Every Redis release continues a simple commitment: the same command, on the same hardware, should do more work. Redis 8.6 delivered a step change for vector workloads, sorted sets, and GET-dominated caching paths. Redis 8.8 carries that cadence forward, with the biggest wins landing on the commands that carry most real-world traffic — MGET, MSET, HGETALL, and the SCAN family — alongside meaningful improvements in streams, sorted sets, bitmaps, and the persistence and replication paths.
This post is the performance-focused companion to the Redis 8.8 release announcement. Every number below compares Redis 8.8 to Redis 8.6, the previous stable release.
Benchmarks were run across the latest generation of Intel, AMD, and ARM hardware on AWS, comparing Redis 8.6 and Redis 8.8 with identical builds on both branches. Every gain reported below has been reproduced across multiple runs using our official OSS SPEC.
The table below summarizes the impact by data type and command family; the rest of the post explains what changed in each case.
Redis 8.8 introduces significant end-to-end throughput improvements:
| Data type | Operations | end-to-end throughput improvements |
|---|---|---|
| String | MGET (pipelined, with I/O-threads) | Up to 68% |
| MGET (pipelined, single thread) | Up to 50% | |
| MSET | Up to 5% | |
| Hash | HGETALL | Up to 25% (1K+ fields) |
| Streams | XREADGROUP | Up to 83% (COUNT 100) |
| Sorted set | ZADD, ZINCRBY, ZRANGEBYSCORE | Up to 74% |
| Bitmap | Bitmap operations | Up to 28% (x86) |
| (several) | SCAN, HSCAN, SSCAN, ZSCAN | Up to 40% |
In addition, persistence and replication (full synchronization) is now up to 60% faster.
MGET and MSET are the workhorses of caching. They are also the commands most sensitive to cache-miss latency: every key in a batch means another dict traversal, and the value pointers sit in cache lines that are almost never warm when the command arrives.
In Redis 8.6 we introduced a memory prefetch framework that let single-key commands hide dict-traversal latency behind useful work. In Redis 8.8, that framework has been extended to multi-key bulk reads. When a pipelined MGET batch