Agents don’t have an intelligence problem. They have a context problem. They fail because their context layer is scattered, stale, slow, or hard to use.
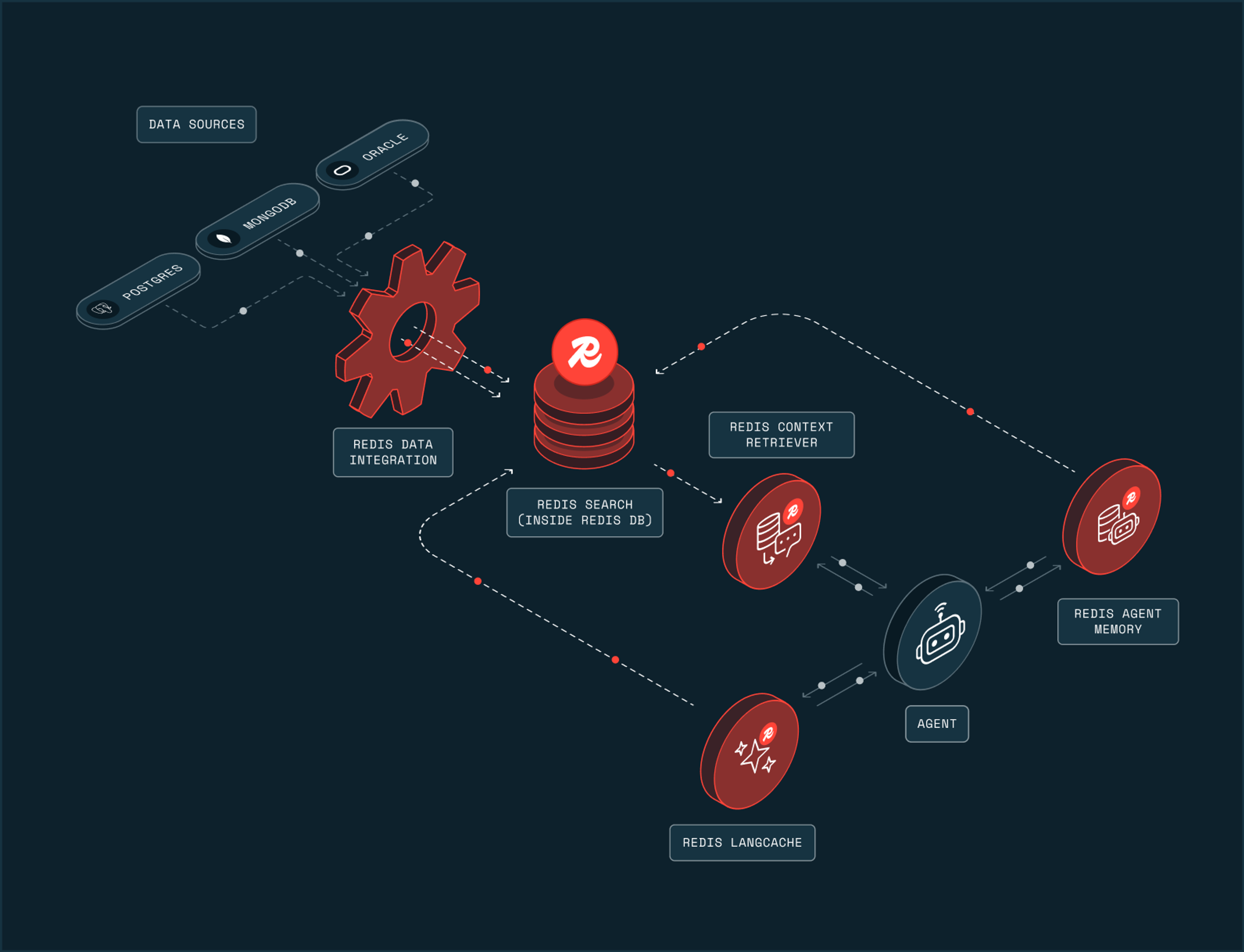
That’s why we’re introducing Redis Iris, our new context and memory solution that turns fragmented enterprise data into live, agent-ready context. Redis Iris is a context engine, an important layer in an AI stack that sits between an agent and the data it needs to act, feeding the right context, in the right form, at the right time.
Iris is composed of five tools, Redis Context Retriever, Redis Agent Memory, Redis Data Integration, Redis LangCache, and Redis Search. Two of these are brand new to Redis. Context Retriever makes external data sources navigable by agents. Agent Memory preserves short- and long-term context across tasks and agents.
It’s all built on top of Redis, storing and serving the underlying vector, structured, unstructured, and real-time data that scales alongside your agent fleets.
For customer support bot, the answer to “Why is my order late?” may be spread across a customer database, an order system, a shipping provider, a ticketing tool, and a policy document. Without a context engine, the bot either gives a generic answer or relies on brittle, one-off integrations that expose a lot of low-level complexity.
A context engine creates a governed, agent-readable view of the data it needs to answer that question. In this example, it would define business entities like customers, orders, shipments, tickets, and policies, as well as the relationships and access rules between them. The bot can then retrieve the right customer, order, shipment status, policy, and prior interaction in one flow. The result is an agent that answers using the customer’s actual situation, not just static documentation.
The hardest problems in production AI are no longer solved by model choice. They show up at runtime: stale state, slow retrieval, fragmented memory, disconnected tools, and sessions that fail to compound. A context engine gives agents fast, reliable access to the operational data and memory they need while they’re working.
For agents to function at scale, a context engine has to meet four requirements:
Redis is already in the agent runtime, used by 43% of enterprise AI agent stacks to serve the hot operational state agents need. We combine sub-millisecond performance, memory, and retrieval in one package so agents can meet real production demands like voice turn-taking, fraud scoring, and customer experiences that carry across sessions.
Because Redis is multi-cloud, BYOC, and works across any agent platforms, teams get the context layer they need without turning their AI strategy into a hyperscaler lock-in decision.
Redis Iris combines five tools, rolled up into a single runtime that makes context navigable, current, fast, and better over time.
If you’re already building real-time agents, you don’t need another vendor in your stack. You need a better runtime layer for the one you already have.
Redis Iris extends the Redis infrastructure teams already know and trust, bringing navigable retrieval, fresh operational state, compounding memory, and fast semantic search into one engine instead of spreading them across a tool zoo of vector databases, memory services, streaming pipelines, caches, and custom glue.
That means agents can work with the context they need while they’re actually running. They can navigate business entities through a schema instead of gambling on text-to-SQL. They can retrieve fresh state without forcing teams to own another ETL pipeline. They can carry memory across sessions and channels. And they can stay inside the latency budgets that matter for voice, fraud, personalization, and customer experience.
The payoff: simpler agent architecture, fewer seams to debug, and agents that get faster, more reliable, and more useful in production.
The easiest way to see the difference is to try it. Use your existing Redis Cloud account to start adding context capabilities to your agent stack, or create a new Redis Cloud account for free.
Start with the Redis you already know, now built to scale with your agents.
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。