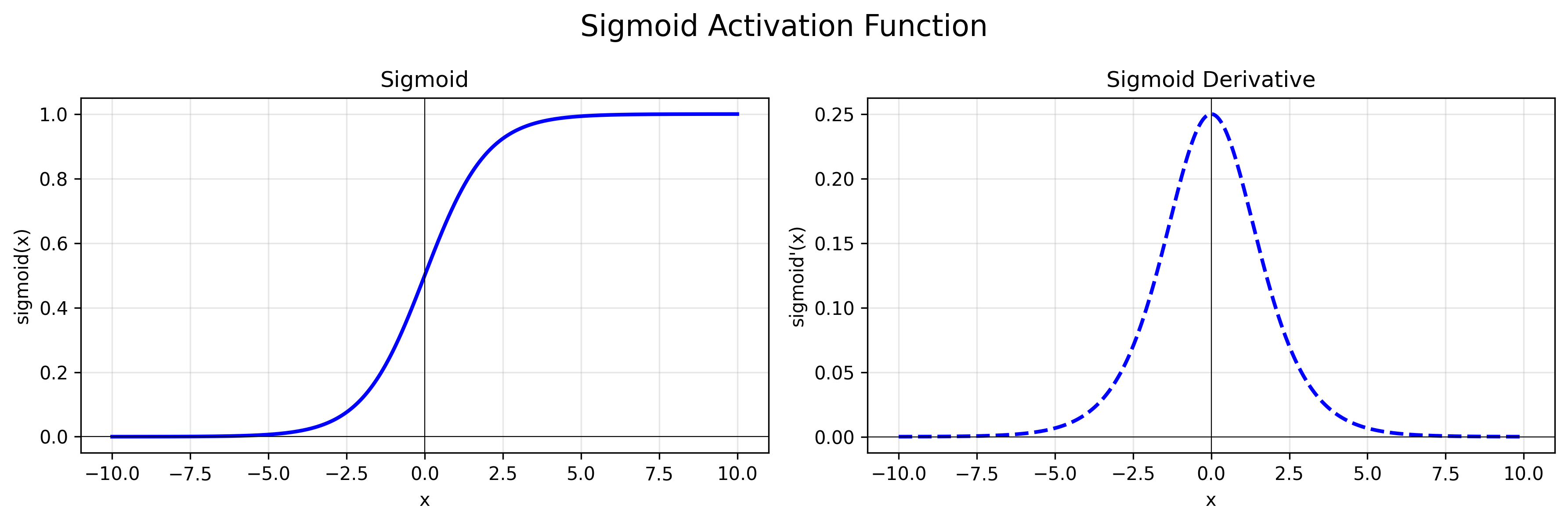
公式:$f(x) = \frac{1}{1 + e^{-x}}$
导数:$f’(x) = f(x) * (1 - f(x))$
特点:函数输出在(0,1)之间,导数输出在(0,0.25)之间。[-6, 6]之间比较敏感,[-3, 3]之内效果较好。一般5层之内就会出现梯度消失现象,一般只用于二分类的输出层。
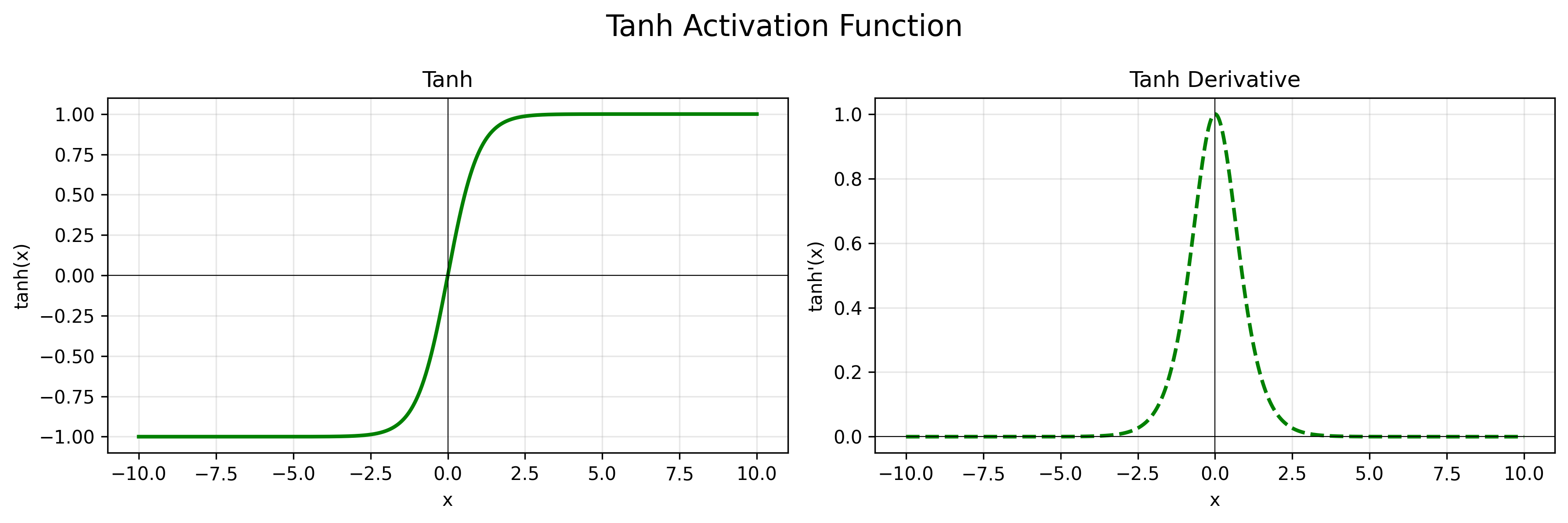
公式:$f(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}}$
导数:$f’(x) = 1 - f(x)^2$
特点:函数输出范围在(-1, 1)之间,导数输出在(0,1)之间。收敛速度更快,一般用于隐藏层。
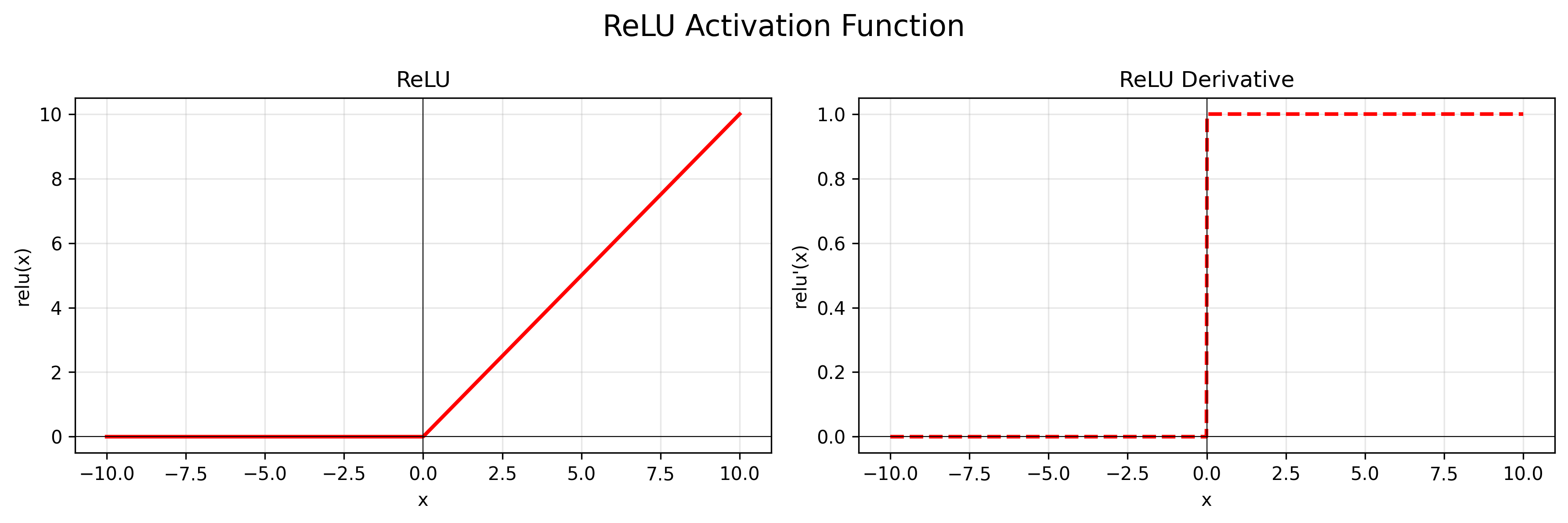
公式:$f(x) = max(0, x)$
导数:$f’(x) = 1$ if $x > 0$; $f’(x) = 0$ if $x < 0$
