
If you were building health care apps in the 2010s, you probably ran into some version of this problem:
build a standard patient data integration (FHIR, etc.)
tell a clinical client you have data integration, sign a contract
find out that they do the standard differently and your integration doesn’t work
build a custom parser for their “snowflake standard”
monitor the parser & update when it breaks
believe that now you’ve seen everything and that this software will cover you for all future clients
be constantly disabused of (6)
Eventually, you end up with thousands of lines of code that look like this:
Fun! When people set out to build better health care software, I’m pretty sure this is exactly how they pictured spending a good chunk of their time. Still, it was table stakes for a lot of the work.
In the age of AI, however, it isn’t anymore.
If you are now thinking “okay, I see where this is headed: have AI coding agents build and fix the parsers, it’s easier now,” you are wrong. Something MUCH more interesting is happening here, and not enough people are talking about it. In what I’m seeing with clients — and in what I’m doing myself — engineers are adding AI calls into their software to trade raw efficiency for flexibility.
It’s something I’ve been calling *elastic software*, and it’s completely transforming how startups build and scale to market.
I think the power of elastic software is best shown by example. Let’s pretend we have a new health tech startup creating a data integration like the one I mentioned in the last section. Instead of the code above, they might do this:
And that ai_parser can be nearly as simple — here using the RubyLLM gem:
And that’s it! Maybe the AI will choke a few times, and you will need to tweak the prompt based on results and failures, but it’s pretty quick and easy to get this running. You have a functioning parser running in minutes with maybe a dozen lines of easy-to-maintain code.
Got a new client coming online? Skip the long “please send us sample data to test integration with” discovery process! Just make sure you have your BAA with the inference provider signed and you are good to go.
The power of process reordering goes further: Is it getting really expensive to use inference to ingest ALL the inbound data? Likely, just a handful of clients are responsible for the vast majority of your data. Find out who they are, use the production data you are gathering to build a really solid spec for a parser, and then just update the pattern to catch those and process them efficiently first:
Now you have scalable, cost-efficient processing for the 2 clients that are 80% of your volume, and a flexible solution for the 8 clients that make up the tail 20%.
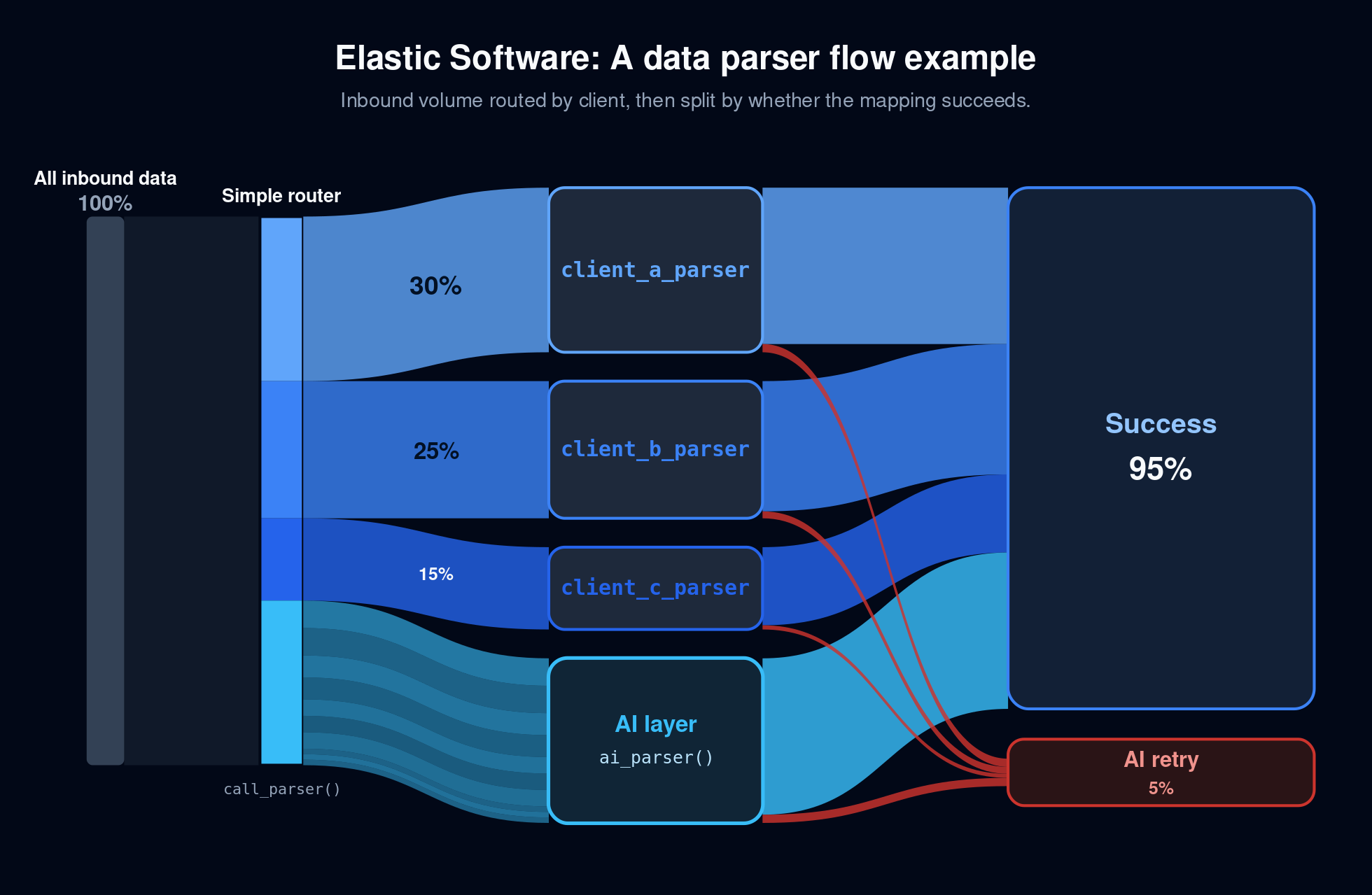
That’s the “elasticity” of this type of software. You start stretched all the way toward flexibility: let the model handle it, accept a higher per-request cost, move fast. Then you contract toward efficiency as the math justifies it: build the custom parser, drop the AI call, push the per-request cost toward zero. And you do this independently for each integration, each data type, each client — never all at once, never up front.
