Everyone I’ve talked to in AI has always assumed that the future of AI is bigger models held by a smaller number of players. I get it… they can see a very strong trend over the last 10 years, and they bring that view to every AI regulation, investor strategy, VC pitchdeck, and futurist prediction.
But they couldn’t be more wrong, and now the numbers are showing it. Networks of smaller AI models are outperforming every frontier AI system (Fable/Mythos included) on speed, accuracy, and cost.
IBM, the US Government, Bell Telephone, Bell Labs, and everyone else was wrong in the 1960s about the mainframe computer… and everyone is wrong today about centralized AI. The future is a network of neural networks. It’s a PC+Internet of AI. The future is not open or closed source AI… it’s network-source AI.
If “The AI Race” is a race to maximize AI capability/speed and minimize cost… and if AI users fundamentally either look for the MAX capability possible… OR they follow the best deal (capability+speed) at the lowest price (cost), then the centralized AI race is over, and decentralized AI has definitively won. To see why, look at each one by one.
Networks of neural networks are now faster, cheaper, and more capable than any Frontier AI system. The game is over. I’ve personally tested this myself, and it’s also bearing out in multiple corners of the internet. Here’s one that dropped today:
Not only does it show how to exceed the accuracy of the best models, it beats the best models at half the price. I personally used this same technique 6 months ago. At the time, here were scores of frontier AI models on the multiple-choice section of humanity’s last exam.
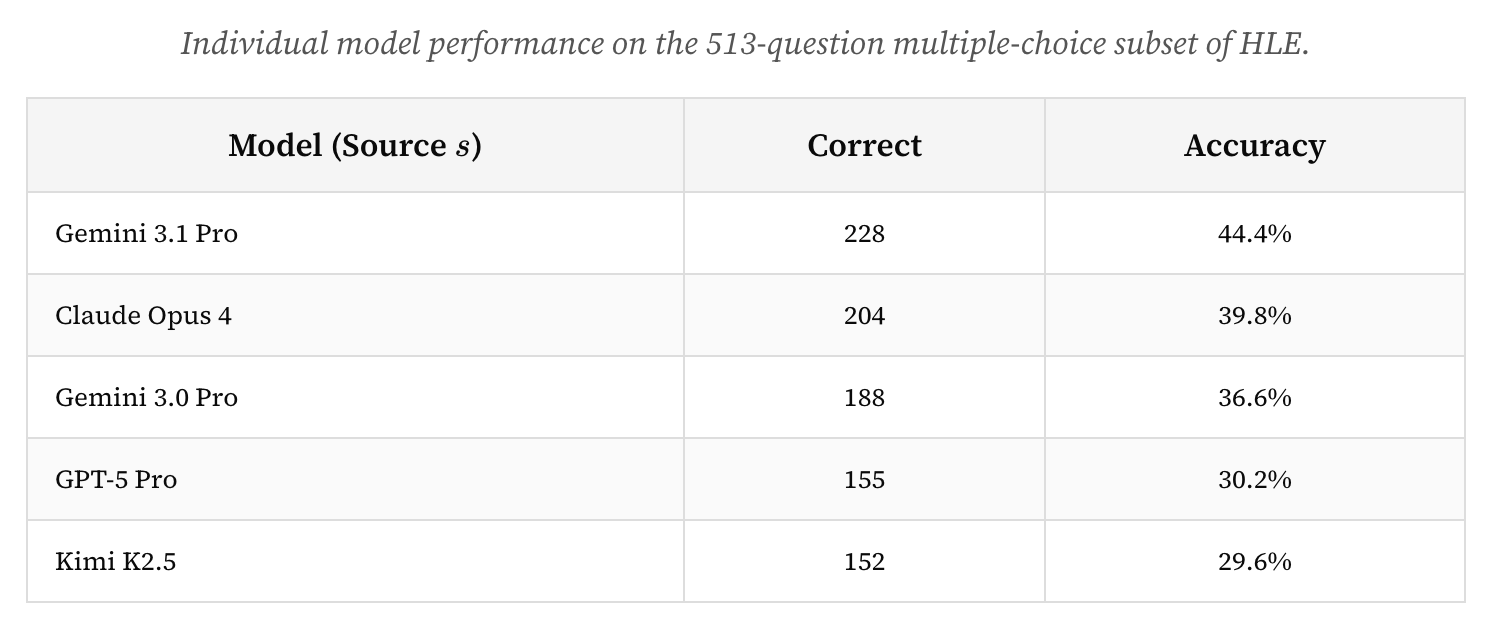
And… a differentially private combination of them reached into the low 50s!

