LLM在推理时,竟是通过一种「程序性知识」,而非照搬答案?可以认为这是一种变相的证明:LLM的确具备某种推理能力。然而存在争议的是,这项研究只能提供证据,而非证明。
LLM,究竟会不会推理?
就在刚刚,UCL、Cohere等机构的研究人员发现:在LLM执行推理任务时,竟存在着一种「程序性知识」。

论文地址:https://arxiv.org/abs/2411.12580
这项工作已经登上了Hacker News的热榜。

跟很多人想象的不同,LLM在推理时,并不是使用简单的检索。
真相是,LLM在推理任务中进行泛化时,依赖的是文档中的「程序性知识」,使用可概括的策略,来综合推理任务的解决方案。
研究发现,在涉及「世界上最长的河流」、「人体最常见的元素」这类问题时,模型所依赖的数据集并不相同。

然而一旦涉及到数学题这类推理问题,LLM却使用了某种策略,从文档中综合出了一种「程序性知识」。

推理集中的示例,关于「求解线性方程中的x」有人表示,既然LLM不可能在训练数据中找到每一个问题的例子,那就可以认为,LLM已经在进行某种形式的推断,以创造出对所提问题的解决方案。

更有趣的是,此前苹果的研究者曾在一篇论文中发现,GPT-4o、o1、Llama、Phi、Gemma和Mistral等模型,都未被发现任何形式推理的证据,而更像是复杂的模式匹配器。
只要给数学题换个皮,对无关紧要的信息进行修改,LLM就不会做了。
而UCL这项工作的结果,并未和苹果的这篇论文发生矛盾。

有人根据这项研究的结果,做出这样的总结:LLM不适合推理,但非常适合充当一种「编译器」层,弥合自然语言和SQ、prolog、python、lean等形式语言的差距。再对形式语言层的结果和输出进行综合,这基本上就是智能体了。

有网友分析表示,这个过程并不是「学习如何解决问题」的泛化,而是更具体的:「神经网络被训练去模仿人类在解决特定问题时展示的逐步过程」。
也就是说,LLM是通过观察人类程序化解决问题的示例,从而复制类似的推理。

另外还有一些网友更加犀利:「大多数人活了几十年都搞不懂该如何正确地推理,并且经常陷入逻辑谬误当中;现在竟然觉得自己可以评判LLM是不是具有推理能力了?」

长久以来,LLM的能力和局限性,令人着迷却又矛盾。
一方面,LLM解决一般问题的能力十分惊艳。可另一方面,跟人类相比,它们表现出的推理缺陷又令人啼笑皆非,因此让人怀疑:它们的泛化策略是否具有稳健性?
为了探讨LLM究竟采用何种泛化策略,研究人员对LLM在执行推理任务时依赖的预训练数据进行了研究。
在两种不同规模的模型(7B和35B)及其25亿预训练token中,研究人员识别出哪些文档对三种简单数学推理任务的模型输出产生了影响,并将其与回答事实性问题时具有影响力的数据进行了对比。
就是在这个过程中,他们发现了「程序性知识」的存在!
具体来说,虽然模型在回答每个事实性问题时依赖的数据集大多是不同的,但在同一任务中的不同推理问题上,一个文档确往往表现出了类似的影响力。

事实控制集的示例,类似于7B事实查询集中关于「世界上最高的山」的问题,但不需要任何事实回忆
另外他们还发现,对于事实性问题,答案通常出现在最具影响力的数据中。
然而,对于推理问题,答案通常不会出现在高度影响力的数据中,中间推理步骤的答案亦是如此。
原因为何?果然,还是和「程序性知识」有关。
对此,研究人员对推理问题的高排名文档进行了定性分析后,确认了这些具有影响力的文档的确通常都是包含程序性知识的,比如展示了如何使用公式或代码求解的过程。
总之,模型在推理时并不是简单检索,而更像是使用一种可泛化的策略,即从进行类似推理的文档中综合程序性知识。

推理控制集的示例,表明上类似于斜率查询,但不需要任何推理
LLM在推理中,是否真正理解了问题呢?
许多研究一致发现:LLM的能力,严重依赖于训练数据中类似问题的频率。
这就牵出了「数据污染」的问题:基准数据往往会出现在预训练数据集中。
在机器学习中,可以将测试数据与训练数据分离来衡量泛化能力,但当前先进模型设计中使用的数万亿token,已经已无法合理地与基准测试数据完全分离了。
许多研究都表明,相当多常见的基准测试,都含有大量污染数据。即使是经改写的基准数据,也可能会规避基于N-gram的检测方法,对性能产生影响。
LLM究竟是在何种情况下,依赖污染数据进行推理的呢?
这个问题,又引发出了另一个核心问题——LLM是如何从预训练数据中学习推理的?
因此,在这项研究中,研究人员们重点专注的是语言模型用于泛化的预训练数据,而非直接解释模型的权重。