特点:忽略负信号,更简单,效率更高。会使一部分神经元输出为0,减少参数之间的依存关系,缓解过拟合。一般隐藏层首选。
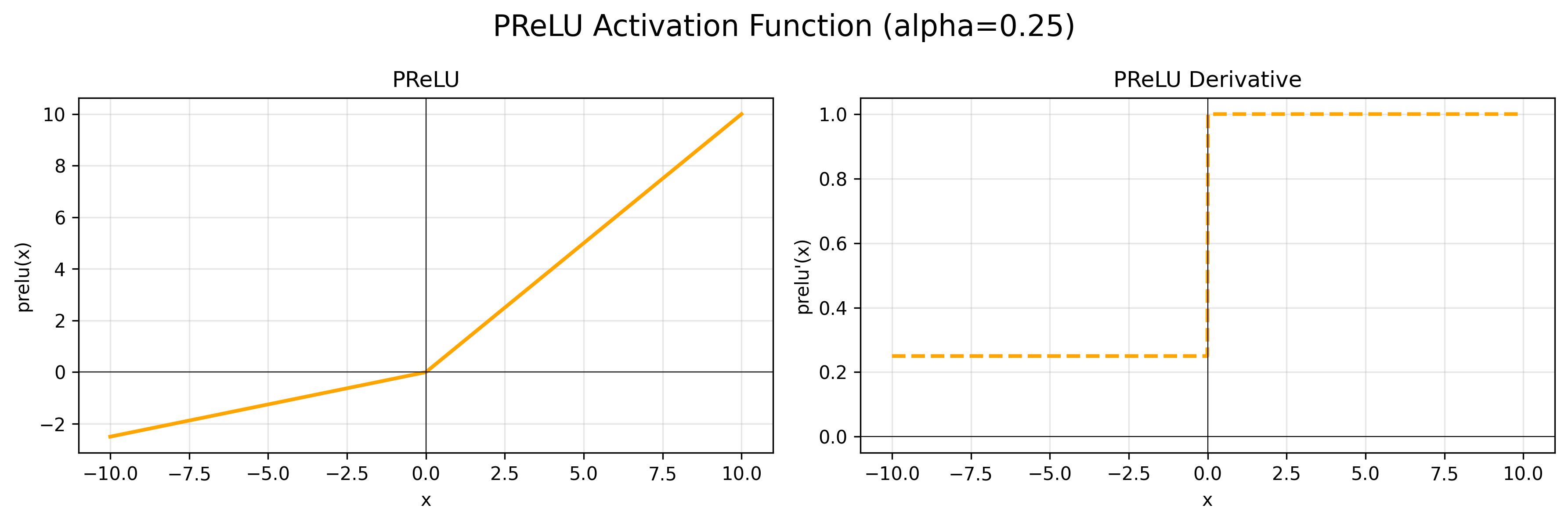
为了考虑负样本所以有了 PReLU(Parametric ReLU):
公式:$f(x) = max(0, x) + \alpha * min(0, x)$
导数:$f’(x) = 1$ if $x > 0$; $f’(x) = \alpha$ if $x < 0$
当 $\alpha$ 取 0.01 时,也叫 Leaky ReLU。
公式:$f(x_i) = \frac{e^{x_i}}{\sum_{j=1}^{n} e^{x_j}}$
导数:$f’(x_i) = f(x_i) * (1 - f(x_i))$
特点:将多分类结果按照概率输出,适用于多分类的输出层。
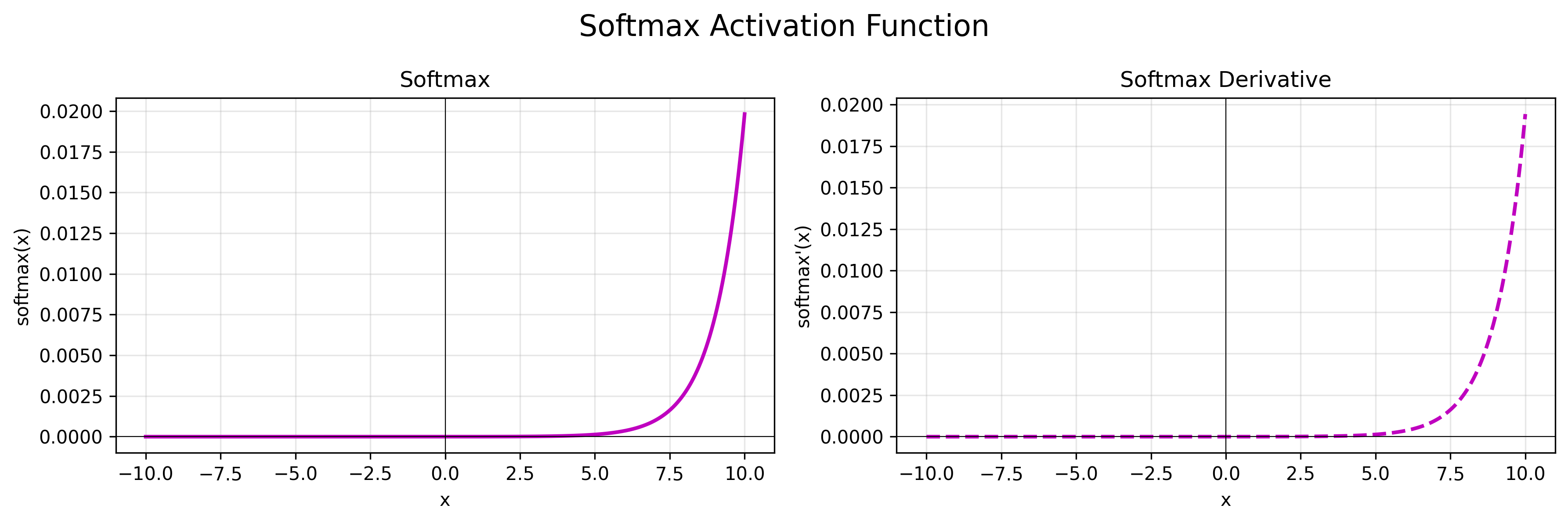
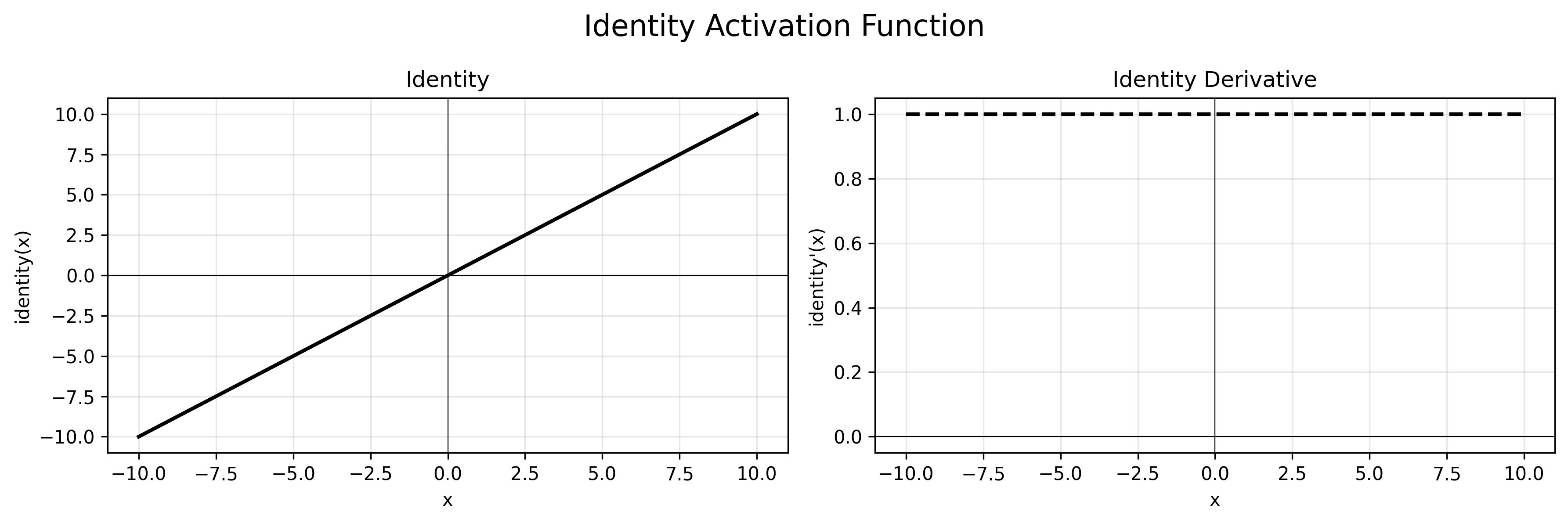
公式:$f(x) = x$