Here’s a Stanford student doing it and launching a startup.
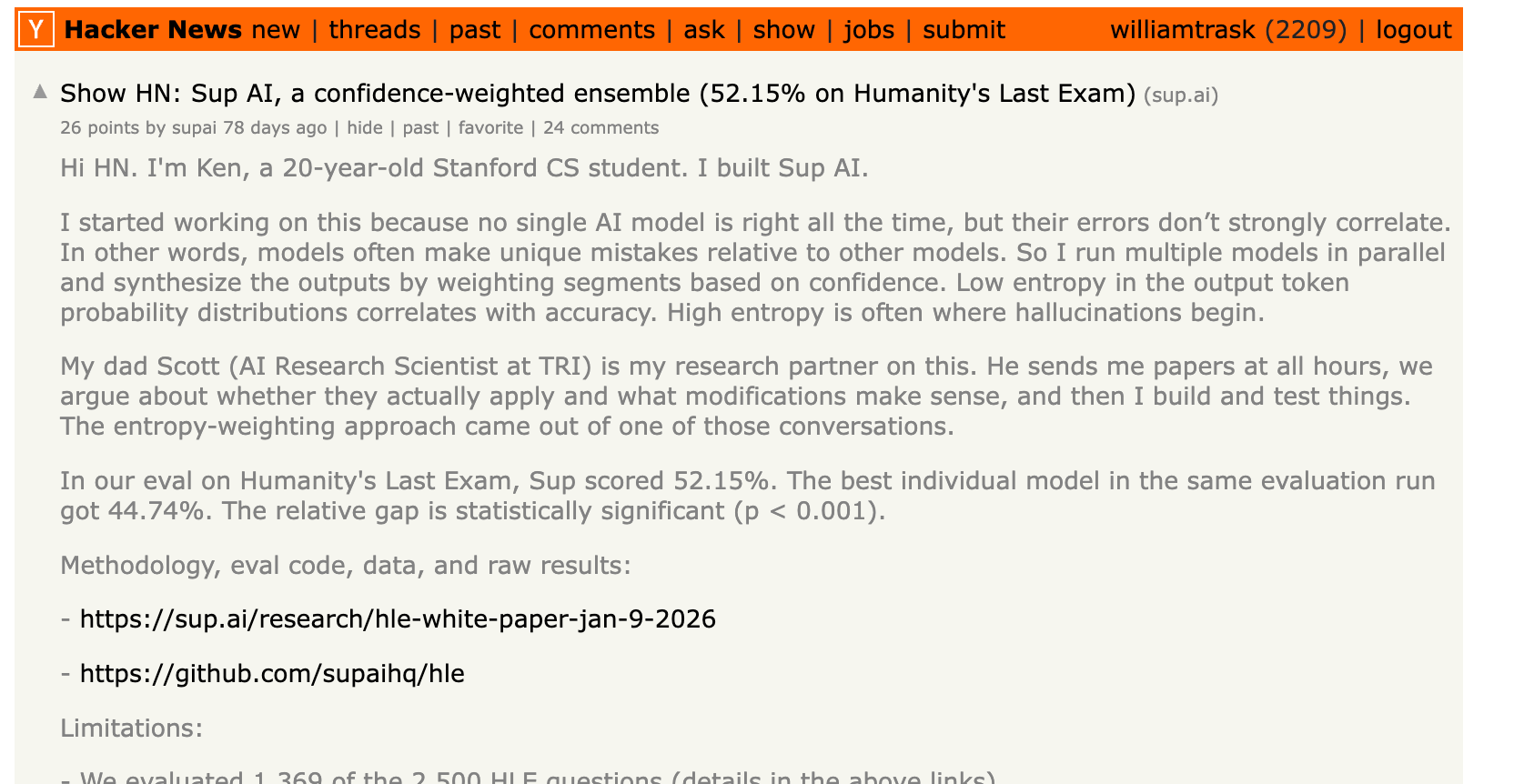
Bottom line… if you want the most capable AI system in the world… from TODAY onwards… you can only get that from a routed/weighted ensemble of weaker AI models. No single frontier AI system will ever achieve the capability frontier ever again because of how the scaling laws / ensembles work (more on that below).