arrives, Redis walks the dict buckets for every key in the batch ahead of time and issues prefetch hints — so by the time each key is looked up, its cache line is already on its way to the CPU. The same idea applies to writes:
MSET and MSETNX now do a batched dict bucket prefetch for groups of keys inside setKey.
Measured on m7i.metal-24xl (x86) vs Redis 8.6:
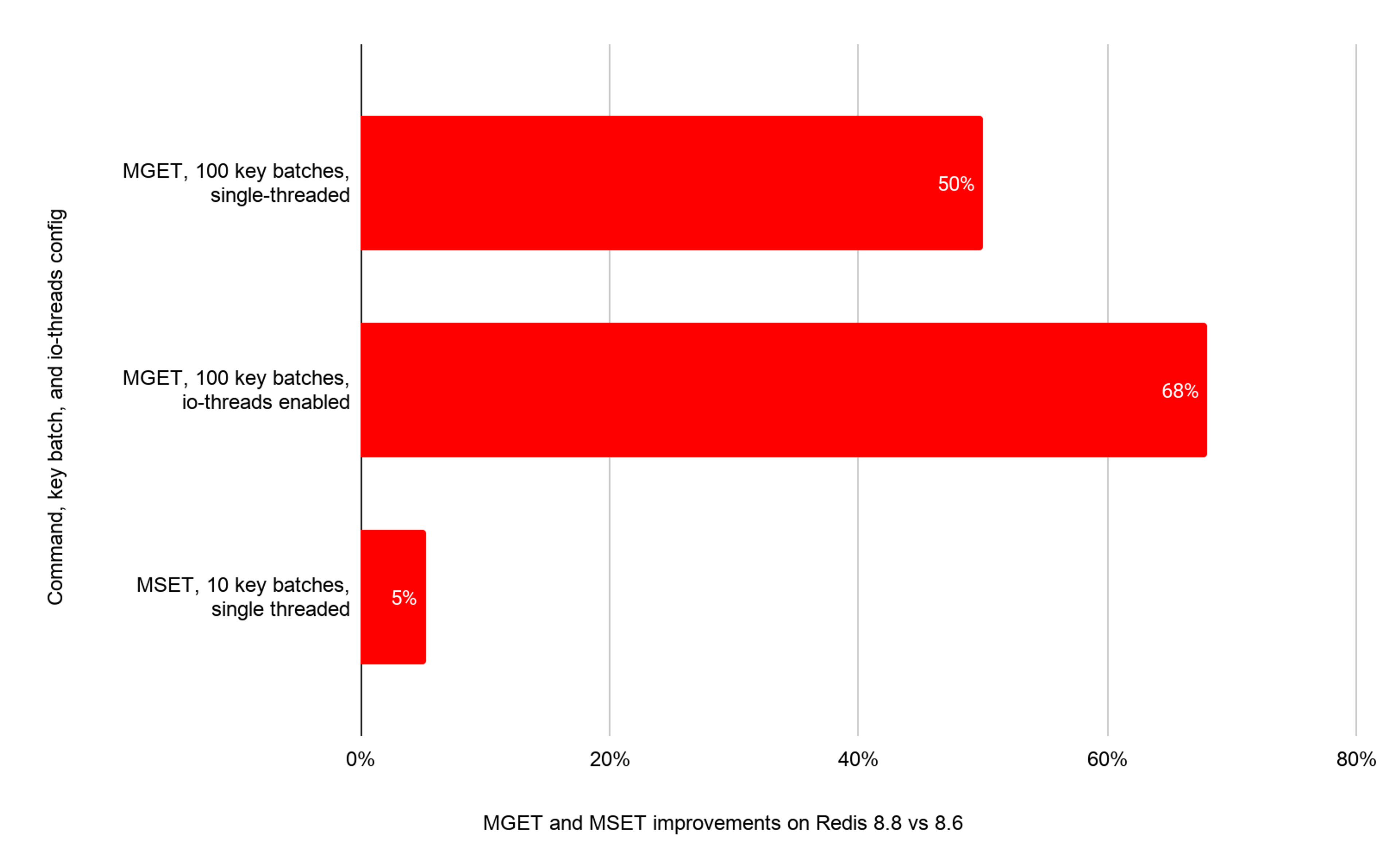
The MGET gain is the largest. In pipelined deployments with io-threads, it moves the bottleneck out of Redis' dict traversal and into the network for all but the largest values. There is no new command, no new flag, and no protocol change — upgrading is the entire deliverable.
HGETALL improved twice in Redis 8.8, and the improvements stack.
First, HGETALL benefits from a broader infrastructure change that extends cross-command prefetching from the pipeline header to the full pending batch — including the deferred-reply object list used by reply-heavy commands. On a 1,000-field hash, that alone lifts HGETALL by +4.6% on x86.
