AWS PrivateLink resource endpoints are now generally available across all Redis Cloud Pro subscription types, including Redis Flex and Active-Active deployments. That means you can connect apps to Redis Cloud through a private, scoped endpoint without exposing entire VPC networks to each other. Our PrivateLink implementation will also support smart client handoffs in the near future, helping apps stay connected during maintenance and upgrades.
Redis was an early adopter of AWS PrivateLink, and large-scale enterprise customers have been using PrivateLink with Redis Cloud to meet their most demanding workloads.
This post compares AWS PrivateLink and VPC peering as connectivity options for Redis Cloud, focusing on the trade-offs between security isolation, operational simplicity, latency, and throughput.
For most deployments, PrivateLink is the better default. It provides scoped connectivity, works with overlapping CIDR ranges, and avoids exposing entire VPCs to each other. VPC peering remains the better fit for extremely latency-sensitive workloads where every microsecond matters and the lowest possible network overhead is required.
The performance trade-off for PrivateLink is measurable but small: under 50 µs of additional latency in our ultra-low-latency benchmark, and no measurable throughput impact for workloads operating below saturation.
Let’s unpack where those trade-offs matter, when to choose each model, and what the benchmark data shows.
Redis Cloud has long supported VPC peering as a private connectivity option for AWS deployments, and it remains a widely used model for latency-sensitive production workloads.
Both options keep your traffic on the AWS network and off the public internet. The differences come down to four things: performance (throughput and latency), security and network complexity, and cost effectiveness.
VPC peering creates a direct bilateral route between two VPCs. It's simple to set up and adds minimal latency overhead. The trade-off is network exposure. Because VPC peering is a Layer 3 connection, it requires non-overlapping CIDR ranges between the peered VPCs. That can be a hard blocker when IP ranges collide. It also exposes more network surface area than many teams want: both VPCs gain network-level visibility into each other, not just access to the Redis database.
PrivateLink takes a different approach. Rather than routing traffic at the VPC level, it exposes a specific service endpoint that your app connects to directly. Connectivity is strictly directional—from consumer to provider—and your VPCs are never exposed to each other. You grant access to exactly one resource: your Redis database. Nothing else. PrivateLink is a Layer 4 connectivity model that works across AWS accounts and VPCs, even when CIDR ranges overlap. For teams with zero-trust requirements or operating under compliance frameworks such as SOC 2, HIPAA, or PCI DSS, this scoped, directional model is often what security policies mandate.
To quantify the impact, we benchmarked four workloads against the same Redis Cloud Pro database (200 GB, 300K ops/s, single-AZ us-east-2, TLS disabled) using memtier_benchmark from a c5.4xlarge client. The workloads used a 1:9 write/read ratio with no rate limiting, while varying connection counts and pipeline depths to target p99 latencies ranging from sub-500 µs to sub-5 ms.