推理集中的示例,涉及计算穿过两点直线的斜率
哪些数据会影响模式生成的推理过程?这些数据如何与所解决的具体问题相关?
模型是否仅仅从已见过的预训练数据中「提取」答案并重新整合,还是在泛化中采用了一种更为稳健的策略?
为此,研究人员们借助了一种来自鲁棒统计学的方法,让它适配于大规模Transformer,以计算预训练文档对训练模型中提示词-完成对(prompt-completions pairs)概率的影响。
可以猜测,在极端情况下,回答推理问题的语言模型可能严重依赖于从预训练数据的特定文档中检索的参数化知识。这些文档包含所需检索的信息(即推理轨迹),对模型的输出贡献显著,相比之下,许多其他文档的作用则微乎其微。
相反,在另一种极端情况下,模型可能从与问题更抽象相关的广泛文档中汲取信息,每份文档对许多不同问题都会产生类似影响,但对最终输出的贡献相对较小。而泛化能力更强的推理应更类似于后一种策略。
事实是不是如此呢?
他们研究了对一组事实性问题和推理问题(称为「查询」)具有影响力的预训练数据(称为「文档」)。
推理问题涵盖三种数学任务:两步算术、斜率计算和线性方程求解。
这些任务代表了逐步推理不同层次的挑战,而事实性问题则需要从参数化知识中检索答案。
对两种LLM(7B和35B)及其25亿预训练token进行实验后,他们的发现如下——
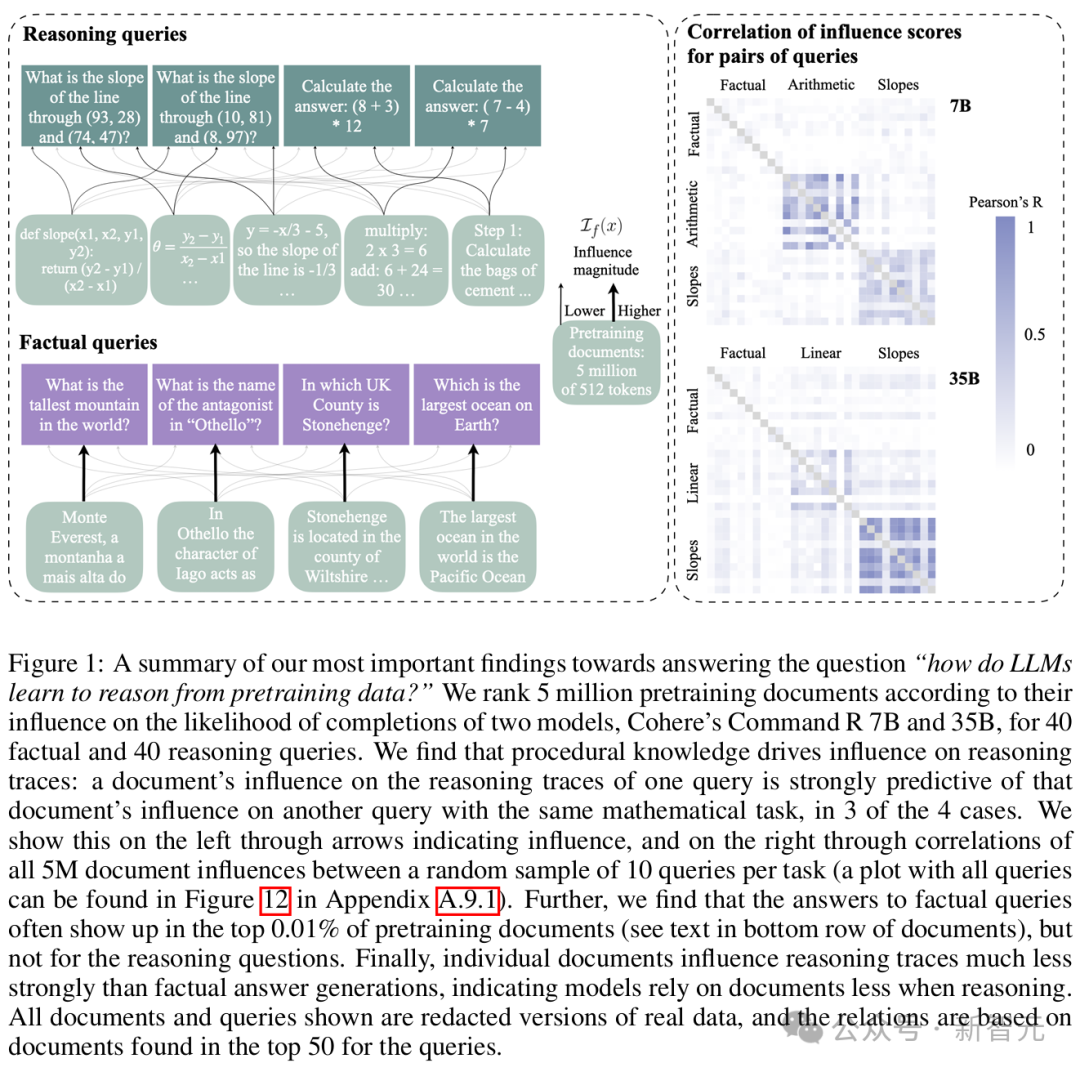
1. 文档中的程序性知识,驱动了对推理过程轨迹的影响
一个文档对某个查询推理过程轨迹的影响力,可以强烈预测该文档对相同数学任务的另一个查询的影响力。
相比之下,这种现象在事实性查询中却并不成立。
这表明,对于需要将相同程序应用于不同数字的问题,文档通常具有类似的贡献。
在斜率计算的查询中,这种相关性尤其显著。在排名前0.002%的预训练数据中,多次发现了包含代码或数学解题程序的文档。
2. 在推理问题上,模型对单个文档的依赖程度较低,且依赖的文档集合更为广泛
研究人员还发现,对于模型生成的每单位查询信息,文档的影响力在推理问题上通常比事实性问题低得多。
此外,文档集合的整体影响力波动性较小。
前者可以表明,在生成推理过程轨迹时,模型对每个单独文档的依赖程度低于事实性检索。
而后者表明,对于一个随机的25亿预训练token子集,是否包含高度影响力的文档对事实性问题的影响更具偶然性,而对推理问题则更为稳定。
总之,这就表明,模型在推理问题上更倾向于从更广泛的文档集合中泛化,而对单个文档的依赖较少。
3. 对于事实性问题,答案通常出现在高度影响力的文档中,而推理问题则不然
查看每个查询中排名前500(排名前0.01%)的影响力文档后,研究人员发现,事实性问题的答案相对较常出现(7B 模型中占55%的查询,35B模型中占30%)。
而在推理问题中,则几乎没有,即使他们确实在更大的25亿token数据集中找到了答案。
4. 代码对于数学推理非常重要
在推理查询的正负影响力排名的顶端部分,与训练分布相比,代码数据的比例明显过高。
这个研究结果表明,推理的泛化策略,不同于从预训练期间形成的参数化知识中进行检索。
相反,模型的学习,是从涉及类似推理过程的文档中提取程序性知识,无论是以程序的一般描述形式,还是以类似程序的应用形式。
这个发现告诉我们:或许我们并不需要在预训练数据中涵盖所有可能的情况。
相反,专注于展示跨多样推理任务的程序性高质量数据可能更为有效,因为这有助于降低预训练数据的冗余性。
而代码在所有任务中发挥的重要作用,也引发了一个有趣的问题:是否存在某种预训练数据类型(例如代码),能帮助模型(尤其是更大的模型),来学习多个任务?
如果能深入理解程序性泛化的范围,我们未来的预训练策略就会得到更多的指导,还能在数据选择中确定重点。
文档对补全的影响影响函数给定一个预训练模型θ^u,该模型参数化了一个基于提示词
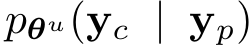
的下一个token的分布。
其中,y_c = {y_1, …, y_m} 是补全,y_p = {y_1, …, y_n} 是提示词,u表示参数未必训练到收敛,研究人员希望找到来自预训练数据集
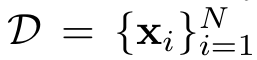
中对补全产生影响的数据。
也就是说,研究人员想知道,预训练数据集中哪些样本「导致」了一个补全。
为此,他们使用了针对大规模Transformer的EK-FAC影响函数。
参数 θ^u通常通过对目标函数执行基于梯度的迭代算法,并根据某些标准停止来获得。
研究人员希望了解训练文档x_j∈D对参数θ^u的影响(通过链式法则,也可重新表述为「对θ^u的任何连续可微函数的影响」)。
研究人员希望,可以通过从原始训练集中移除x_j,重新训练模型,并将结果参数集(或其函数)与原始训练模型进行比较,从而精确计算影响。
然而,对于任何有意义数量的文档和参数来说,这种方法都是不可行的。
为此,他们利用影响函数通过对响应函数进行泰勒展开,来估计这种反事实:
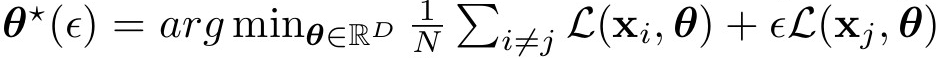
其中 L(·) 是一个损失函数,例如交叉熵损失。
响应函数在ε=0附近的一阶泰勒近似,用于推导当ε改变时最优参数如何变化,而ε的变化会改变想要分析的文档的权重。
通过隐函数定理,影响定义为:
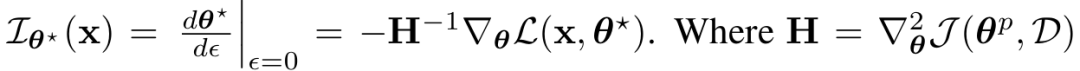
其中
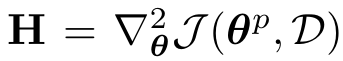
是预训练目标的Hessian矩阵。
通过链式法则,可以通过近似以下公式,来估计给定提示词时训练文档x = {x1, …, xk} 对补全的影响:
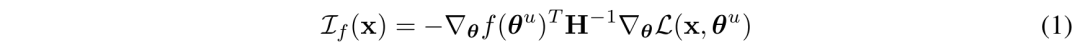
由于研究的是数十亿参数D的模型,上述Hessian是不可计算的,因此,研究人员使用EK-FAC估计法来进行估算。
它涉及估算两个期望值
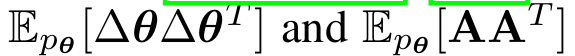
其中A表示模型的激活。
为了使这种估算可行,研究人员在所有估算中做出了一些简化假设,例如假设层与层之间相互独立,并且只考虑 Transformer层的MLP参数。