Second, for hashes large enough to live in the hashtable encoding, a dedicated batched dict bucket prefetch has been added to the field-iteration loop itself. The same mechanism now covers HKEYS and HVALS.
On a 1,000-field hashtable-encoded hash, the two changes compound to approximately +15% to +25% vs Redis 8.6 on x86, depending on pipeline depth and hash field count.
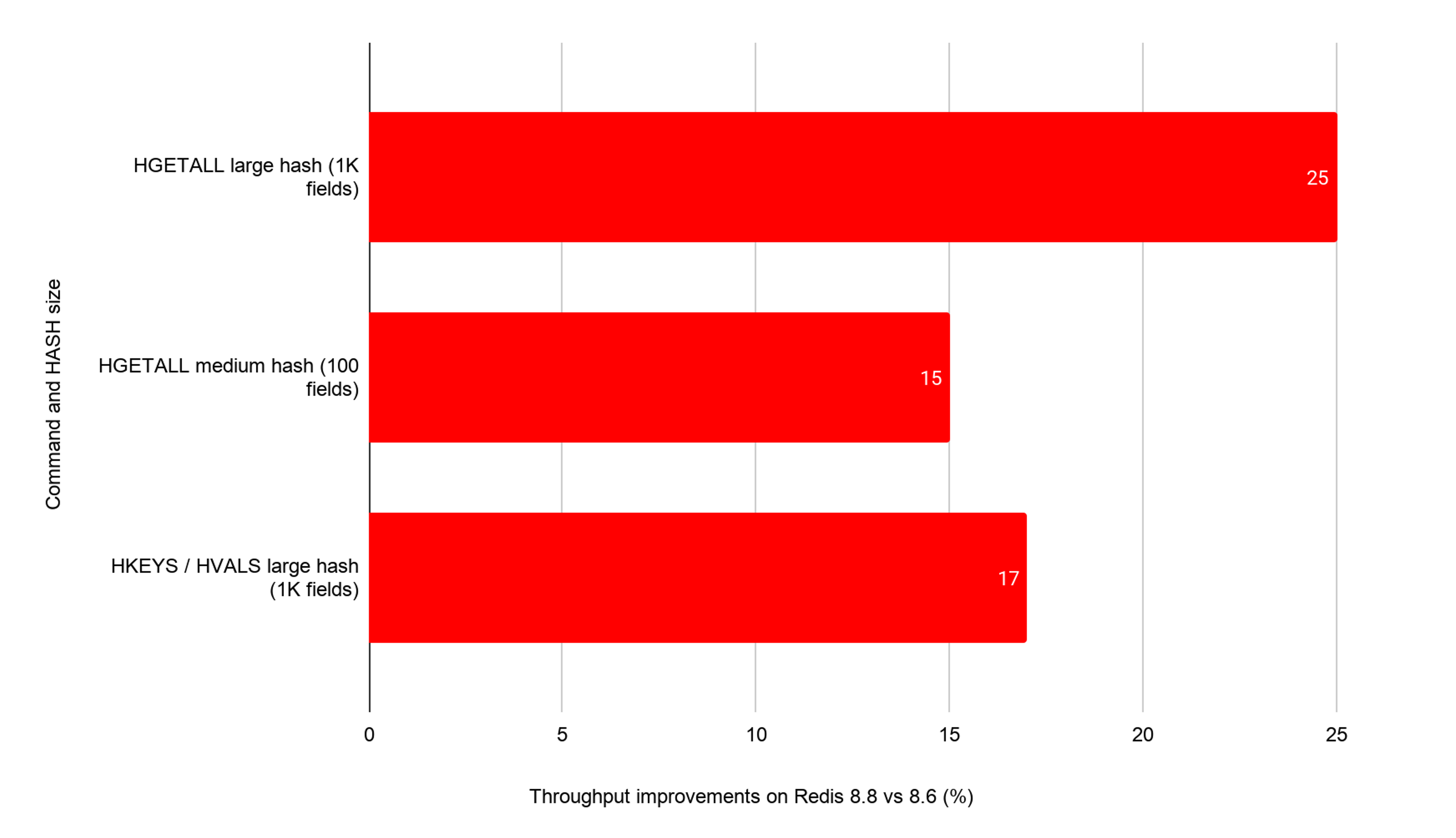
Small, listpack-encoded hashes see the +4.6% from the broader prefetch extension alone — listpack is already cache-resident and does not need the HGETALL-specific prefetch.
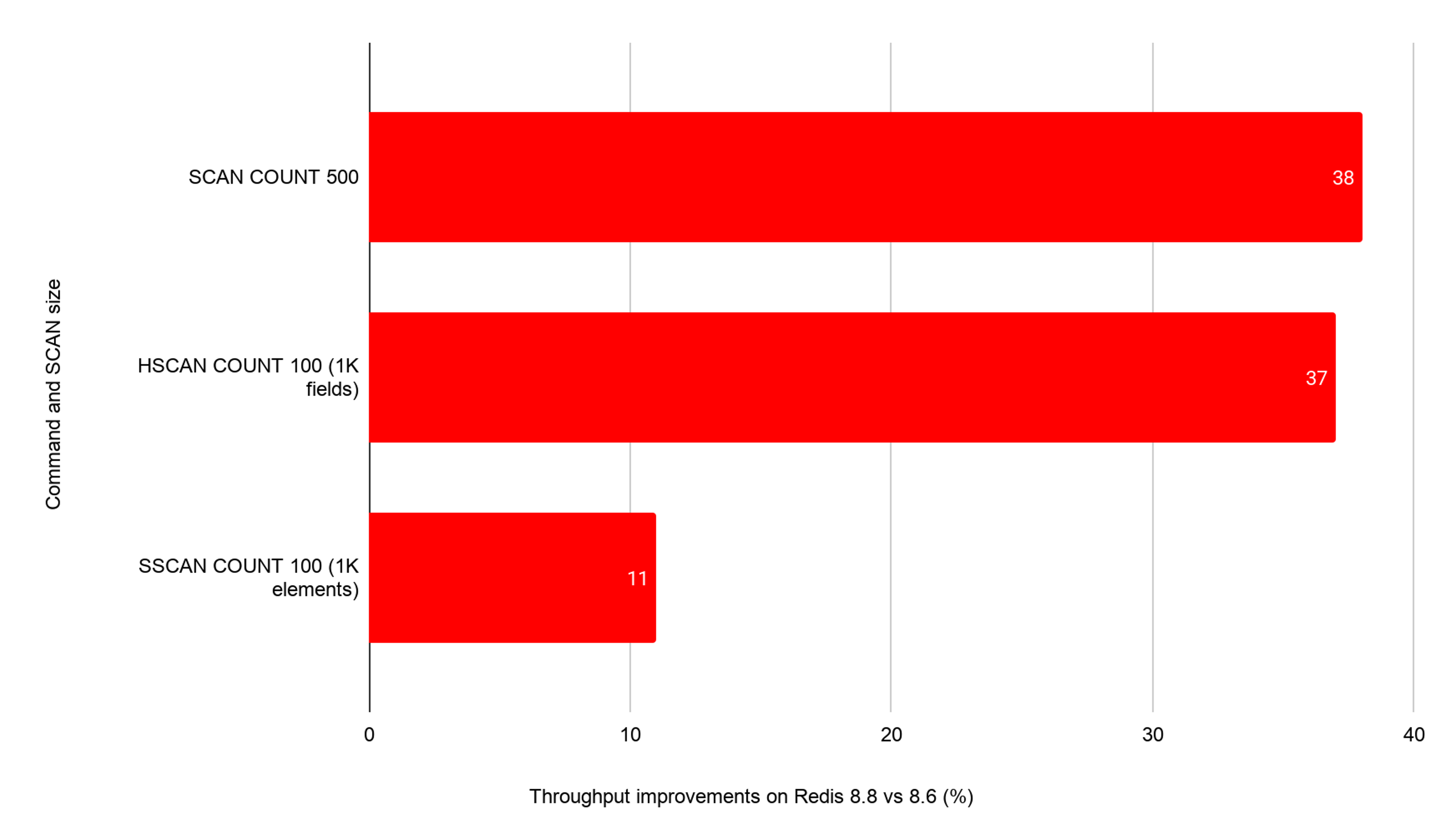
On every SCAN, HSCAN, SSCAN, and ZSCAN call, the reply callback previously allocated a list-node per matching key — roughly 500 allocations and 500 frees per SCAN COUNT 500 command, all on the hot path. In Redis 8.8, that linked list is replaced with a stack-allocated vector container, so typical COUNT values generate zero heap allocations on the reply path.
Measured vs current unstable, on both x86 m7i and ARM m8g: SCAN COUNT 500 pipeline-10 gains +38.0% on x86 and +39.7% on ARM.
