折腾了两周,写写对 RAG 中检索阶段的一些实验总结。
数据集的选择:本实验采用 C-MTEB/T2Retrieval 数据集,以及 C-MTEB/T2Retrieval-qrels 是其对应的问题-答案对。
核心指标:recall@5、recall_cap@5 用于评判召回质量,因为一个问题对应原始文档过多,所以下文都将以 recall_cap@5 为主要参考指标,其中 cap=5。
其他指标:mrr@5、ndcg@5、precision@1 用于评判排序质量。
Embedding 模型:BAAI/bge-m3 可以同时输出 sparse 和 dense 向量,在训练时两个向量有互补,所以查找时效果也会更好,实测混合检索用 sparse 替代 bm25 可以提升 ~3%。
Reranker 模型:BAAI/bge-reranker-v2-m3 很好的模型。
下面是 C-MTEB/T2Retrieval 数据集的一些测试结果,指标说明在图下方,测试数据库为 Milvus,原始语料库 ~12w 条,分块后存入数据库 ~36w 条数据,测试时使用前 2000 条 query 测试:
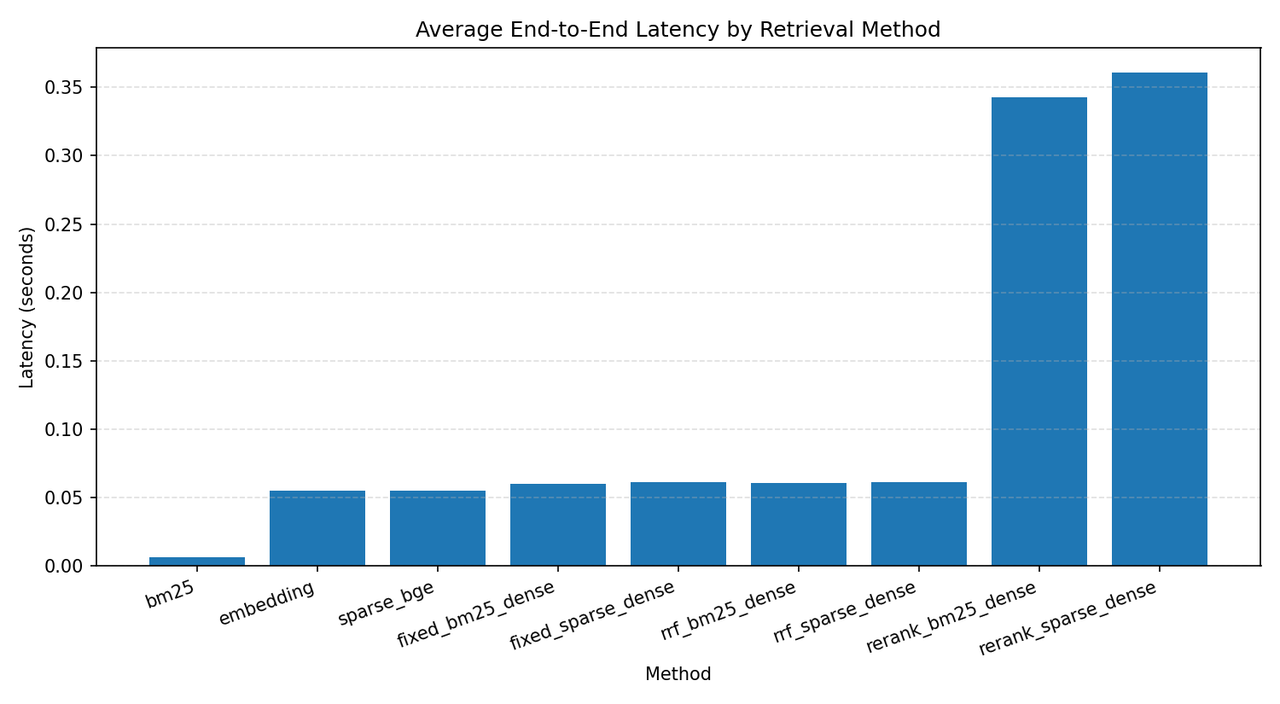
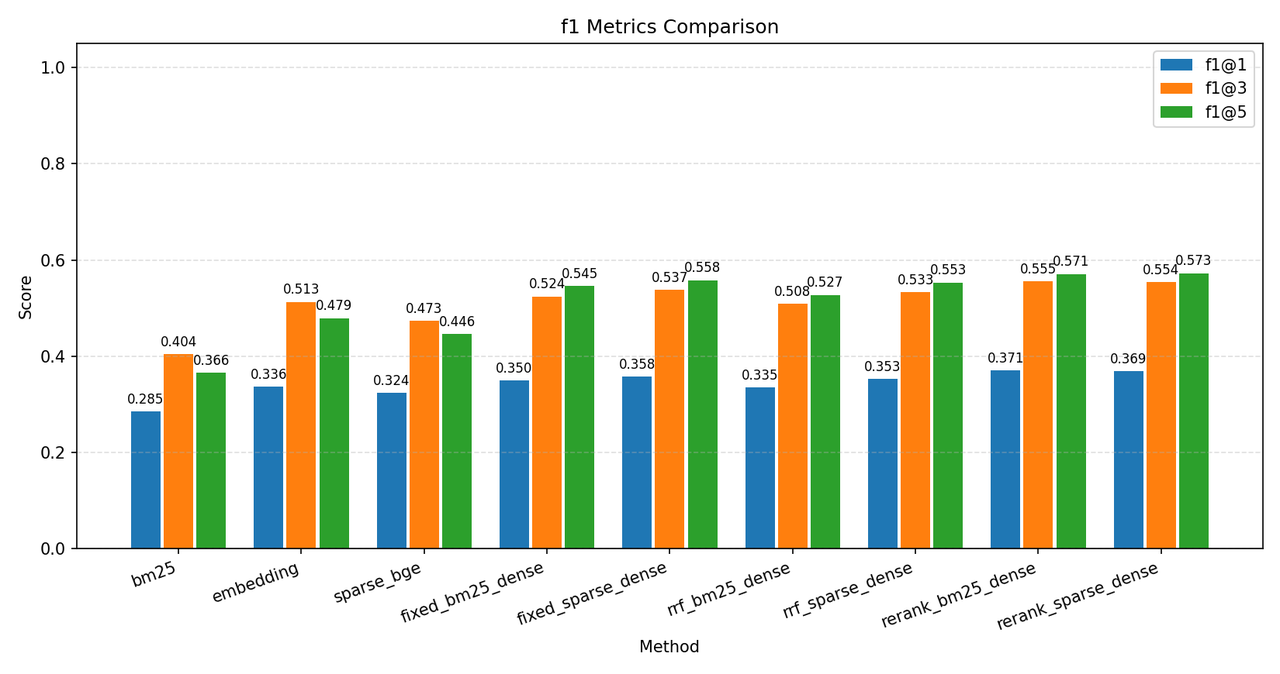
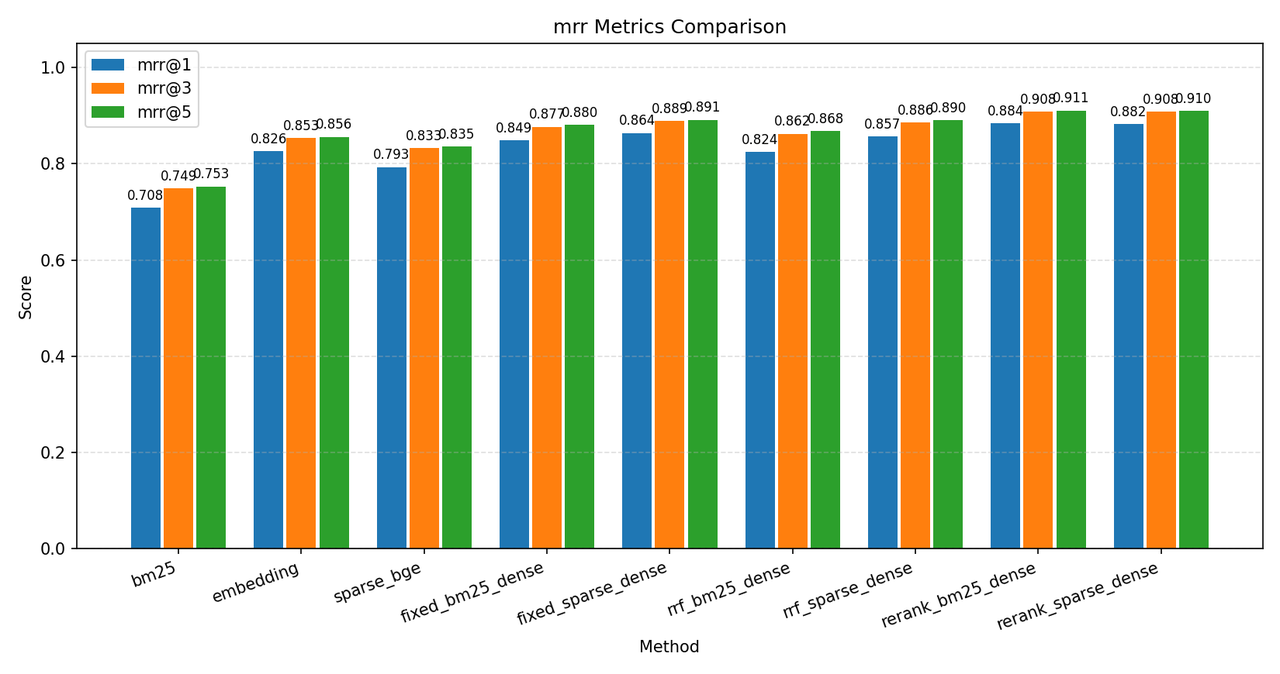
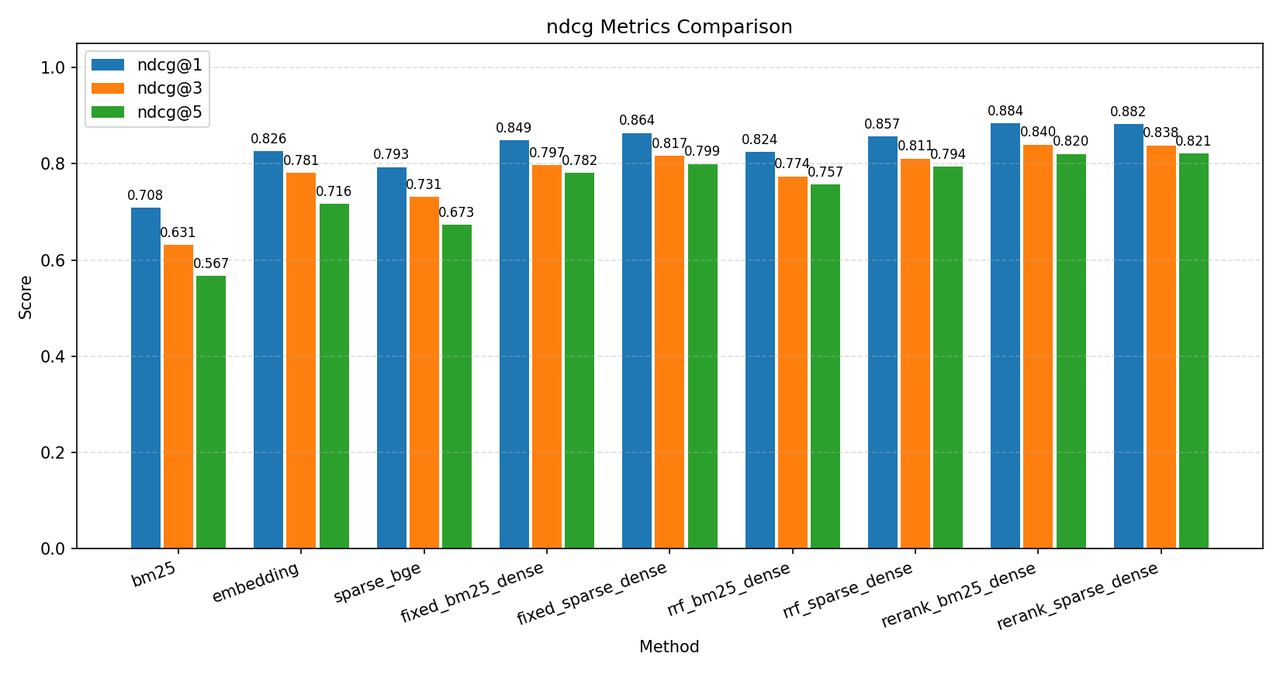
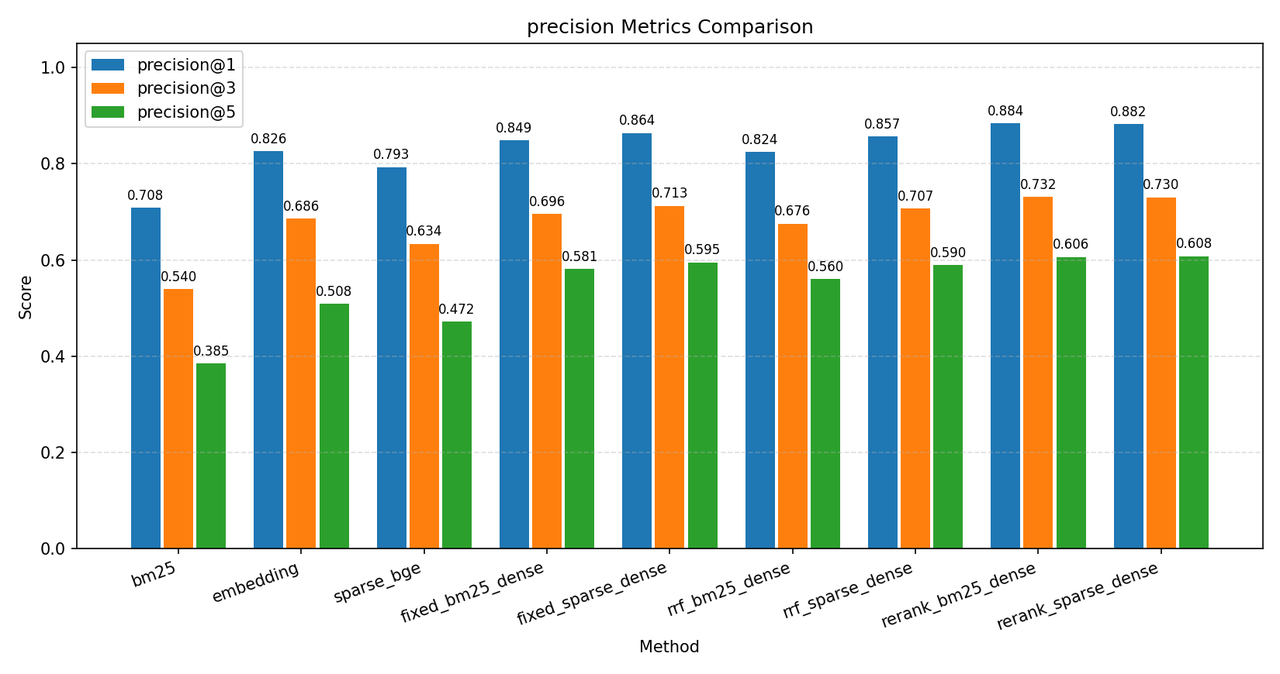