近似假设列表
先前的研究表明,与其他类型的影响函数相比,EK-FAC影响函数能够更准确地估算由响应函数给出的反事实。
然而,除了对语言模型补全的影响,研究人员还关注对训练语言模型在回答问题时准确性的影响。
因为目前尚无研究表明,影响函数可以估算由下一词预测生成文本的底层准确性的影响,因此只能计算对连续可微函数的影响。
因此,研究人员选择交叉熵损失函数(公式1中的f)作为连续可微函数。
通过这种方式计算出的影响,可以揭示对7B模型在推理和阅读理解任务中准确性具有因果影响的文档。
具体来说,如果根据文档的影响从微调数据中移除文档并重新训练模型,其准确性下降的幅度显著高于随机移除相同数量的文档,或者使用梯度相似性移除相同数量的文档。
同时,可以通过展示EK-FAC对Hessian的估算显著优于仅使用一阶信息的方法,来论证使用EK-FAC估算的合理性。
由于只能对预训练数据样本进行一次循环,并且只能在内存中存储一个查询梯度(其内存复杂度与模型本身相同),研究人员使用了奇异值分解(SVD)。
由于他们采用了一种基于概率算法的近似SVD,这显著加快了查询梯度的计算速度。
通过近似公式1来为预训练数据D中的文档计算得分,这些得分代表了它们在给定提示词y_p时对补全y_c的影响。
在由响应函数近似的反事实问题中,影响得分为1,表示序列y_c的对数概率增加了1。
为了比较不同补全(和token长度)的影响得分,研究人员通过补全y_c的信息量对查询得分进行归一化,信息量以nat为单位衡量。
根据影响得分,他们对文档进行了从正到负的排名,其中得分可以解释为每nat查询信息增加(或减少)的对数概率。
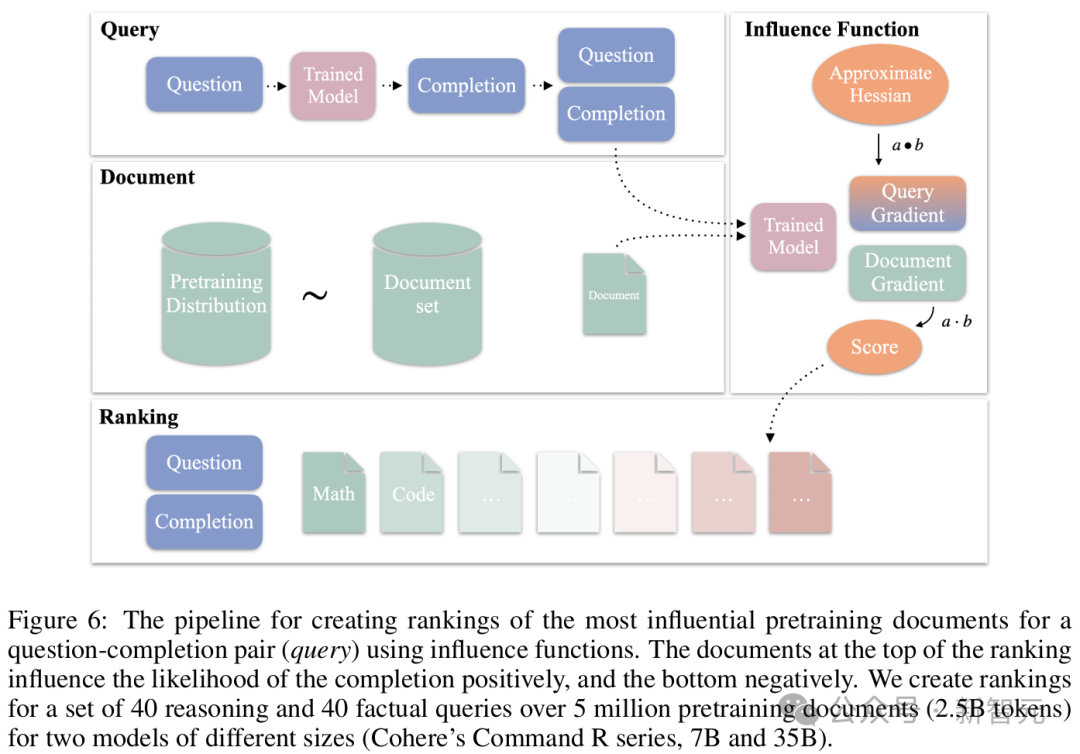
实验阶段,研究人员比较了通过影响函数对推理问题生成的预训练数据排名顺序(从最正面影响到最负面影响)与事实性问题排名顺序的差异(事实性问题只能通过检索参数化知识来回答)。
发现 1:对于底层推理任务相同的查询,其文档影响评分之间存在显著的正相关性。
这表明,这些文档对需要相同程序但应用于不同数字的问题具有相关性。
如果模型依赖于包含「通用」知识的文档,而这些知识适用于同一任务的所有查询,那么可以预期,这些查询对应的文档影响评分之间会呈现显著的相关性。
研究人员通过计算所有500万个文档在所有查询组合中的Pearson相关系数发现,对于相同类型推理任务的许多查询之间,文档评分存在显著的正相关性;而对于大多数事实性查询或不同类型推理查询的组合,这种相关性则显著缺失。这一现象表明,许多文档对同类型推理问题具有类似的影响。
考虑到每种类型的推理查询都需要将相同的程序应用于不同的数字,正相关性进一步说明,推理查询的文档影响评分能够捕捉到程序性知识。
随后,研究人员通过使用一组对照查询(看起来相似,但不需要任何推理)并重复整个实验,否定了「推理问题之间的相关性仅由表面相似性导致」的假设(大多未观察到相关性)。
此外,研究人员还通过不同查询集之间高相关性或低相关性的具体示例,进一步验证了程序性知识的作用——部分相关性由推理步骤的格式决定,而大部分则由推理程序本身决定。