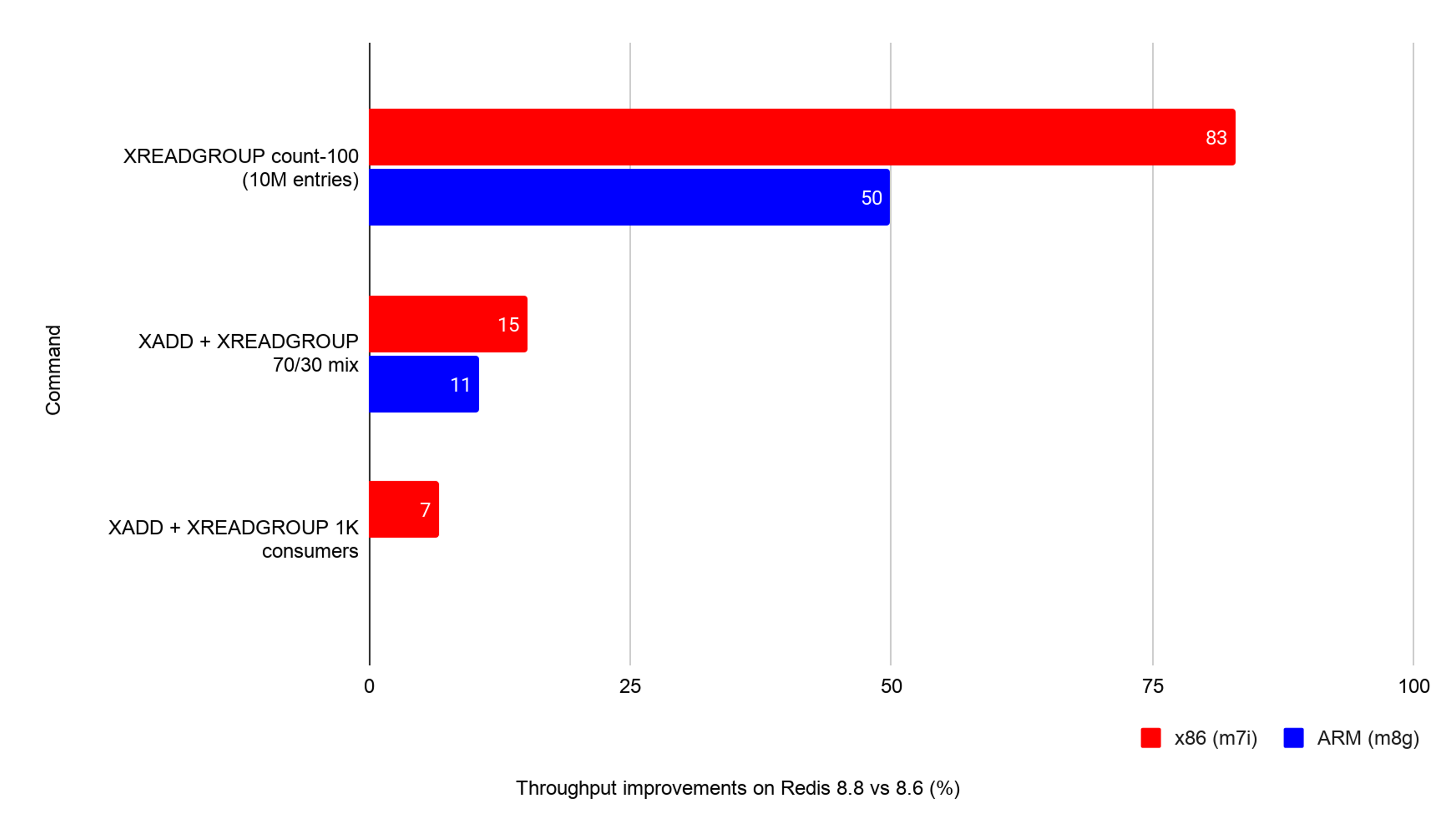
Streams see the largest single improvement in Redis 8.8. The underlying change rewrites rax — the radix tree Redis uses to index stream entries and consumer-group pending entries — with two specializations tuned for how streams are actually accessed:
- An O(1) append fast path for sequential inserts. Stream IDs are monotonically increasing, so every XADD takes the fast path.
- A last-child-first lookup on descent. For XREADGROUP and range scans, the child you want is almost always the most recently inserted one — walking the child list from the tail eliminates the per-node linear scan.
Measured on Redis 8.6 vs Redis 8.8:
Redis 8.0 introduced the fast_float library (#11884) to accelerate ZADD, ZINCRBY, ZRANGEBYSCORE, GEOADD, and related double-parsing paths. Redis 8.8 goes further on two fronts: the fast_float C++ dependency is replaced with a pure-C implementation, simplifying the build (#14661), and the Clinger fast path has been widened to cover 17-to-19-significant-digit mantissas via a single 128-bit multiply (#15061).