导数:$f’(x) = 1$
特点:无激活函数,直接输出,适用于回归任务。
激活函数的选取规则:
隐藏层:ReLU -> Leaky ReLU / PReLU -> Tanh -> Sigmoid
输出层:二分类 -> Sigmoid;多分类 -> Softmax;回归 -> Identity
公式:$L = -\sum_{i=1}^{N} y_i \log (S(f_{\theta}(x_i)))$
公式:$L = -y \log \hat{y} - (1 - y) \log (1 - \hat{y})$
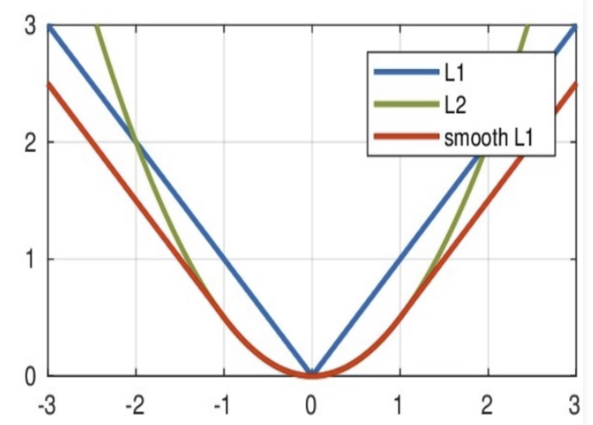
公式:$L = \frac{1}{N} \sum_{i=1}^{N} |y_i - \hat{y}_i|$
须有稀疏性,惩罚较大的值。梯度在零点不平滑,跳过极小值。
公式:$L = \frac{1}{N} \sum_{i=1}^{N} (y_i - \hat{y}_i)^2$
常常作为正则项,预测值和目标值相差很大时会造成梯度爆炸。
公式:
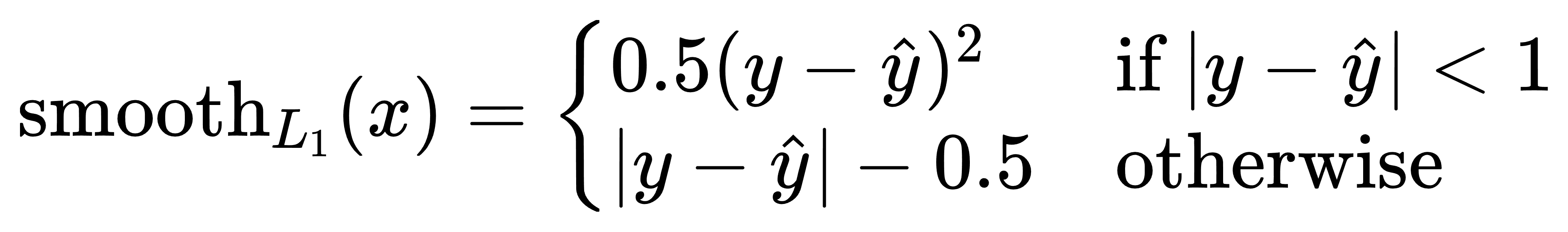
综合 MAE 和 MSE,解决 L1 不光滑和离群点梯度爆炸的问题。
指数加权平均公式:
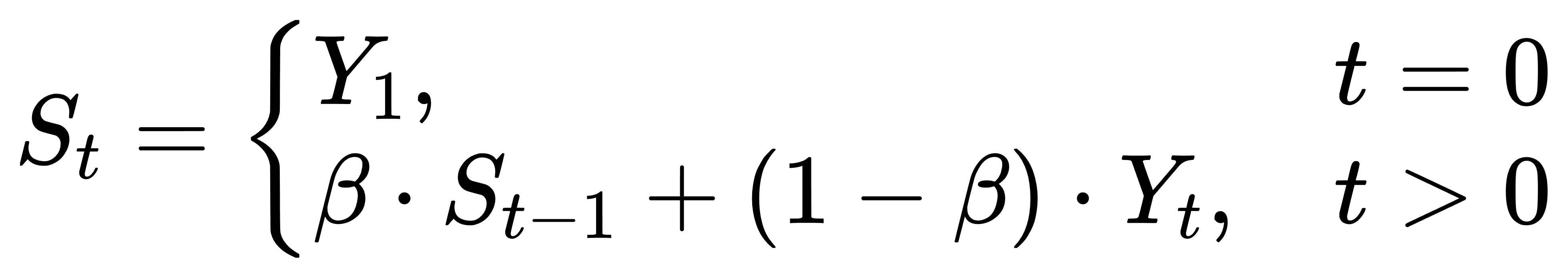
梯度计算公式:$s_t = \beta s_{t-1} + (1 - \beta) g_t$
更新公式:$w_t = w_{t-1} - \eta s_t$
缺点:学习率过早过量降低,训练后期学习率太小,难以找到最优解。
对 Adagrad 的改进,计算梯度时使用指数平均加权。
梯度计算公式:$s_t = \beta s_{t-1} + (1 - \beta) g_t \odot g_t$
学习率计算公式:$\eta = \frac{\eta}{\sqrt{s_t} + \sigma}$
权重参数更新公式:$w_t = w_{t-1} - \frac{\eta}{\sqrt{s_t} + \sigma} \cdot g_t$
将 Momentum 和 RMSprop 结合起来,计算梯度的一阶矩(平均值)和二阶矩(梯度的方差)的自适应估计:
梯度计算公式:
$$ \begin{align*} m_t &= \beta_1 m_{t-1} + (1 - \beta_1) g_t \ s_t &= \beta_2 s_{t-1} + (1 - \beta_2) g_t^2 \ \hat{m}_t &= \frac{m_t}{1 - \beta_1^t}, \quad \hat{s}_t = \frac{s_t}{1 - \beta_2^t} \end{align*} $$
权重参数更新公式:
$$ w_t = w_{t-1} - \frac{\eta}{\sqrt{\hat{s}_t} + \epsilon} \hat{m}_t $$
每隔一定周期,将学习率按固定比例衰减。例如每 50 epoch,衰减 0.5,学习率变化如图所示:
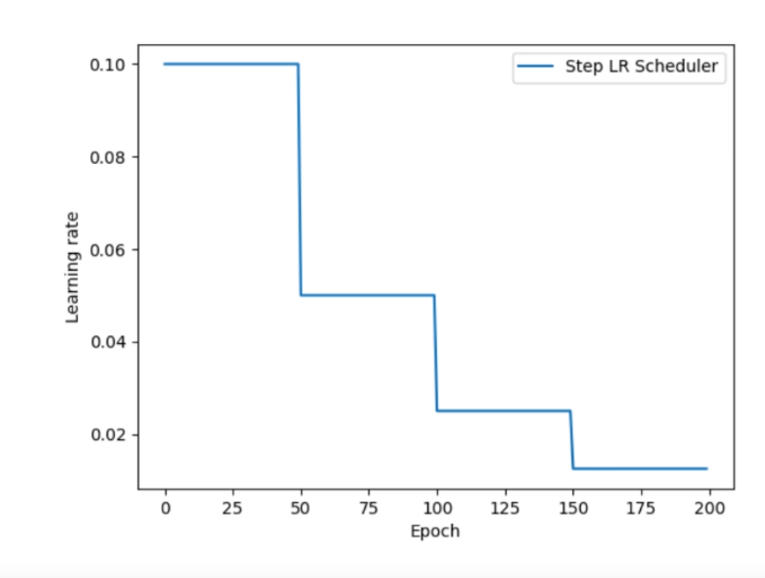
手动指定每隔多少间隔按比例衰减。例如按照图中 milestones 每次衰减 0.5,学习率变化如图所示:
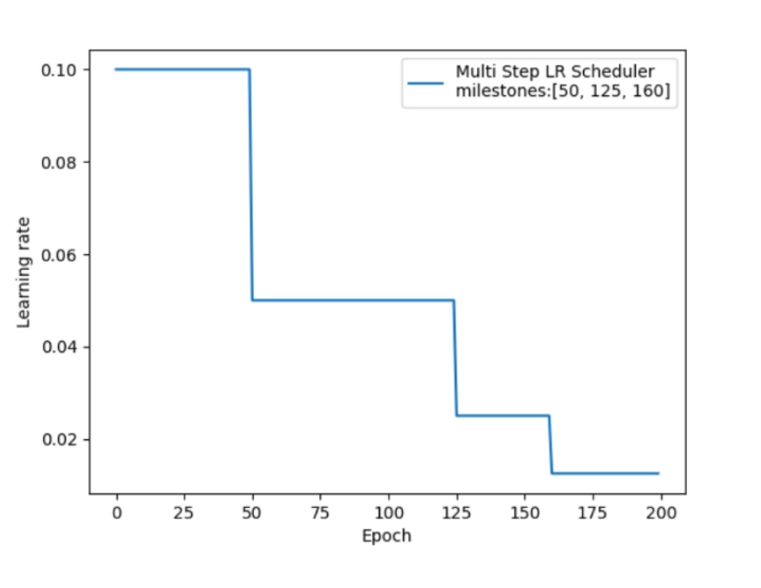