发现 2:与回答事实性问题相比,模型在进行推理任务时,平均每生成一个单位信息(nat)所依赖的单个文档程度较低,同时总影响的波动性也更小。
这表明模型倾向于从更广泛且更通用的一组文档中进行泛化。这一现象在更大的模型中表现得尤为明显。
具体来说,研究人员从两个模型中观察到以下两点:
1. 首先,对于大多数事实性问题,在排名的任何部分,总影响均高于推理问题。这表明,事实性问题对文档的依赖更为集中。
2. 其次,在不同的事实性查询中,相同排名位置的文档影响力变化更大。而对于少数事实性查询,其总影响实际上低于推理查询。
第一个结果表明,平均而言,模型在生成推理过程轨迹时,对单个文档的依赖程度低于回答事实性问题。
第二个结果表明,对于事实性问题,模型更依赖于「特定的」且不常见的文档。换言之,对于一个事实性问题,预训练样本中是否包含相对高影响力的文档更依赖于偶然性
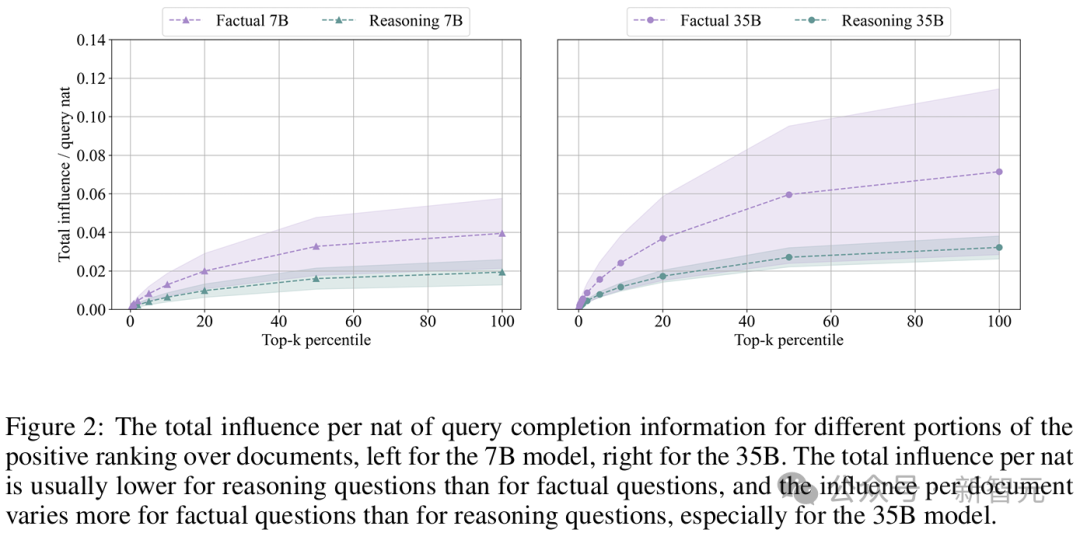
分析影响大小的另一种方法是观察排名中影响的分布。
结果显示,文档排名的顶部遵循幂律分布,其特征是在对数-对数空间中,排名与每单位信息增量(nat)的影响之间呈线性关系。
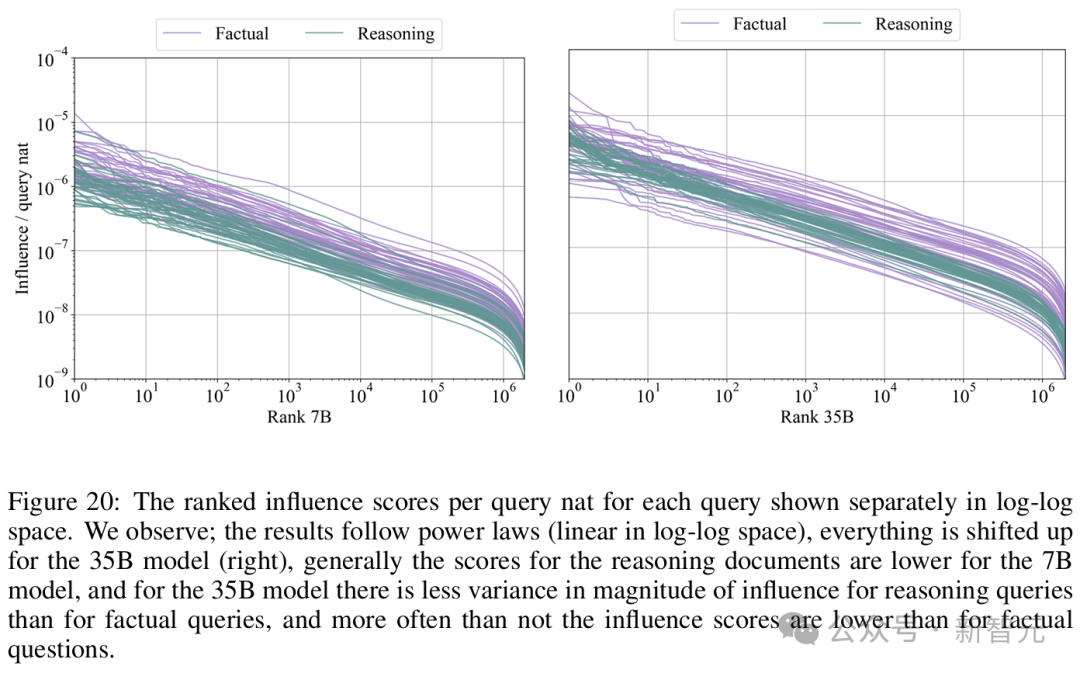
其中,对于35B模型的推理问题,其斜率比事实性问题略陡。
这意味着,在35B模型的推理问题中,排名顶部所包含的正面影响百分比,增长得比事实性问题更快。
也就是说,推理问题的影响更集中于排名前列。