On the canonical sorted-set-with-double-scores load benchmark:
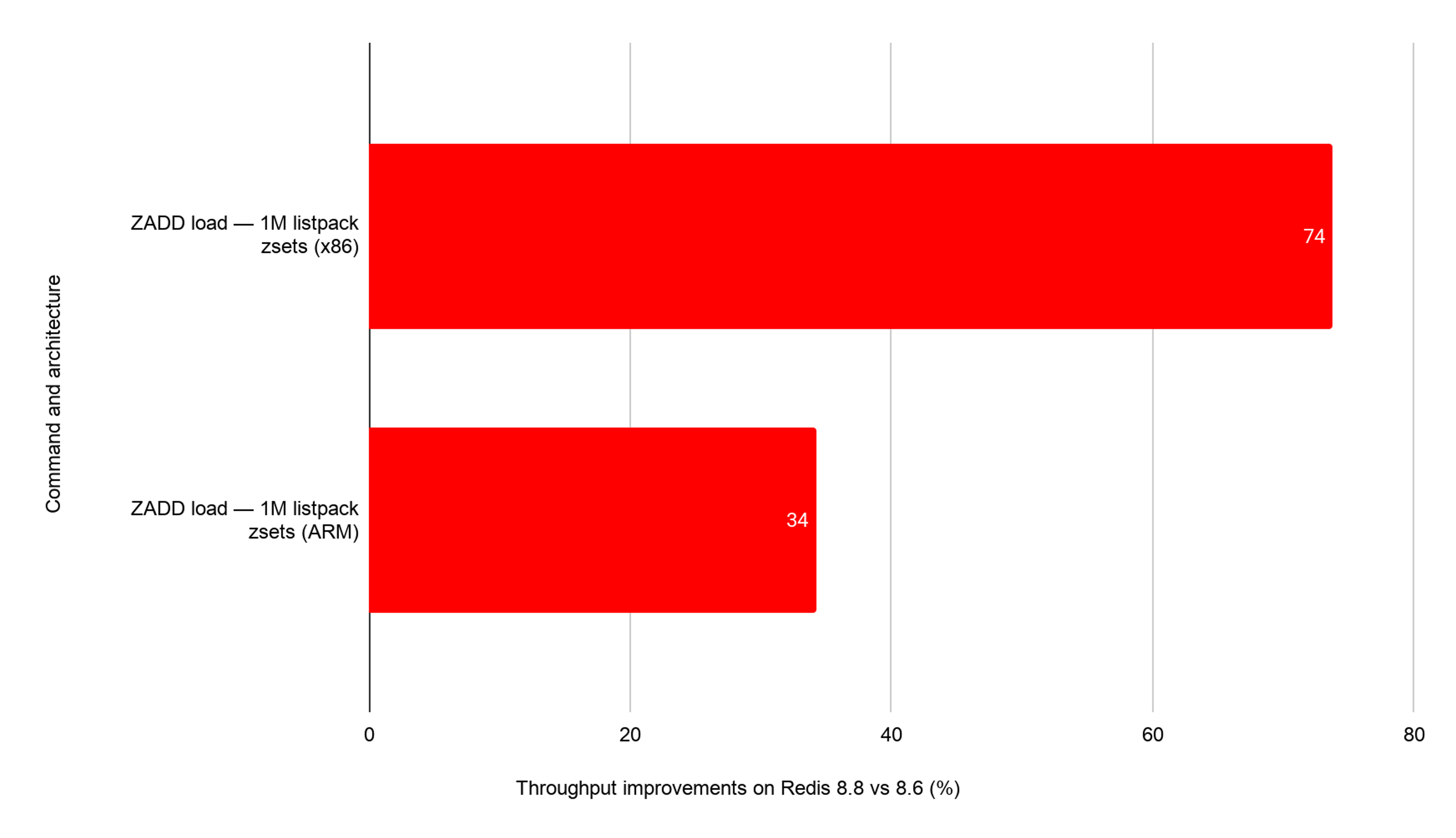
This matters for any ZADD, ZINCRBY, or ZRANGEBYSCORE workload with double-precision scores — leaderboards, time-series secondary indexes, and any pattern where scores come from timestamps or client-side float-to-string conversions.
