and AI clusters, and continued investment strengthens a critical part of the open infrastructure stack used for large-scale training and distributed inference.
Together, these moves signal Nvidia’s growing role not just as a GPU provider, but as a long-term steward of open source infrastructure that underpins modern AI systems.
The appeal of open models is simple. You can run them, test them, and decide if they are worth keeping. That only works if your infrastructure lets you move quickly and change your mind.
This is the kind of work Pods and Clusters are designed for. They make it easy to benchmark new models, compare setups, and scale experiments without committing to a fixed stack or long-term assumptions.
Early December highlighted a clear shift toward open models and open infrastructure. Frontier-class open releases, combined with deeper investment in scheduling and GPU tooling, are making it easier for teams to build powerful AI systems without relying exclusively on closed platforms.
For developers who care about performance, cost control, and transparency, this momentum creates real opportunity. Open models and open infrastructure are no longer niche. They are becoming a core part of how modern AI systems are built and deployed.
Sources:
Mistral AI – Introducing Mistral 3 | https://mistral.ai/news/mistral-3
NVIDIA Newsroom – NVIDIA debuts Nemotron 3 family of open models | https://nvidianews.nvidia.com/news/nvidia-debuts-nemotron-3-family-of-open-models
NVIDIA Research – NVIDIA Nemotron 3 family of models | https://research.nvidia.com/labs/nemotron/Nemotron-3/
NVIDIA Blog – NVIDIA acquires open-source workload management provider SchedMD | https://blogs.nvidia.com/blog/nvidia-acquires-schedmd/
Reuters – Nvidia buys AI software provider SchedMD to expand open-source AI push | https://www.reuters.com/business/nvidia-buys-ai-software-provider-schedmd-expand-open-source-ai-push-2025-12-15/
Author profile: Emmett Fear
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。