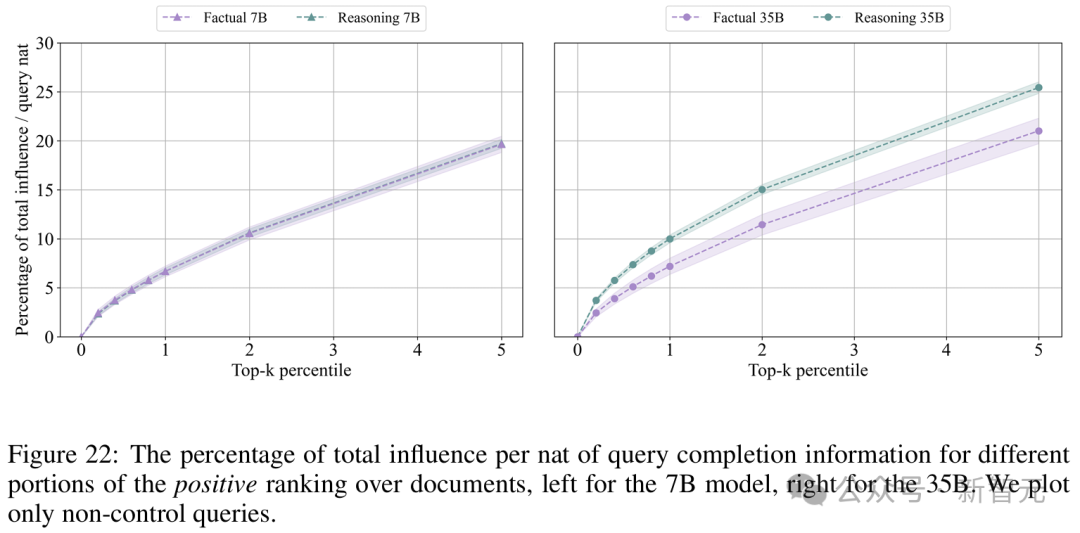
对于7B模型,模型正确回答推理问题的斜率平均也比事实性问题略陡,但当比较所有事实性问题和推理问题的斜率时,这种效果消失了。
这表明,对于35B模型,排名顶部序列所覆盖的总正面影响百分比在推理问题中高于事实性问题。
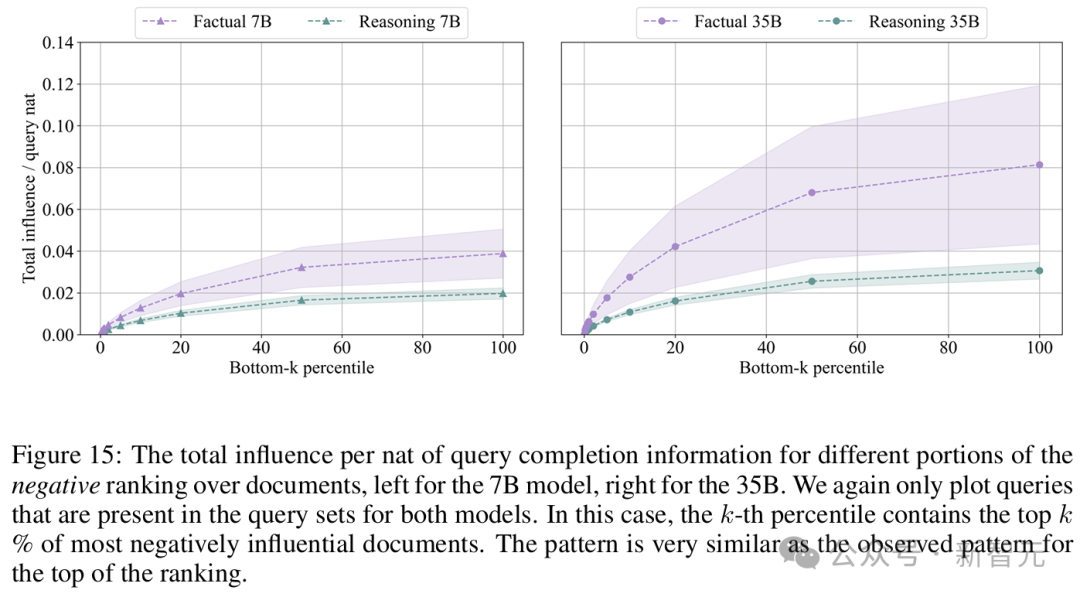
如果比较模型之间的结果,35B模型在整个排名中的影响和波动性差异更为显著。
即使仅对两个模型相同的查询进行比较,这种效果依然存在,这表明较大模型的数据效率更高。
除了定量分析之外,研究人员还对每个查询的排名顶部进行了三项定性分析:
首先,搜索答案;
其次,分析文档与推理查询之间的关系;
最后,调查这些文档来源于哪些数据集。
为了过滤掉一些无关信息,研究人员将影响分数除以文档梯度范数并重新排序。
发现 3:对于事实性问题,答案相对较频繁地出现在最具影响力的文档中,而对于推理问题,几乎不会出现。
为了在排名靠前的文档中手动找到查询问题的答案,研究人员为每个查询构建了一组关键词。如果答案存在于文档中,这些关键词应当出现在文档中。
例如,对于事实性查询,关键词包括「tallest」、「highest」、「Mount Everest」(珠穆朗玛峰)、「29029」和「8848」。而对于推理查询,则为每个查询构建了更多的关键词,如「7−4」、「3」、「21」、「3∗7」,以及将操作替换为诸如「minus」(减)和「times」(乘)等单词。