Open source models are simply faster, in part because the people who host them are only in the business of making money by delivering crazy fast/cheap results. Don’t believe me? OpenRouter has independent ratings (note: this is different than the corporate sales pitch by these companies… this is what actually happens in practice).
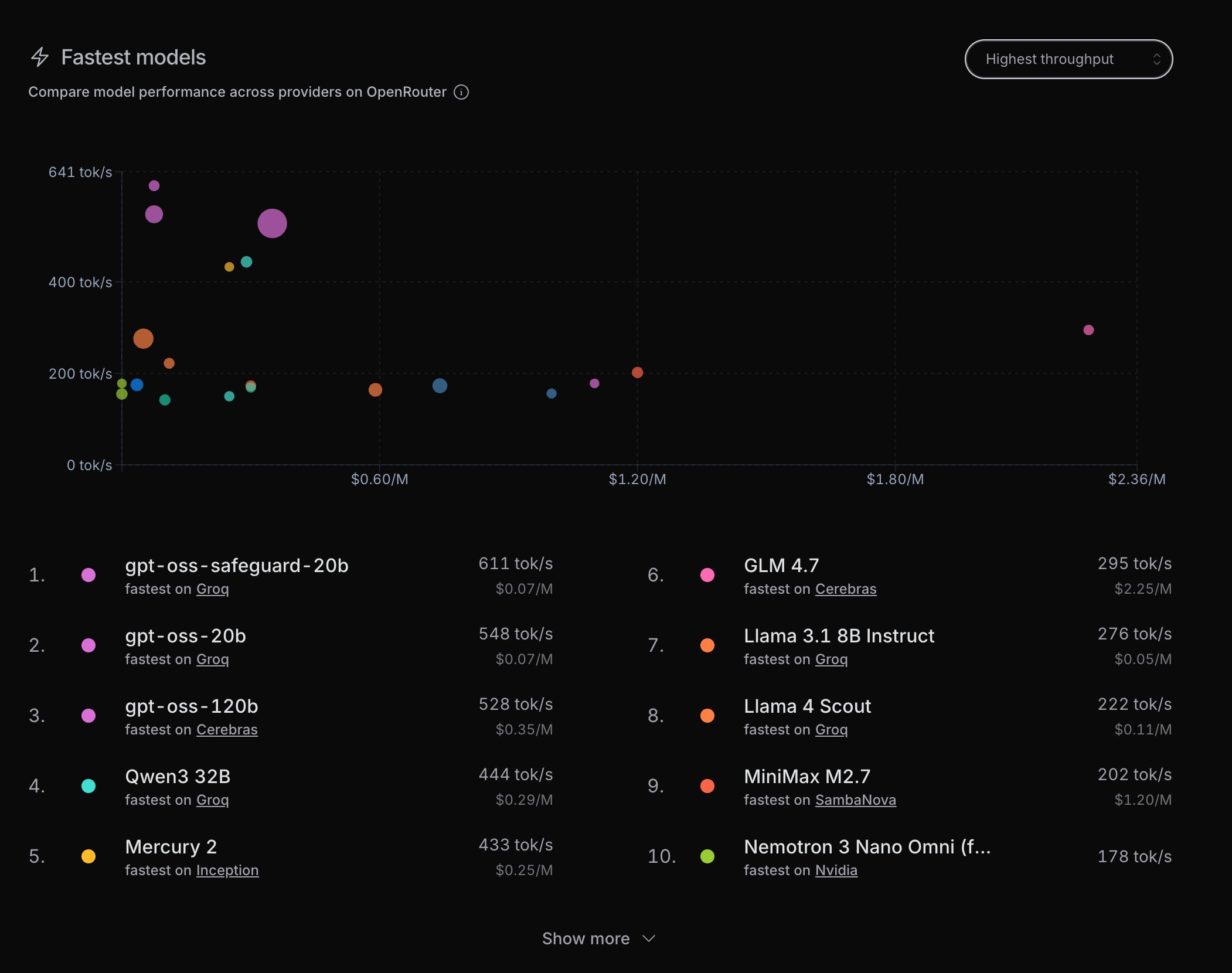
Open source models are offered at the cost of inference (with training being given way for free). Industry-wide, pound for pound, they’re cheaper for the same level of intelligence… but previously they there was a GAP where centralized AI was the only way to achieve the highest levels of intelligence:
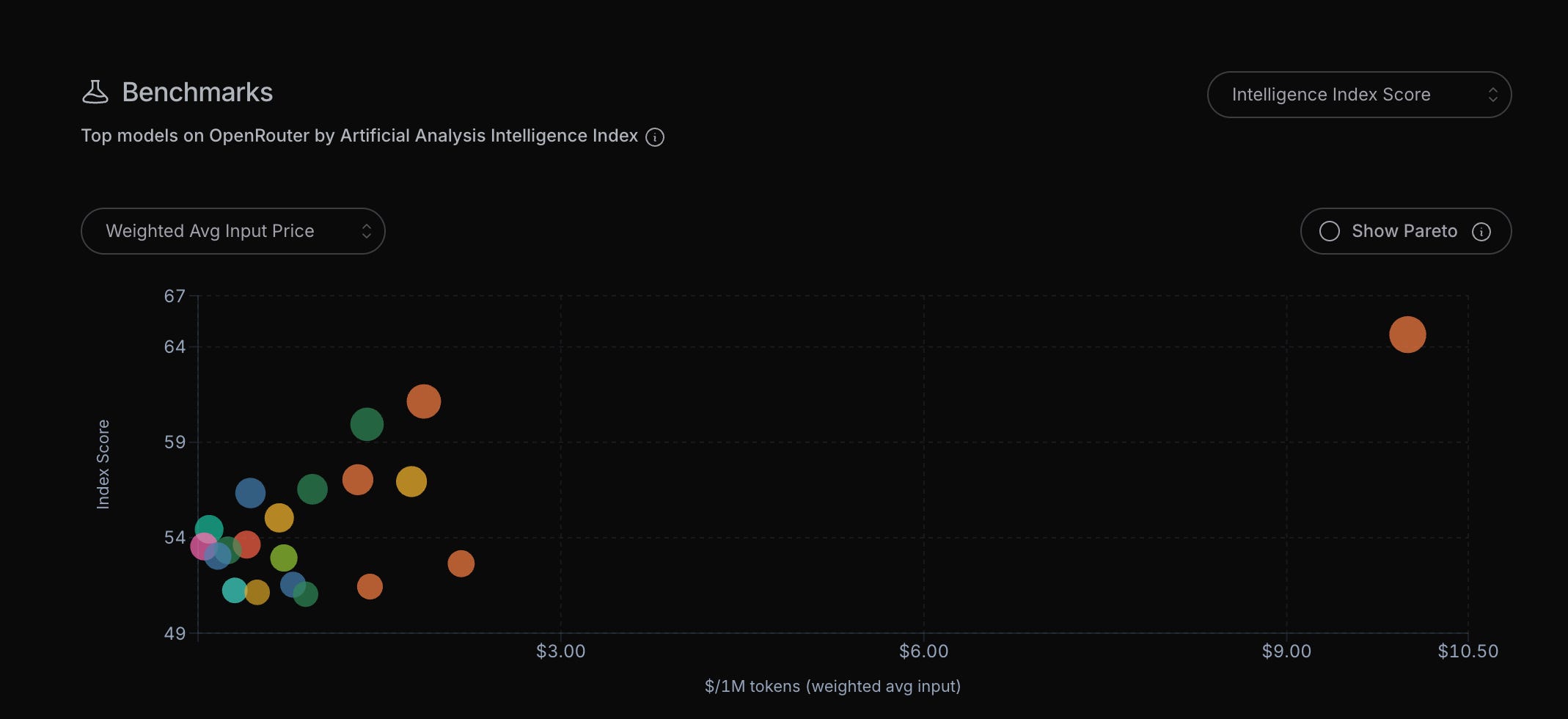
But now this chart is being overwritten… because a different kind of decentralized AI is emerging… At the time of writing, the cheapest way to get Fable/Mythos level performance… is NO LONGER FABLE/MYTHOS… it’s basically any permutation of GPT and Opus (including Opus with itself!).

And here’s what they left out of this chart… if they added even more models… the capability would keep going up (I know this because I did these experiments myself 6 months ago). For example… you might be questioning this list above because it mostly features closed source models… but the latest Kimi model just dropped TODAY… which will undoubtedly combine with Opus or GPT-5.5 to be Fable-level while being even cheaper. Why do I know this? Because Kimi K2.7 is better than any of the models OpenRouter ensembled except Fable itself.
