Kafka 是我认为最值得深入研究的一个消息队列,它的官方文档写的非常详尽,从配置到使用,从设计到实现无不体现研发的技术功底。
Kafka 已经发展到 3.x 时代,增加了很多的功能,比如幂等、事务等,如今已经能够保证消息 100% 消费了。
阅读源码能够有两点好处:一个是能够在工作中对 Kafka 进行深度优化,二是能够学习到消息中间件的设计思路。
Kafka Producer Java 客户端如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| public class MyProducer {
static String topic = "test";
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
/*
0 生产者发送消息之后不需要等待任何服务端的响应。
1 生产者发送消息之后,只要分区的 leader 副本成功写入消息,那么它就会收到来自服务端的成功响应,但是如果发生在 leader 选举阶段会造成消息丢失
-1/all 生产者在消息发送之后,需要等待 ISR 中的所有副本都成功写入消息之后才能够收到来自服务端的成功响应。
*/
props.put("acks", "all");
// 重试次数
props.put("retries", 0);
// 指定 Buffer Pool 大小
props.put("batch.size", 16384);
// ProducerBatch 发送时间,如果 batch.size 未达到,但是 linger ms 时间达到,则会发送次 Batch 消息
props.put("linger.ms", 10000); // 10s 发送
//RecordAccumulator 缓存大小,默认值为 33554432B,32MB
props.put("buffer.memory", 33554432);
// 生成消息的速度大于发送的速度会造成生产者内存不足,要么抛异常,要么阻塞这个配置的毫秒数
props.put("max.block.ms",60000);
// 消息最大容量,默认 1MB
props.put("max.request.size",1048576);
props.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
Producer<String,String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 10; i++) {
Thread.sleep(1000);
producer.send(new ProducerRecord<>(topic,