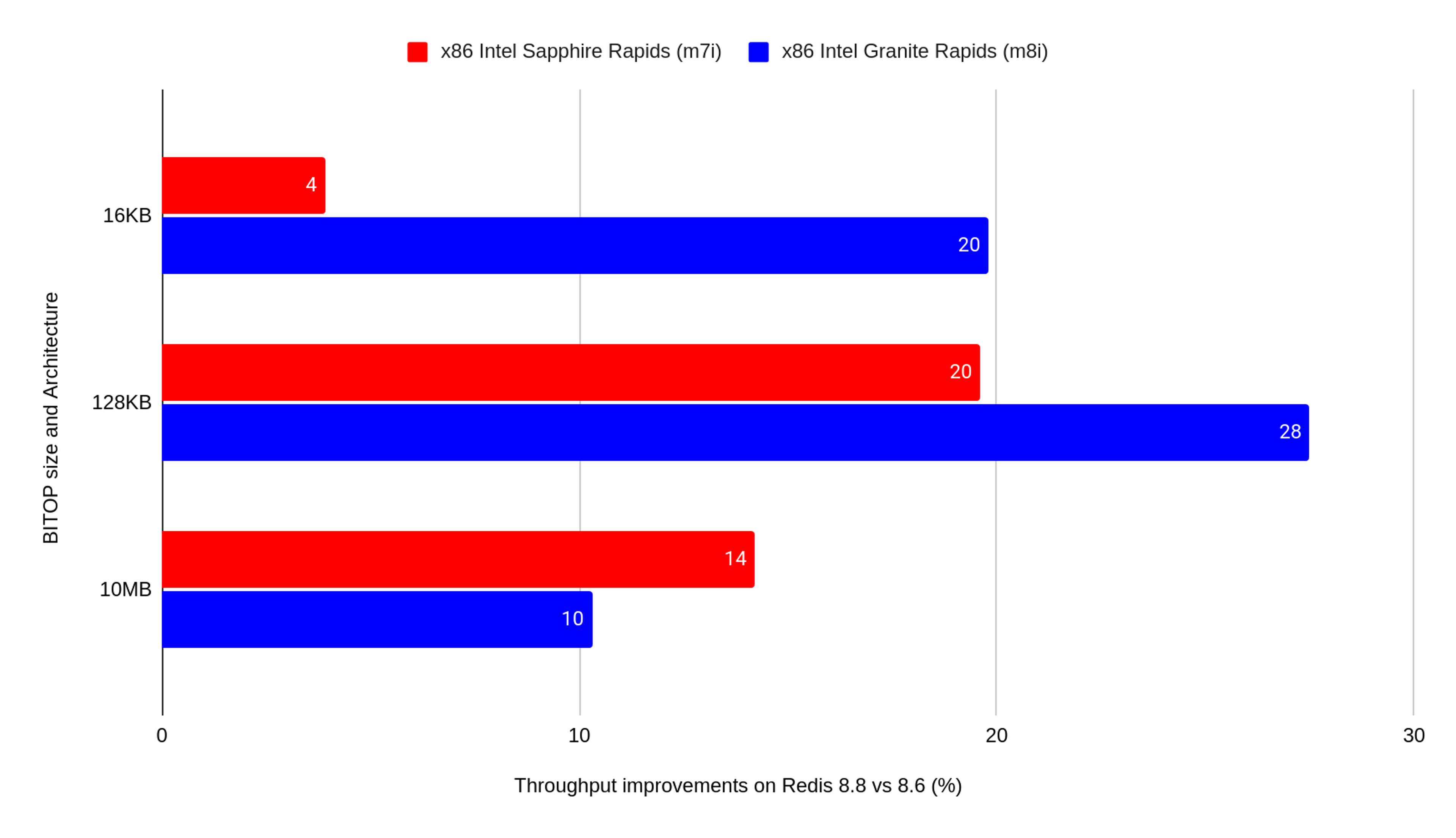
BITOP AND, OR, XOR, and NOT are now vectorized with AVX-512 on Ice Lake and newer Intel and AMD CPUs. Upstream measurements show up to +80% on value sizes of 10,000 bytes and above, with smaller gains on shorter values where the fixed dispatch overhead does not amortize.
Redis 8.8 trims cost across several operational paths. Diskless full sync is the most visible win: because the replication link already provides integrity, the RDB checksum computation and validation are no longer performed on diskless transfers, cutting a 12 GB full-sync on a c8g.2xlarge replica from 35 seconds to 11 seconds — a 68% reduction.
BGSAVE and full sync also pay less in the fork child. Dict bucket arrays are now released back to the OS with MADV_DONTNEED, reducing the RSS spike and copy-on-write amplification during snapshotting, and memory tracking — which the child never used — is now disabled there.
Replication itself is lighter on the wire-feed path: the per-write bookkeeping in feedReplicationBuffer() has been reworked, so high-argument commands (HSET with many fields, MSET with many keys) pay less overhead on every replicated write. Pipelined SET, HSET, and ZADD with a replica attached measure between +3% and +26% faster. In addition, primary and replica clients are now serviced inside I/O threads, shifting more of the replication path off the main thread.
All these enhancements are generally available on Redis 8.8 open source today. You can start using the new commands by downloading Redis 8.8 and experimenting with them in your existing workflows.
Have feedback or questions? Join the discussion on our Discord server or reach out to your account manager.
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。