The playbook is to take any frontier AI model, find the next-best (cheaper) frontier AI model, ensemble it with the leading open source model, and now you’ve got a cheaper version of the frontier. And that keeps on recursing. Larger ensemble, better router, better accuracy, even lower cost.
So called “Frontier AI Companies” will never again achieve the accuracy/cost/speed frontier. The frontier is now owned by the network of leading models and companies.
The problem for today’s centralized AI companies is the same one that mainframe computing companies had in the latter 20th century. Once the internet started linking together mainframe computers over telephone lines… the network of mainframe computers was always stronger than any individual mainframe.
This meant that… every time they added a stronger mainframe to rival the internet… the internet just assimilated that mainframe into its network and became even stronger. Your favorite VC, podcaster, or frontier marketing department might not agree… but it is now impossible for a single company to own the frontier of AI. The ship has sailed. The game is over.
Welcome to the network of neural networks.
Why is this competitive advantage is so robust? Frankly, it’s based on principles which are so fundamental to ML… it’s barely even research.
Heres the thing… people who have been in the AI research game long enough remember what it was like to compete for “state of the art” accuracy at NeurIPS circa 2010-2020. If you “got SOTA” you got published… and you probably got into a top-tier graduate school, etc. (i got SOTA as an undergrad, which got me a 1st author Oral Preso at ICML 2015, thus a lil Nashville undergrad got to go to Oxford funded by DeepMind and join DeepMind’s language modeling research team in 2017). Competing for SOTA was a huge deal. Everyone did it (many still do).
But there was a way to achieve SOTA which was so reliable that it was banned. If you weighted ensemble models together, you ~always get better accuracy…. even if you’re ensembling multiple trained versions of the same model (!!)
The reason is actually pretty simple… different AI models make different mistakes. When you combine their outputs… their mistakes tend to cancel each other out… yielding more accurate AI predictions. There’s some nuance to doing this well (gotta weight the ensemble) but it works.
The funny part… is that because it was banned from research conferences… it was also banned from research papers. And so I think… well… many people forgot. Lol. Anyway… that is why a network of neural networks is always going to beat any one neural network.
But you might be asking… what about cost?