此外,研究人员为Command R+模型设计了一套提示词,用于在查询-文档对中寻找答案,并利用它在每个查询的前500个文档中搜索答案,而不依赖关键词重叠。
然后,手动检查这些命中,并记录包含查询答案的文档。(Command R+不仅找到了所有手动识别出的答案,并且还发现了更多答案。)

最后,将关键词重叠搜索与Command R+提示词相结合,应用于2.5B预训练token的子集,以验证答案是否存在于整个数据集中,而不只是前500个文档。
结果显示,对于7B模型,可以在前500个文档中找到55%的事实性查询的答案,而推理查询仅有7.4%找到了答案。
对于35B模型,事实性查询的答案在最具影响力的文档中出现的概率为30%,而推理集合中则完全没有答案。
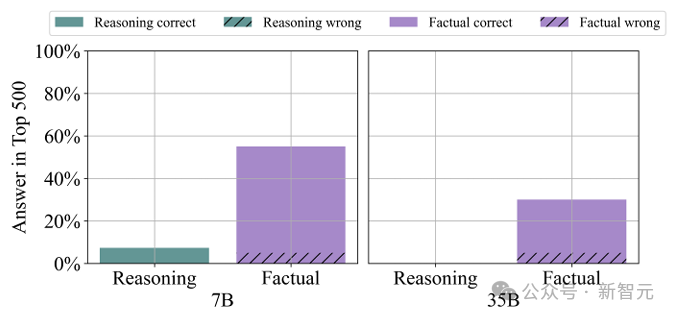