Integer.toString(i), Integer.toString(i)), (recordMetadata, exception) -> {
System.out.printf("topic=%s,partition=%s,offset=%d,timestamp=%s \n",
recordMetadata.topic(),recordMetadata.partition(),
recordMetadata.offset(),recordMetadata.timestamp());
});
}
System.out.println("Message sent successfully");
producer.close();
}
|
从代码结构上分析,主要是两个部分:1. Producer 参数配置; 2. 发送消息。
Producer 参数部分是控制 Kafka 高效稳定发送消息的关键,常用的参数已经写到代码中。如果需要查看全部 Producer 参数,可以在代码开启 Debug 模式运行查看。
我们主要分析一下 Send 的原理
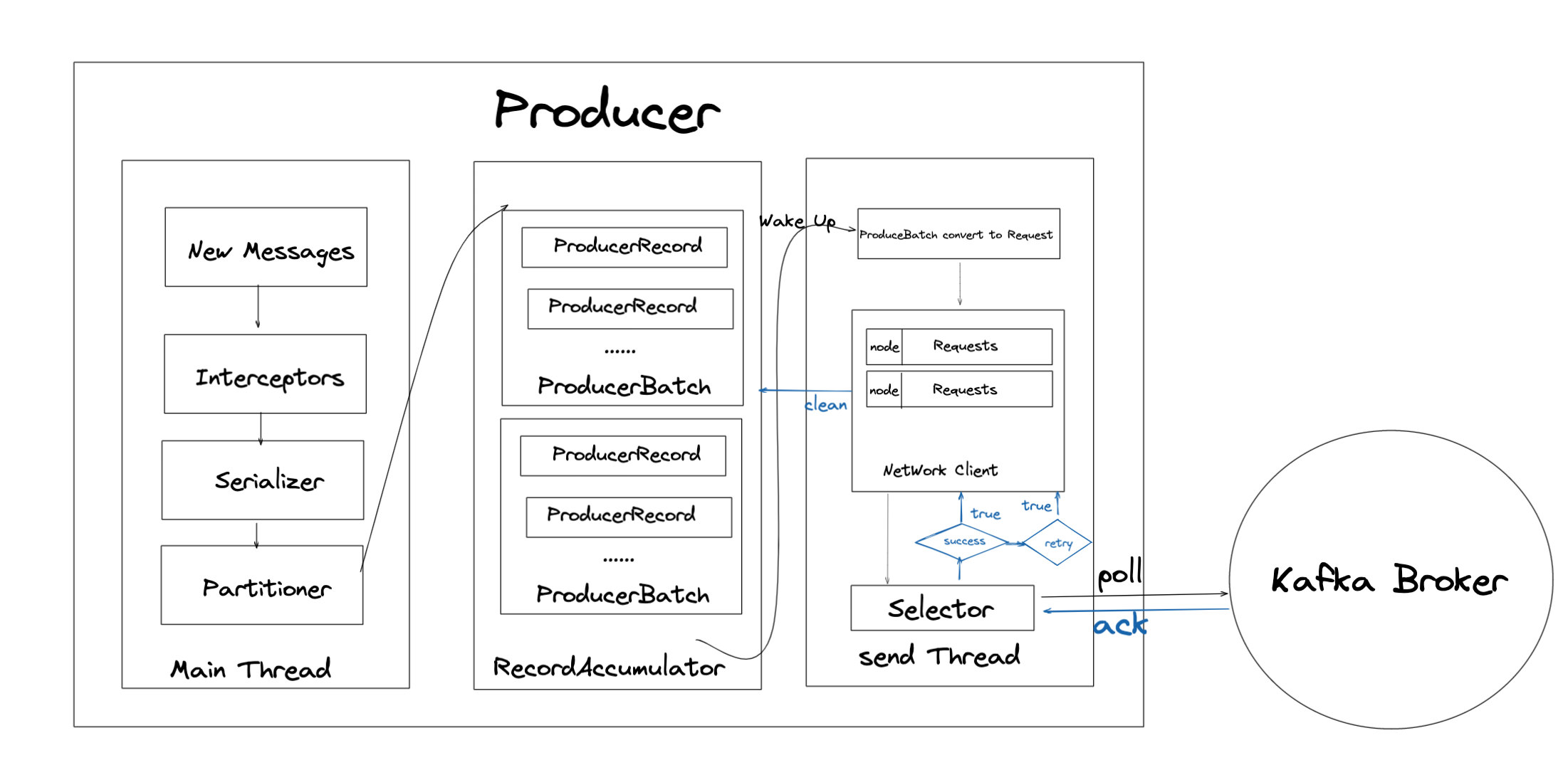
Kafka 客户端主要由一个主线程,一个缓冲器,一个发送线程三个部分组成。
主线程做的操作是对消息进行生成、拦截器处理、序列化、分区器处理然后将格式化的消息发送到 RecordAccumulator 缓存中。
缓存的作用是将消息批量发送以减少 IO 次数,当一条消息会经过分区器路由到对应分区的缓存队列中,如果没有则会创建。
如果缓存大小达到了batch.size后会唤醒 sender 线程,或者 sender 线程等待时间到了linger.ms值后会检查缓存中待发送的数据。
sender 线程负责处理发送前的数据封装,将缓存中的分区消息转成 <Node,Request> 格式,这样就完成了应用逻辑到网络 I/O 层面的转换。
最后准备好发送的消息经过 Nio Selecor 发送到 Broker 集群中,然后 Broker 会进行响应 Response,然后 sender 线程决定重试或者删除缓存。
在 NetWorkClient 中维护了一个InFlightRequests数据结构主要是Map<NodeId,Deque<Request>>,用来管理请求和元数据,默认每个链接能够缓存 5 个 request,超过后将不会再向此连接发送请求,除非接收到 broker 的响应。当对应的 NodeId 的请求堆积了 5 个,此时这个连接可能出现负载问题无法快速处理问题,那再向这个NodeId 上发送请求肯定会加剧堆积的情况。
总结:Kafka Producer 在设计上利用缓存来提升吞吐量、利用两个线程区分不同的工作内容,整体设计非常的清晰和优雅。