学习率按指数衰减。例如每 epoch 衰减 0.95,学习率变化如图所示:
学习率随训练周期变化,类似于余弦函数。公式如下:$\eta_t = \eta_{\text{min}} + \frac{1}{2} (\eta_{\text{max}} - \eta_{\text{min}}) \left(1 + \cos\left(\frac{T_{\text{cur}}}{T_{\text{max}}} \pi\right)\right)$
训练过程中,随机将部分神经元的输出置为 0,防止过拟合。dropout 率为 $p$,则每个神经元被置为 0 的概率为 $p$,通常为0.2到0.5之间。实际应用中通常在全连接层后增加 Dropout 层。
先对数据标准化,再对数据重构:
$$ f(x) = \lambda \cdot \frac{x - E(x)}{\sqrt{Var(x)} + \epsilon} + \beta $$
卷积神经网络 (Convolutional Neural Network, CNN) 是含有卷积层的神经网络,主要由三部分构成:
graph TB A[输入图像] --> B[卷积层:线性点乘求和] B --> C[激励层:激活函数映射成概率] C --> D[池化层:降维] D --> E[全连接层:输出结果] E --> F[输出结果]
卷积层(Convolutional Layer)通t卷积操作提取输入数据中的特征。利用卷积核对输入处理,从而生成特征图,并且每个卷积层能够提取到不同层次的信息,从低级特征到高级特征。
卷积运算:卷积核和输入数据的局部区域间做点积(对应位置相乘再求和)
卷积层作用:
Padding:在原图周围增加额外像素(通常是0)
作用:
类型:
Stride:卷积核在图像上滑动时的步伐大小
作用:
选择:取决于具体应用场景和网络架构。常见为1,尤其是网络的早期层,允许保留更多空间细节。大于1时用于减少特征图尺寸和增大感受野,例如网络后期层需要快速降维时常见设置为2或4。
先对应通道做点积,然后各通道结果相加
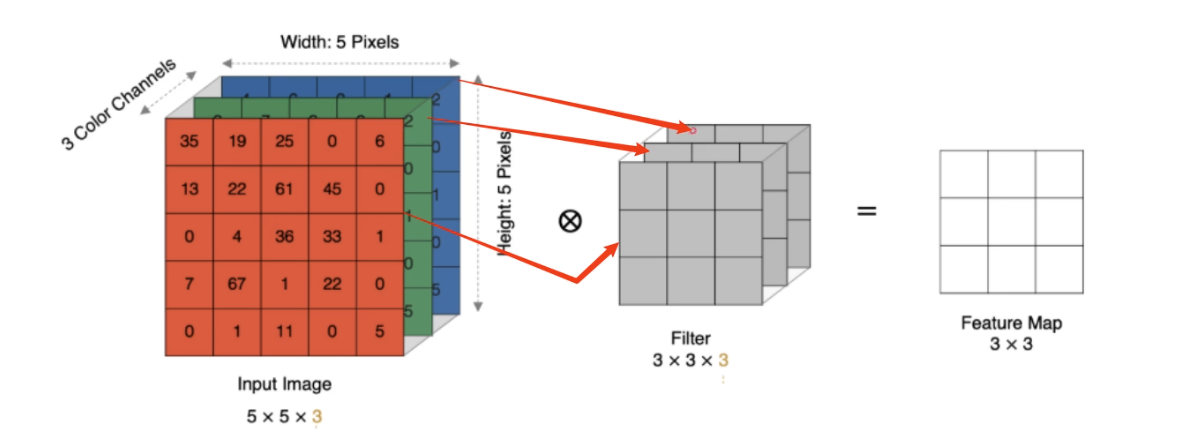