Everything else keeps flowing through the AI layer while you wait for the next optimization opportunity to reveal itself.
So how do you decide when to optimize? That’s where this gets really interesting.
Startups have long practiced their own crude version of elastic software — they just offloaded it onto human ops. This has variously been called “scrappiness” or “doing things that don’t scale,” but the rundown is the same: you get the data, give it to a human to handle, then automate when it stops scaling. It’s slower and hits a scaling limit faster than AI, but more or less measurable: “how many human hours is it costing to do this and is having an engineer build and maintain it a better use of resources?”
What’s amazing about elastic software is that the opportunity cost can be calculated far more precisely, using tokenomics:
On the AI side, you know your average cost per request for each integration. Break it down by client or hospital system, multiply by volume, project it forward on your growth assumptions, and you’ve got a clean, compounding monthly and annual number for keeping that integration in the flexible layer.
On the software side, you can measure what the parser actually costs: from the moment you kick off the agent to write it, through code review, to production — and then the ongoing drag of bug reports, maintenance cycles, and the new data type that lands six months later. Those are real engineering hours, and in an AI-assisted shop, hours increasingly carry a real token-equivalent cost too.
So the comparison gets refreshingly boring:
AI path: $X per request for this workload.
vs
Software path: $Y to build + $Z/month to maintain.
(It’s worth saying that calculating the cost of that AI path — per-request cost broken out by specific workload type — is a feature Coolhand Labs offers out of the box. I’d be lying if I said the pattern and the product weren’t shaped by the same frustration.)
Of course, this doesn’t capture every variable — the cognitive load of one more system to hold in your head, the context-switching tax, the morale cost of asking a good engineer to babysit another brittle parser. But those are tiny relative to what the token costs can now represent. The elastic tokenomics framework gives you a signal strong enough to make a justifiable call that you can defend both to your product & engineering team and to your CFO.
Optimizing cost is useful. But if you’re building a startup, I’d argue it’s the smaller half of the story. The bigger unlock is speed.
Think about what this changes operationally. You close five new hospital systems in a single month — a great month. In the old world, that’s a scramble disguised as a celebration: who do we build parsers for first, how do we sequence it, and how long until those clients go live so we can start realizing the revenue? Your best month creates your worst backlog.
In the elastic model, all five go live immediately. The AI layer carries their data from day one. And instead of betting up front on which of them deserves engineering time, you start collecting the only thing that can actually answer that question: real volume, real usage, real economic signal. If one turns out to be a monster account, the tokenomics will surface it pretty quickly. If one churns in month two, you never wasted a line of parser code on it.
And this goes in the opposite direction as well. Are you an enterprise drowning under the weight of maintaining 1,000 legacy parsers? Find which ones sit at the tail of your data-usage curve, re-route them to an inference request, delete the code, and stop living in fear of tiny client X throwing off your sprint planning when they discover that a change they shipped last year has left your integration broken for two quarters.
Whether it’s faster time to market or less maintenance overhead pulling your engineering capacity away from growth features, elastic software is ultimately about increasing velocity.
There is, of course, this design pattern is very much in its adolescence. I get asked a lot of questions by Coolhand Labs clients implementing some version of elastic software in their own specific flows, including:
What are the real failure modes? What does good monitoring look like across a hybrid system with AI and hardened software paths running side by side?
How do you handle drift — the AI layer quietly making different mapping decisions this month than it made last month — with no diff to review?
What’s the right ops sampling rate to catch a prompt regression before it compounds into a thousand mis-mapped records?
How do more complex elastic patterns survive contact with regulated environments, where failures need to be justified to an auditor?
These aren’t rhetorical. The teams I see doing this well are still working them out in real time. What separates them isn’t that they’ve got the answers — it’s that they’re treating elastic software as a genuine architectural commitment, with the monitoring and discipline that implies, rather than a clever hack they bolted on to ship faster and hoped nobody would ask about later.
If you’re building on this pattern — or fighting with it — I’d genuinely like to hear where it’s breaking for you. Reply, or drop it in the comments. This is the kind of thing that only gets figured out in the open.
Michael Carroll is the founder of Coolhand Labs, which gives your agent teams an AI COO. He previously built eConsult pioneer RubiconMD, where he wrote enough EHR parsers to personally stress-test the elasticity of his left eyelid (it still twitches when somebody says “FHIR”).