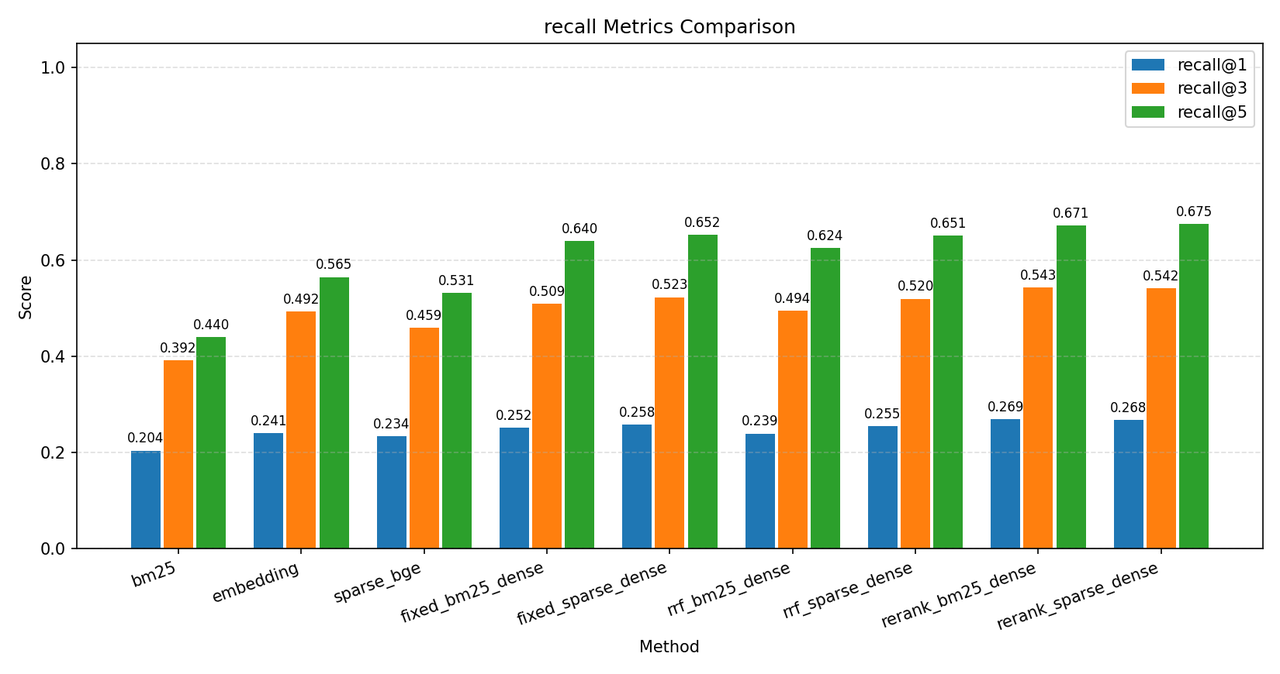
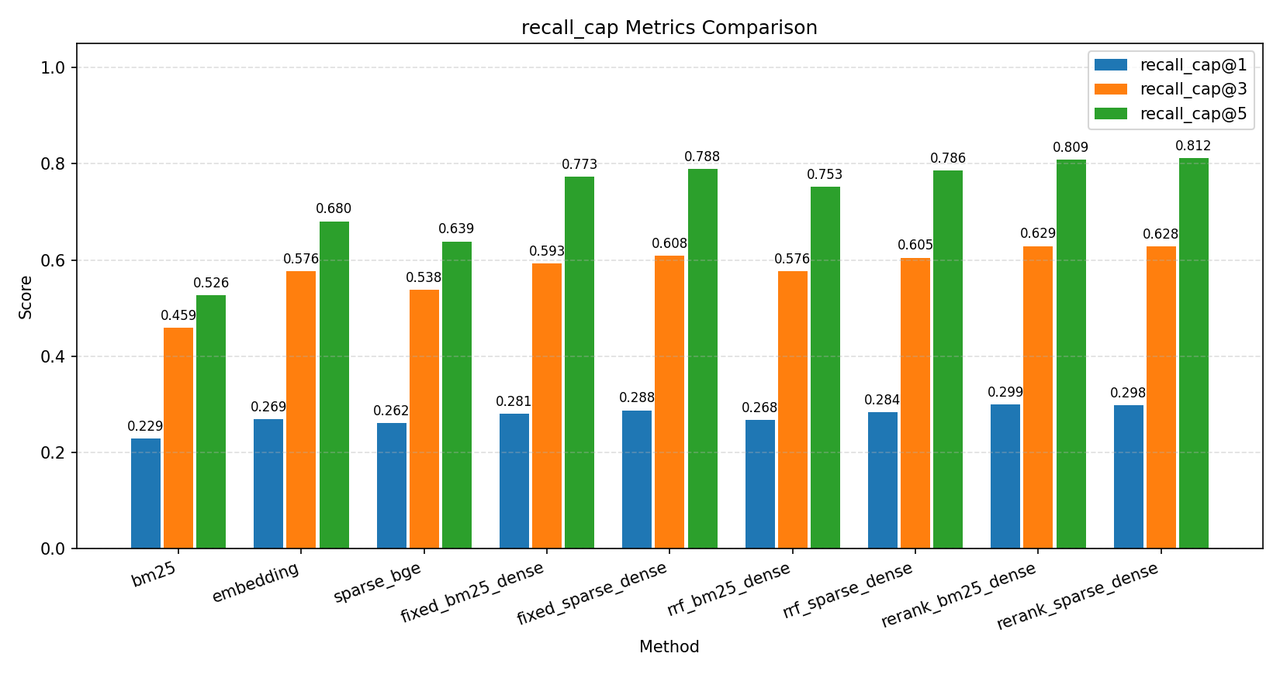
其中各个环境说明如下:
bm25:通过 bm25 检索
embedding:通过 bge 生成的 dense 向量检索,数据库索引为 HNSW
sparse:通过 bge 生成的 sparse 向量检索
fixed_*:混合检索后通过固定权重聚合 0.6*dense + 0.4*sparse(milvus会在聚合时对分数进行归一化 )
为什么叫 fixed,当然是因为还有 dynamic,后续会讲
rrf_*:混合检索后通过 rrf 聚合,k=60
rerank_*:rrf 混合检索后再经过 rerank 模型重排序,重排的候选集为 50 条
