In the first article of this Claude Code project series, I built a small World Cup 2026 match predictor: Python calculated transparent Elo/Poisson probabilities, and Crazyrouter routed multiple LLMs to generate structured match previews.
The second project follows the same principle, but focuses on a different sports analytics workflow:
Can Claude Code build an odds movement monitor, then use
claude-fable-5to summarize market shifts as validated JSON?
This is still an engineering demo. It is not betting advice, and it does not recommend any wager. The purpose is to show how an AI coding agent can build a reproducible monitoring pipeline around numeric signals, alerts, LLM analysis, and validation.
The API layer was tested through Crazyrouter:
Odds movement sounds like a betting topic, but from an engineering perspective it is really a time-series monitoring problem.
You have:
That makes it a useful project for testing an AI coding agent.
The agent should not say “bet on this team.” Instead, it should build a monitoring system that answers safer engineering questions:
That is a much better use of Claude Code than asking a model to guess match outcomes.
The demo pipeline is intentionally small and reproducible:
The generated project lives here:
The key idea is simple:
For a reproducible demo, I used synthetic sample data instead of relying on a paid sportsbook feed.
The CSV contains four early World Cup match examples:
A production version would replace this with a real odds API, multiple bookmakers, timestamped snapshots, and data-quality checks.
Decimal odds can be converted into implied probability with a very small function:
Then we compare opening and latest implied probability:
If the absolute movement exceeds a threshold, the script creates an alert:
This makes the system transparent. The alert is not based on vibes or a black-box LLM. It is based on a deterministic calculation.
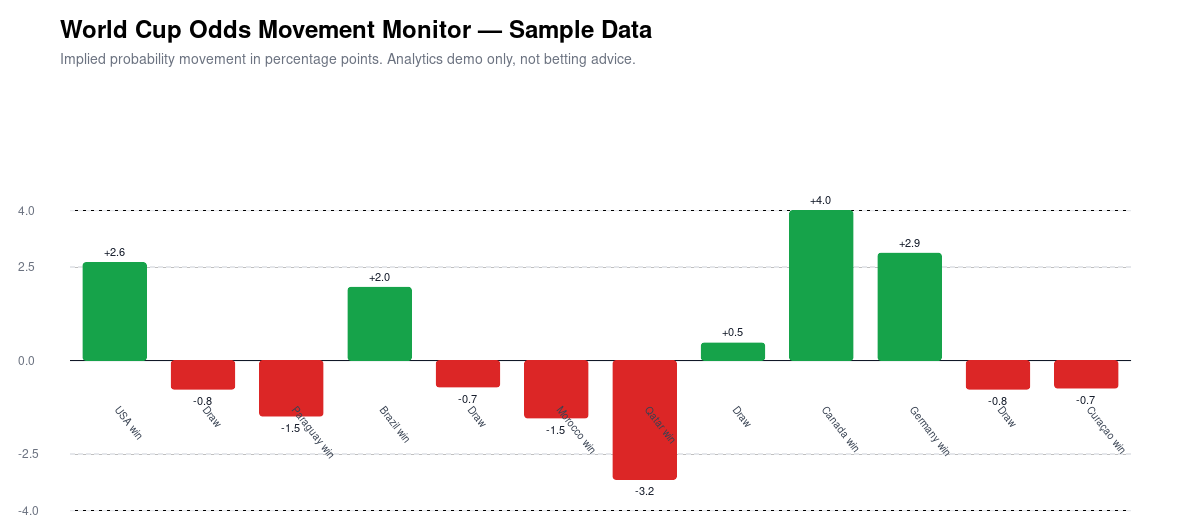
The script generated four significant movement alerts:
The biggest movement was Canada win in Qatar vs Canada, where implied probability increased by 4.01 percentage points.
Again: this is not a betting signal. It is a monitoring signal that says, “Something changed enough that a system should record it and maybe ask for more context.”
The next step was to ask claude-fable-5 to summarize the alerts as structured JSON.
The API configuration follows the OpenAI-compatible format:
The request used:
The instruction explicitly said:
The final successful test result:
| Model | HTTP | Latency | Prompt tokens | Completion tokens | Total tokens | Valid JSON |
|---|---|---|---|---|---|---|
claude-fable-5 | 200 | 12.14s | 833 | 599 | 1432 | True |
The model returned valid JSON without needing post-cleanup:
That output is useful because it does not turn the alert into a betting recommendation. It turns the alert into an engineering checklist.
There was one important failure during testing.
My first request to claude-fable-5 returned:
The cause was not the model name. The model was available in /v1/models.
The issue was request compatibility. A slightly different payload shape worked later.
I also tested a longer JSON-output prompt with a lower token cap. That returned HTTP 200, but the content was wrapped in a Markdown code fence and sometimes reached the output limit.
The final working pattern was:
model: claude-fable-5;max_tokens rather than extra unsupported parameters;This is exactly why “model quality” is not only about intelligence.
For production systems, quality includes:
An odds monitor is a good example of why an API gateway helps.
The workflow has several model-dependent tasks:
Different models may behave differently on these requirements.
With Crazyrouter, the integration stays simple:
That makes it easier to compare claude-fable-5 with other models later, without rewriting the application.
A useful Claude Code workflow should not just produce a script. It should build the operational pieces around the script:
sample_odds_movements.csv for reproducible input;odds_monitor_output.json for deterministic alert output;odds_movement_chart.svg for visualization;crazyrouter_raw_claude-fable-5.json for raw API audit;claude_fable_5_final_test_result.json for validation evidence;That is the pattern I care about in this series.
Claude Code should not be treated as a magic answer machine. It should be treated as a project executor that produces files, tests, logs, and artifacts.
This demo intentionally uses synthetic sample data.
A production odds monitor would need:
The article is about building the monitoring workflow, not about making betting predictions.
A stronger version could add:
claude-fable-5, GPT, Gemini, and Qwen routes;The most important metric would not be token cost alone.
It would be:
That includes failed requests, retries, malformed JSON, and time spent debugging payload issues.
Yes, Claude Code can build an odds movement monitor, but the right framing matters.
The best architecture is:
This project is a good second entry in the Claude Code project series because it moves from match prediction into monitoring: a more realistic pattern for analytics dashboards, financial dashboards, API observability, and operational alerts.
If you want to test claude-fable-5 or other models through one OpenAI-compatible API layer, try Crazyrouter:
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。