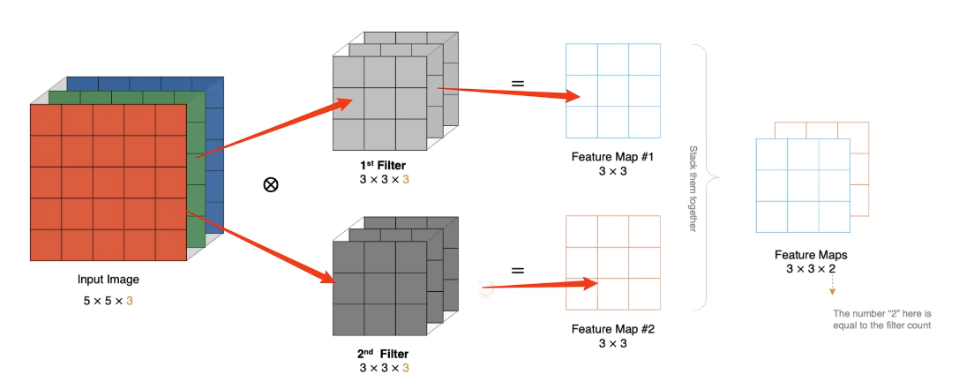
$$ N = \frac{W - F + 2P}{S} + 1 $$
降低维度,缓解过拟合,减少计算量和内存消耗
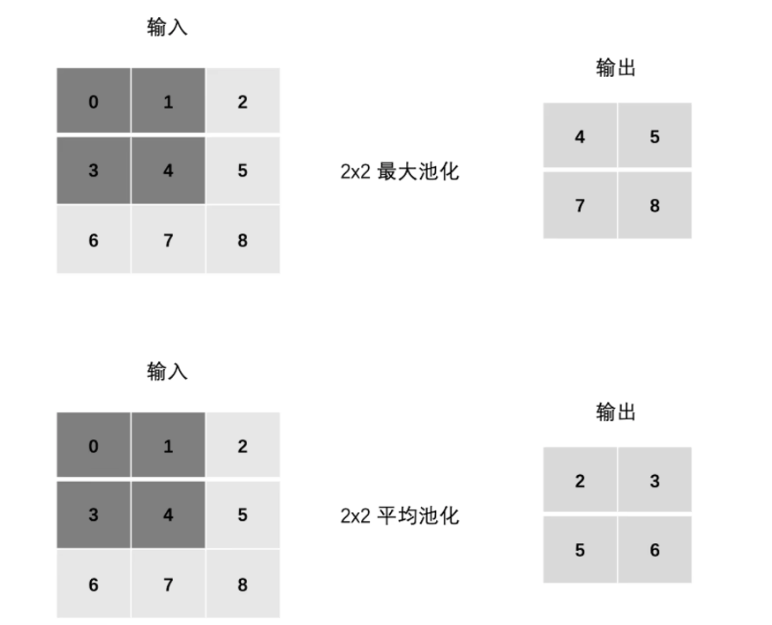
padding:
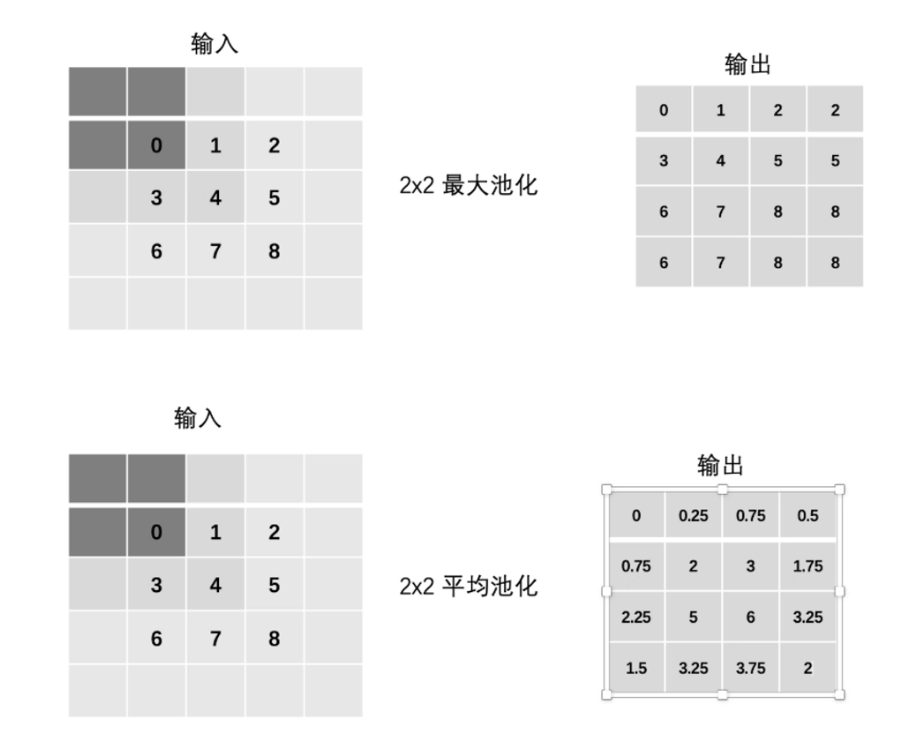
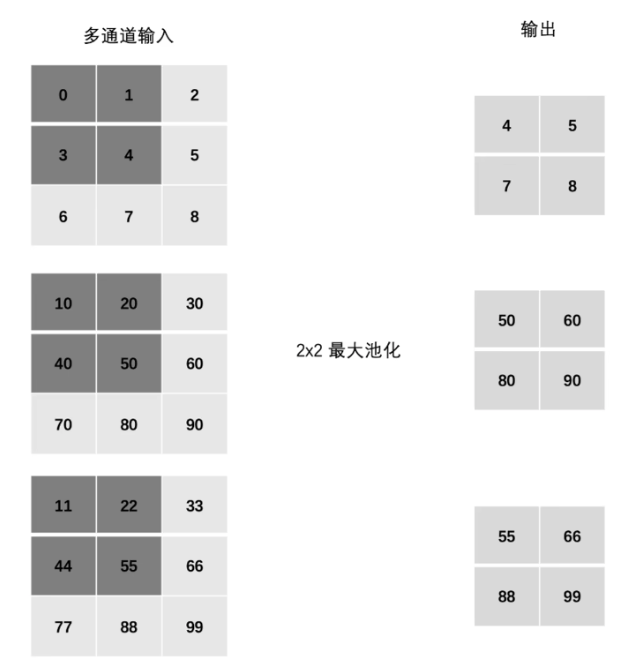
输入数据为多通道时,池化层对每个输入通道分别池化,不会像卷积层一样相加,所以池化层输入和输出的通道数相等。
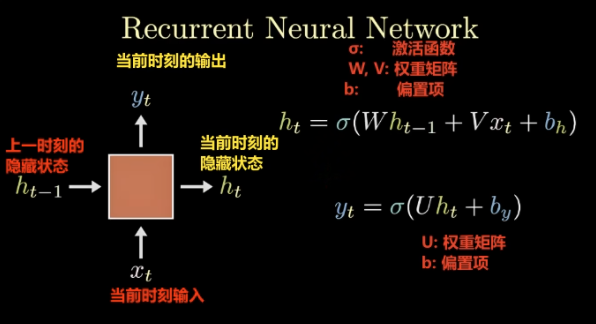
RNN(Recurrent Neural Network):一种专门处理序列数据的神经网络。
词嵌入层,将文本转换成向量,流程如下:
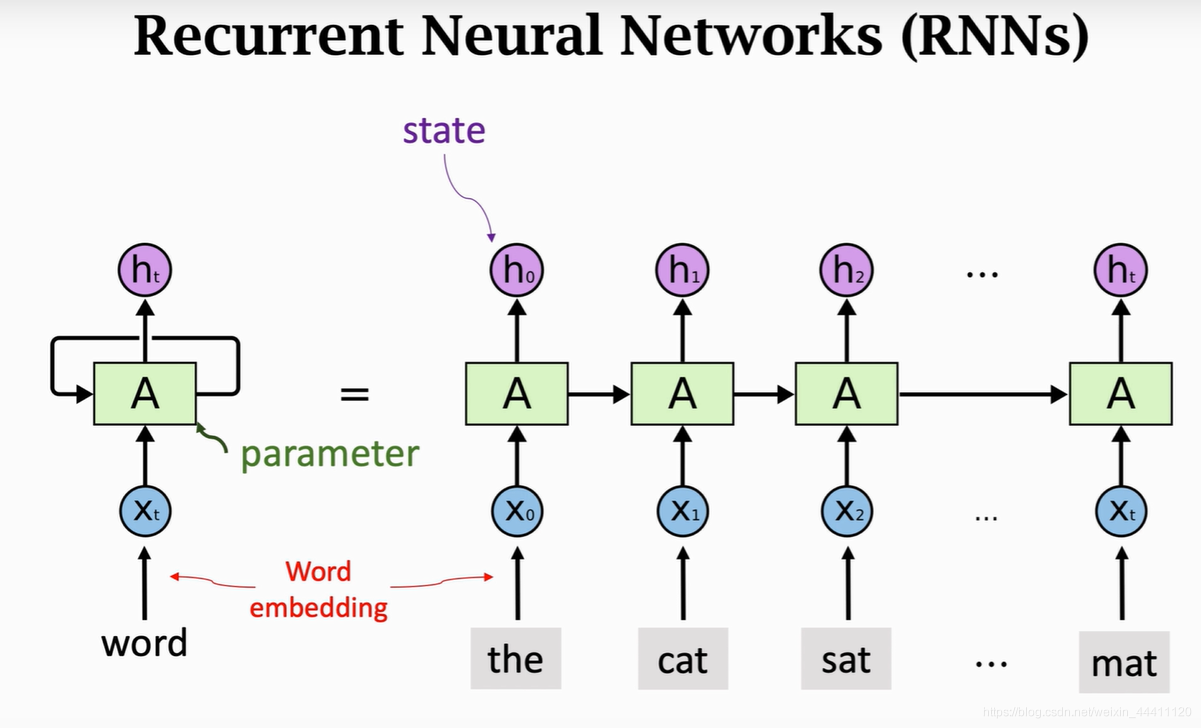
隐藏状态作用:
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。