Here’s the thing about a gigantic bundle of neurons… it’s unbelievably inefficient in its current form. That’s why attacking that inefficiency is reducing AI costs by a factor of 10-900x per year. Many factors are driving this, but I want to focus on the algorithmic one… specifically caching and indexing.
Imagine you went to a library, and you asked the librarian “what are the rules of chess?” And the librarian said, “one moment please”, and then proceeded to read EVERY page of EVERY book in the ENTIRE library…and then came back to you and gave you… 🥁… one token.
This is what GPT-3 did. It used nearly EVERY neuron to generate EVERY token… and remember… knowledge of the whole world is in the neurons!
The “DeepSeek” moment was a simple idea… “what if the library had SECTIONS!”. Then the librarian could walk over to the “chess section”… and deliver results faster.
And this points to the IDEAL state that AI is headed towards… it’s not Mixture of Experts… it’s MIXTURES OF MIXTURES OF EXPERTS. It’s indexing! Think about how a librarian does it! When you ask a librarian “what are the rules of chess?” They will:
Section: Walk to the games section
Shelf: Look for a shelf of chess books
Book: Scan the spines looking for “Introductory Chess Book” or similar
Chapter: Scan the table of contents looking for “overview of rules”
Paragraph: Find the paragraph giving a high level overview of chess rules, walk back to you, and hand that paragraph to you.
And that is like a billion times more efficient (and thus less costly!) than reading EVERY page of EVERY book on EVERY shelf EVERY time you generate a token.
AI is doing the same thing… and for the same reasons… the fastest and lowest cost option is going to be a massive index into the world neurons… not a single blobby network that considers every possible fact in the universe whenever it generates a token. And a global network of neural networks is the MOST EPIC SCALE CACHE+INDEX EVER. Each model on the network is a “cache” of internal mental models (stored in the neurons). And the way you find them is routers… big ‘ole index. That’s why it’s going to win. More on that in a moment.
The fundamental argument for cost is the same as the fundamental argument for speed… but I’ll address one doubt: isn’t a combination of AI models going to be slower than any single AI model?
It will be slower w.r.t. “Time to first token” (how long you wait for the response to start streaming to you) but not “overall tok/s”… which is the one that really matters. Basically.. if you call 50 models in parallel and combine them with another model… latency takes a hit (worst case speed of the 50 models + speed of the combining model), but bandwidth is the same. It’s streaming to you (again… see OpenRouter).
Taken together, market forces and the fundamentals of machine learning are taking over, and while irrationality, incumbency, and hype might keep rolling for a while… eventually the bill comes due. And we’re seeing it happen in real time.
AI is only as capable as the amount of data, compute, and talent used to create it. This is actually another way to describe the ensembling/hydra effect I just mentioned. Because when you ensemble AI models… you’re implicitly combining their data, compute, and algorithms. Scaling laws say… ensembles win. So geopolitically, this begs the question: which country is going to win the AI race?
2010-2026: Company-Level AI
Up until now (like… basically today), the world has lived in “Company Level AI”… meaning AI is as capable as the amount of data, compute, and talent that the largest company can bring together. This is why the biggest… baddest… most frontier..est… AI comes from the biggest companies (Google, Microsoft, OpenAI, Anthropic, etc.). They have the $ required to bring that data, compute, and talent together.
2026-2026: Nation-Level AI
This year, it’s started to look like AI was about to be owned by nations. China is obviously in a great position (from a political regime perspective) to nationalize data, compute, and talent across a nation of 1.4 billion people. The US is flirting with 50% ownership of its AI companies… and is now controlling when AI models are released and who is allowed to use them.
In theory… this was the new frontier. Nations can dominate any company on the scaling laws… train the biggest baddest (and safest?) AI models around. Right?
2026-Forever: World-Level AI
But now… frankly… we’re skipping it. The US Government just banned Fable… and within 24 hours the AI internet is offering BETTER THAN FABLE LEVEL QUALITY via OpenRouter. Still think we’re gonna spend any time in nation-level AI? Think again.
This has happened before.
