Here is a synopsis of what we did as part of our Re-IP exercise.
Proxmox Cluster IP Migration Summary
Environment
- Proxmox VE 9.2.3
- Two-node cluster:
Original Management Network
- indi01: 192.168.2.222
- indi02: 192.168.2.223
- Gateway: 192.168.2.1
New Management Network
- indi01: 10.50.10.222
- indi02: 10.50.10.223
- Gateway: 10.50.10.1
Files Modified
- /etc/network/interfaces
- Updated management IP addresses.
- Updated default gateway.
- /etc/hosts
- Updated hostname-to-IP mappings for both cluster nodes.
- /etc/pve/corosync.conf
- Updated:
- ring0_addr: 192.168.2.222 → 10.50.10.222
- ring0_addr: 192.168.2.223 → 10.50.10.223
- Incremented:
- config_version: 2 → config_version: 3
Initial Migration Procedure
- Updated the network configuration files on both nodes.
- Updated /etc/hosts on both nodes.
- Updated /etc/pve/corosync.conf.
- Rebooted both cluster nodes.
- Verified both nodes came online using their new IP addresses.
- Verified node-to-node ICMP connectivity using both IP addresses and hostnames.
Commands Executed During Troubleshooting
Verification:
- getent hosts indi01
- getent hosts indi02
- pvecm status
- pvecm nodes
- corosync-cfgtool -s
- corosync-cmapctl | grep members
- corosync-cmapctl | grep ring0_addr
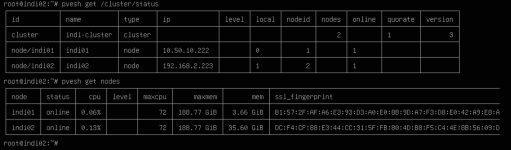
- pvesh get /cluster/status
- pvesh get /nodes
Cluster Recovery Actions
- systemctl restart corosync
- pvecm expected 1
- systemctl restart corosync
- pvecm status
Certificate / Service Refresh Attempts
- pvecm updatecerts --force
- systemctl restart pve-cluster
- systemctl restart pvedaemon
- systemctl restart pveproxy
These steps were executed multiple times during troubleshooting but did not resolve the issue described below.
Current Verified State
Corosync Runtime
- corosync-cmapctl | grep members
returns:
- runtime.members.1.ip = 10.50.10.222<br>runtime.members.2.ip = 10.50.10.223
and
corosync-cmapctl | grep ring0_addr
returns:
- 10.50.10.222<br>10.50.10.223
Hostname Resolution
returns:
- 10.50.10.223 indi02.dglab.local indi02
Cluster Status
pvecm status
- Quorum restored
- Both nodes online
- Corosync healthy
Issue Remaining
pvesh get /cluster/status
returns:
- node/indi01 -> 10.50.10.222<br>node/indi02 -> 192.168.2.223
even though:
- Corosync runtime reports 10.50.10.223
- Hostname resolution reports 10.50.10.223
- Node-to-node connectivity is working on 10.50.10.x
Operational Impact
Cross-node management functions continue attempting to connect to the old address:
- ssh: connect to host 192.168.2.223 port 22: No route to host
Examples include:
- Opening a shell on indi02 from the indi01 GUI
- Other node-to-node management operations routed through the Proxmox management layer
Additional Investigation Performed
Reviewed:
/etc/hosts<br>/etc/pve/corosync.conf<br>/etc/pve/.members<br>/etc/pve/nodes<br>/etc/pve/priv
and verified:
- No remaining references to 192.168.2.223 were found in the active Corosync configuration.
- Corosync runtime reflects only the new 10.50.10.x addresses.
- The stale address appears to originate from data returned through:
pvesh get /cluster/status
which remains inconsistent with the Corosync runtime state.