The only variable between runs was the connectivity layer (VPC peering versus PrivateLink) on the two supported topologies:
PrivateLink should be the default choice for most deployments. The additional network RTT is negligible for the majority of production workloads. The matrix shows when it isn’t:
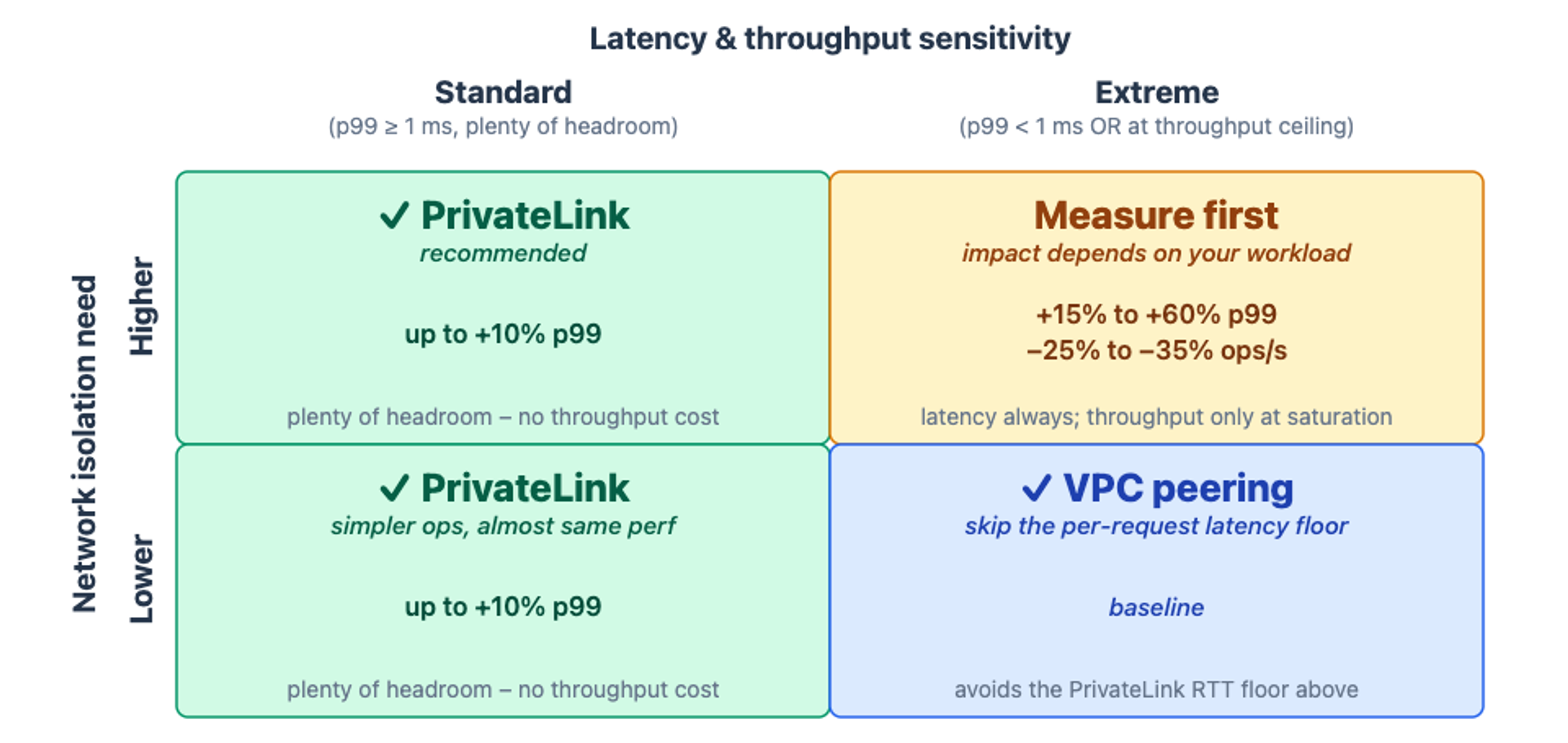
Rule of thumb: PrivateLink first. Pick VPC peering only when your workload sits in the Extreme column and you don't need network isolation. Extreme workloads are those operating near hard limits: either sub-ms p99 latency targets or near-saturation throughputs.
In other words: start by asking whether you have a hard network isolation requirement. If yes, choose PrivateLink. At standard latency targets (p99 ≥ 1 ms) the cost is just an increase of ~10% on latency; at extreme targets, benchmark your workload before committing.
If no network isolation is required, the next question is whether your application has extreme workloads (p99 < 1ms or at throughput ceiling). If yes, VPC peering is the better fit. If no, prefer PrivateLink for its network isolation benefits.
Note on throughput: the penalties quoted (-25% and -35% ops/s) describe behavior at saturation. For a workload running below capacity (most production apps), the throughput “tax” doesn't show up.
The right mental model is an approximately 10% increase in p99 latency for typical production workloads. For ultra-low-latency workloads already operating below 500 µs, the same absolute RTT increase can translate into a much larger relative percentage increase.
Most production apps won't notice it. If your Redis operations typically complete in the 1–5 ms range (which is true for most workloads), the PrivateLink overhead becomes negligible.
For sub-500µs latency-critical apps, benchmark your specific workload. If you're running real-time bidding, high-frequency financial operations, or gaming leaderboards where every microsecond counts, the relative latency increase at p50 (up to ~50%) is worth measuring against your own SLAs. Absolute latencies should still remain sub-millisecond, but validate this against your own payload sizes, connection patterns, and SLAs.
PrivateLink is our recommended connectivity model for Redis Cloud on AWS. It's the best choice for teams that care about security posture, compliance, or operational simplicity across accounts and CIDR ranges – which is most teams. VPC peering remains a reasonable choice in two specific situations: when your workload is extremely latency-sensitive and every microsecond counts, or when the security benefits of PrivateLink don't justify the additional cost for your use case.
We'll continue publishing benchmark data as testing progresses.
If you’re ready to configure AWS PrivateLink on Redis Cloud, start with our docs. If you’re choosing between PrivateLink and VPC peering for a latency-sensitive workload, talk to a Redis expert about your network setup.
Benchmark environment: AWS, Redis Cloud Pro, dedicated instances. Results represent median across multiple runs. Your results may vary based on instance size, region, payload characteristics, and app access patterns.
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。