有趣的是,事实性问题的答案经常以不同的语言出现,例如西班牙语或葡萄牙语。
为了证伪「推理问题的答案未出现是因为它们不存在于500万个文档集合中」这一假设,研究人员在500万文档的随机子集中重复了上述关键词搜索。
在20个算术查询中,在未出现在前500个文档中的文档中识别出了13个推理步骤的答案,以及1个完整答案,并预计还存在更多未被关键词搜索捕捉到的答案。
对于斜率和线性方程查询,找到了3个未出现在前0.01%文档中的推理步骤答案。

发现 4:对于推理查询,具有影响力的文档通常也在进行类似的逐步推理,例如算术推理。此外,这些文档通常通过代码或数学方法实现了推理问题的解决方案。
对于斜率查询,许多高影响力文档展示了如何通过代码或数学计算两点之间的斜率。
对于7B模型,在20个查询中的16个查询中出现在前100个文档中(共出现38次);而对于35B模型,这类文档在所有查询中都出现了(共出现51次)。
此外,研究人员还手动找到了7个通过代码实现斜率计算的文档,以及13个展示斜率计算公式的文档。7B模型依赖于其中的18个文档,而35B模型依赖于其中的8个。
以下是一个通过JavaScript(左)和数学公式(右)实现解决方案的高影响力文档的示例:

随后,研究人员提示Command R+对每个查询的前500个文档进行更详细的特征化分析。
结果显示,这些文档中通常涉及对其他数字进行类似的算术操作(如更大或更小的数字)、对相似数字进行类似的算术操作(如斜率问题),或对相似数字进行类似的代数操作(如求解线性方程)。
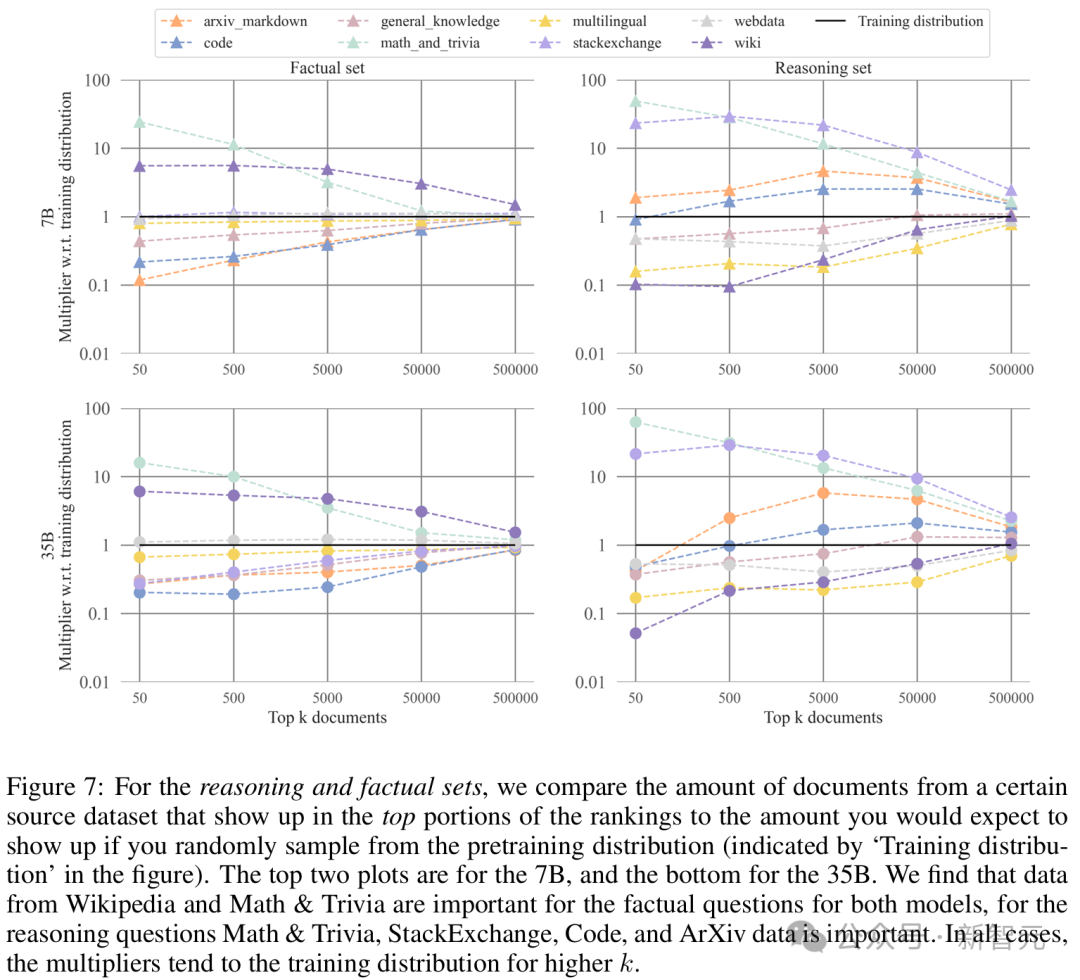
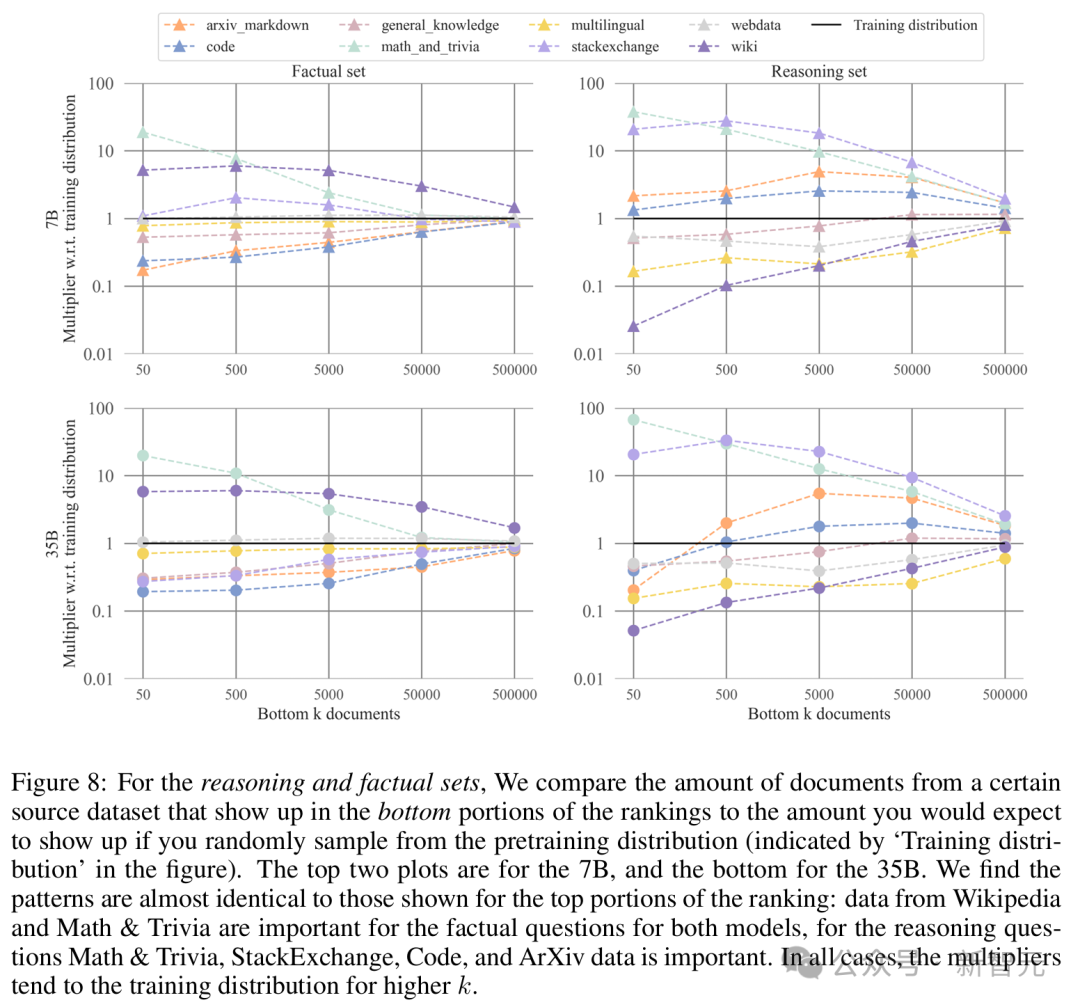
发现 5:对于事实性查询,最具影响力的数据来源包括Wikipedia和trivia,而对于推理查询,主要来源包括数学、StackExchange、arXiv和代码。
研究人员分析了代表最具影响力文档的源数据集的类型,并将该计数与预训练分布进行了比较。
作为数据来源的StackExchange,在排名顶部的数据中,其影响力是从预训练分布中随机采样时的十倍。其他代码来源在从k=50到k=50000的范围内,其影响力是随机采样时的两倍。
类似的模式也适用于排名底部的数据。
研究者也承认,方法存在重要的局限性。
最显著的一点就是,没有计算整个训练集的影响,因为这在计算上是不可行的。
因此,研究结果可能存在另一种解释,会让人得出相反的结论:模型在推理时依赖的数据如此稀疏,以至于在随机抽取的25亿token中,任何一个推理查询都未能浮现出相对高影响力的样本。
这是否意味着,LLM在推理时会依赖稀疏和罕见的文档呢?
也就是说,他们实际上是在研究一组对推理相对无影响的文档,而如果观察整个预训练数据,推理路径的答案可能会非常具有影响力。
然而,研究者认为这种解释不太可能,原因有三。
第一,定性分析表明,推理问题的高影响数据直观上高度相关,并且许多推理路径的答案是25亿token的一部分,只是对推理的影响力不高;第二,不同推理任务的影响分数之间的相关性显著;第三,可以确认这些结果不适用于表面上与推理查询相似但不需要逐步推理的对照查询。
此外,模型从如此稀少的数据中,学习一种最简单形式的数学推理(即对小数字的减法和乘法),可能性也极小。
另一个局限,就是没有研究监督微调阶段。
综上所述,可以认为,结果表明了一种依赖程序性知识的泛化策略。
尽管如此,对于这类可解释性研究的本质是,他们也只能提供证据,而非证明。
参考资料:
https://arxiv.org/abs/2411.12580
编辑:Aeneas 好困
本文由人人都是产品经理作者【新智元】,微信公众号:【新智元】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。