目前在实验中表现最好的方案为使用 sparse+dense 混合检索,rrf 聚合后通过 reranker 重排,整套方案有提升的部分如下:
其中 rerank 部分需要注意:增加了 rerank 后,耗时从 ~60ms 增加到 ~360ms,各项指标均提升 ~3%(sparse+dense+rrf+rerank 方案为例),整个 RAG 系统中这个耗时可以接受,所以引入 rerank 是值得的。另外需要注意的是:
综上,从之前的实验以及分析可见,给 bm25+dense+rrf 加 rerank 最能体现出 rerank 提升的效果。
最终结论,以单纯的 dense 向量检索为 baseline,本实验通过增加 sparse 混合检索和 rerank,将 recall_cap@5 从 68% 提升到了 81.2%,ndcg@5 提升了10个百分点,mrr@5 和 precision@1 也各提升了5个百分点。
尝试过提升指标的方法:
优化数据分块方法。开始使用固定 chunk 大小+overlap 的方式分块,效果不太好(不过后面发现了是使用的数据集有问题)。现在最终版实验是采用了 递归分块+固定 chunk 大小+overlap 的方式,即:优先根据段落、句末标点分块,无法分割的再回退到简单切割的版本。
调参。混合检索时可以调整权重或者rrf的k值,经过测试来看,默认的 0.6/0.4 和 60 效果最好。
增大 Rerank 候选池。因为引入了重排序,于是思考扩大候选池是否对结果有提升。答案是:有的,但是会有边际效益。当候选集从 10 增大到 50 时,会有正向提升,但是 50 增大到 200 甚至 500 时,时延增加了十几倍,指标反而下降了。由此可见,过多的候选集不仅会增大模型的计算负担,过多的噪声还会让模型迷惑。
Dynamic weight 聚合:原本想过是否可以通过计算句子复杂度动态调整权重,语气词/连词/长词越多则 dense 权重更大,但实际测试效果不如 fixed,因为有些专业词语虽然是长词,但是显然更应该用 bm25 这种稀疏向量去硬匹配
Query 扩展:试过本地起一个 Qwen/Qwen3.5-35B-A3B 模型用更加标准的句子对query进行扩展以更好地命中数据库中的数据,例子如下:
原句为:
我想知道现在大模型在机器翻译中是怎么使用的?可以结合实际例子说明吗?