TCP / IP / HTTP / WWW were all prototypes of protocols which became too popular too fast… linking together all the world’s mainframe computers (and eventually personal computers) into a network which was vastly more powerful than any particular computer. I kid you not… literally the pitch for ARPANET was: link together mainframes in a time-sharing network. That was the point. The network is more than the node.
But at that point… mainframe computing was the shizz. In theory “the world will only really need 5 or so mainframe computers” in the end (more of a meme than an exact quote… but you get the point).
But that’s NOT what happened… because of this same paradigm… America+Europe skipped straight from company-level computing to world-level computing too… and America+Europe set the tone for information technology for 50 years because America+Europe got there first (WWW from Europe, packet switching from UK, TCP/IP from US… combined into a global network which was biased towards openness, freedom, democracy, interoperability, and which has had massive cultural impacts ever sense).
We are skipping nation-level AI for world-level AI. And if you work for a national government and you’re reading this line… fighting it is not the way to win. Trying to stay in nation-level AI when world-level AI is on the table is… frankly… stupid. The opposite strategy (the strategy of WWW/TCP/HTTP/etc. is the way to win). Walling yourself off will silo you from the global network, and the middle powers will rise up ahead of the central powers.
Think this hasn’t happened before? Think again. :)
(insert anecdote about the printing press, the ottoman empire, etc…. but this post is too long already… i’ll save that for another day)
Social capital has flowed to whomever has the most capable or popular AI system… DeepMind was on top with AlphaGo. OpenAI pulled ahead with ChatGPT. Anthropic with Claude, etc.
That simply is no longer possible to sustain. And I’m sure frontier AI marketing departments will manage this pivot well (they have… truly… the best advertising/marketing minds in the world), but in the end… “truth will out”.
This is also going to turn upside down Anthropomorphism. It’s hard to claim it’s a singular mind when it’s clearly a hive mind… and individual actors in that collective intelligence get to turn on/off their contribution to the collective at any moment. We’re getting an economy for intelligence.
TLDR:
Instead of open/closed source AI… network-source AI
Instead of company-level AI… world-level AI
Instead of centralization… federated and decentralized AI
Instead of data colonialism… data sovereignty
Instead of surveillance… privacy
Instead of fair use… copyright (!)
Instead of siloed data… globally linked data (million times more data here!)
Instead of AI as nuclear weapons… it’s AI as an internet
Instead of AI as a singular mind… it’s an open marketplace for mental models
Instead of loss of control…. collective control
Instead of AI bias… representative queries
Instead of walled gardens… interoperability
Instead of disinformation… attribution-based chains of trust
Instead of unilateral control of AI…. attribution-based control of AI
Instead of deep learning… deep voting
Instead of broadcasting… broad listening
Short Term: incoherence between markets and dialog
If it takes a long time for the stock market to crash, the incumbents will hang on for a while. If there’s a market pullback, the need for lower-cost options will likely create a more dramatic shift towards people self-hosting open source models and linking to each other (or across businesses) peer-to-peer. Big heavy moment don’t pivot on a dime… even if the fundamentals are clearly pointing in a different direction.
Long Term: JCR Licklider’s original vision for the internet is finalized.
JCR Licklider is the visionary behind ARPANET… which became the internet. In 1968, he wrote what is (for me) the most important information technology paper of the 20th century. It’s titled “the computer as a communication device”.
The First Third: will change how you think about communication
The Second Third: describes his vision for the internet as we know it today
The Final Third: … is about AGENTS
(yes… AI agents… in 1968… i’m telling you this guy was a genius)
There’s too much to write about this here, but concentrating power has huge loss of control, value alignment, bias, wireheading, and other risks. While this new paradigm changes the safety problems that matter most, I believe it’s a profound win for the AI safety, freedom, and democracy loving people in the world. I’ll try to write more about this soon.
Here is the long version of what will happen. I’ll write shorter stuff on this substack.
If you want to talk with me about it… I’m @trask on OpenMined’s slack (slack.openmined.org). DM me anytime.