扩展为:
- 我想知道现在大模型在机器翻译中是怎么使用的?可以结合实际例子说明吗?
- 大语言模型在机器翻译中的应用方式及案例分析
- 当前大型预训练模型如何用于机器翻译,有哪些实际案例
- 机器翻译任务中集成大模型的技术路径与实例说明
但是实际测试中效果并未提升太多(<1%),同时因为引入了大模型,耗时从 ~360ms 飙升至了 ~70s,这对系统的影响将是巨大且不可接受的。
未尝试但或许对指标有提升的方法:
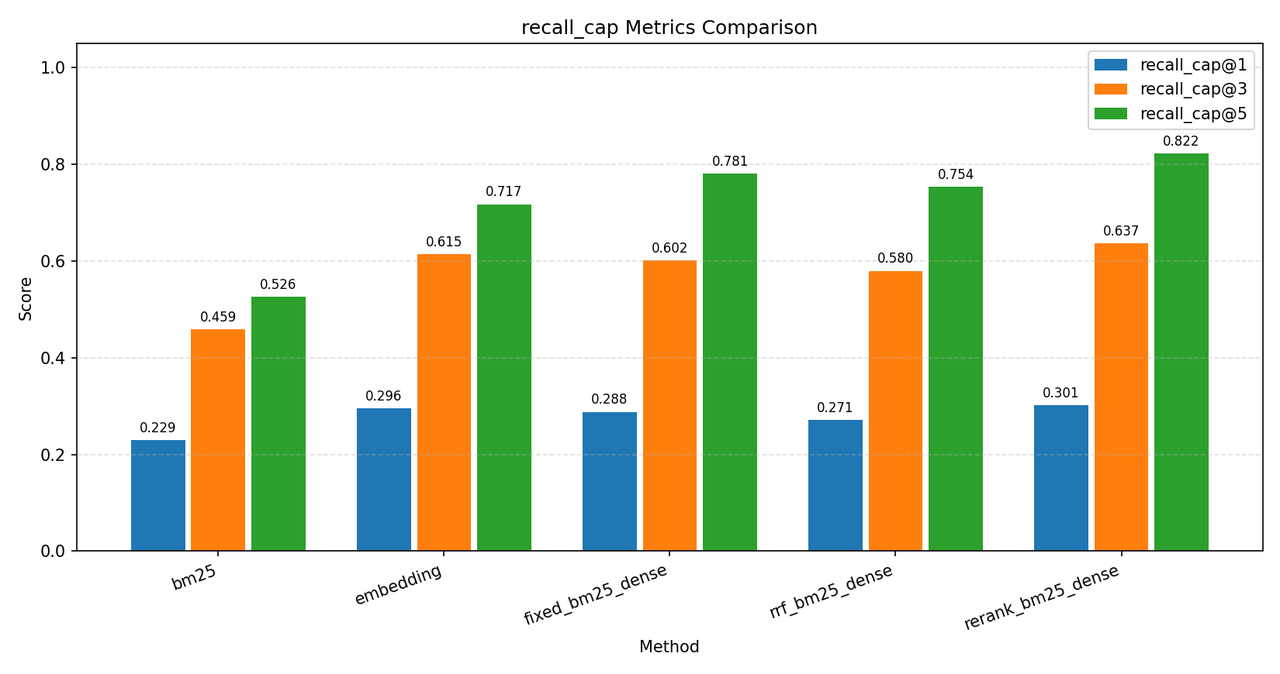
后来用比较新的 jinaai/jina-embeddings-v5-text-small 和 jinaai/jina-reranker-v3 两个模型又跑了一次实验,因为 jina 没有生成 sparse 向量,所以使用 bm25 代替,最终结果最好的方案为 bm25+dense+rrf+rerank,并且结果与上面用 bge 模型的结果相同,recall_cap@5 均为 81.2%。
在对这次实验结果分析后,我有了一个猜想:bge-reranker-v2-m3 的性能或许要比 jina-reranker-v3 要好,于是使用 jina-embedding 与 bge-reranker 配合重新又跑了一次实验,最终得出了本次的最高分:82.2%,详细实验结果如下:
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。