一、string和stringbuffer和stringbuilder的区别
1、string:
String的值是不可变的,这就导致每次对String的操作都会生成新的String对象,不仅效率低下,而且浪费大量优先的内存空间
String str = "abc";
str += "def";
2、stringbuffer和stringbuilder:
当对字符串进行修改的时候,特别是字符串对象经常改变的情况下,需要使用 StringBuffer 和 StringBuilder 类。
和 String 类不同的是,StringBuffer 和 StringBuilder 类的对象能够被多次的修改,并且不产生新的未使用对象。
StringBuilder 类在 Java 5 中被提出,它和 StringBuffer 之间的最大不同在于 StringBuilder 的方法不是线程安全的(不能同步访问)。
由于 StringBuilder 相较于 StringBuffer 有速度优势,所以多数情况下建议使用 StringBuilder 类。然而在应用程序要求线程安全的情况下,则必须使用 StringBuffer 类。
StringBuilder str = new StringBuilder("abc");
str.append("def");
3、小结:
(1)如果要操作少量的数据用 String;
(2)多线程操作字符串缓冲区下操作大量数据 StringBuffer;
(3)单线程操作字符串缓冲区下操作大量数据 StringBuilder。
二、集合相关问题
1.Collection和Map的区别
在Java集合框架中,Collection 和 Map 是两个并列的顶级接口,它们在设计目的、数据结构和使用方式上存在根本区别。
核心区别概览
Collection:用于存储单个对象的集合,是一个“单列”结构。它的主要子接口包括 List(有序、可重复)和 Set(无序、不可重复)。
Map:用于存储键值对(Key-Value)的映射关系,是一个“双列”结构。每个键(Key)唯一,映射到一个值(Value),键不可重复,但值可以重复。
2.list, set, map区别
List特点:元素有放入顺序,元素可重复
Set特点:元素无放入顺序,元素不可重复(注意:元素虽然无放入顺序,但是元素在set中的位置是有该元素的HashCode决定的,其位置其实是固定的)
Map特点:元素按键值对存储,无放入顺序
| List | Set | Map | |
| 继承接口 | Collection | Collection | |
| 常见实现类 | ArrayList、LinkedList、Vector | HashSet、LinkedHashSet、TreeSet | HashMap、HashTable |
| 元素 | 可重复 | 不可重复(用equals()判断) |
不可重复 |
| 顺序 | 有序 | 无序(实际上由HashCode决定) | |
| 线程安全 | Vector线程安全 | Hashtable线程安全 |
3.ArrayList与LinkedList区别:
| ArrayList | LinkedList | |
| 结构 | 动态数组 | 双链表 |
| 性能 | 查找性能好,因为底层是数组,适用于查找元素 | 底层是双链表,对于插入或者删除元素来说,操作方便,性能高 |
| 线性安全 | 不安全 | 不安全 |
三,get,post,put,delete
1、GET请求会向数据库发索取数据的请求,从而来获取信息,该请求就像数据库的select操作一样,只是用来查询一下数据,不会修改、增加数据,不会影响资源的内容,即该请求不会产生副作用。无论进行多少次操作,结果都是一样的。
2、与GET不同的是,PUT请求是向服务器端发送数据的,从而改变信息,该请求就像数据库的update操作一样,用来修改数据的内容,但是不会增加数据的种类等,也就是说无论进行多少次PUT操作,其结果并没有不同。
3、POST请求同PUT请求类似,都是向服务器端发送数据的,但是该请求会改变数据的种类等资源,就像数据库的insert操作一样,会创建新的内容。几乎目前所有的提交操作都是用POST请求的。
4、DELETE请求顾名思义,就是用来删除某一个资源的,该请求就像数据库的delete操作。
四,get,post区别
GET 请求可被缓存
GET 请求保留在浏览器历史记录中
GET 请求可被收藏为书签
GET 请求有长度限制
GET 请求只应当用于取回数据
GET比POST更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息
GET参数通过URL传递,POST放在Request body中。
五、mysql的索引
1、方式:
根据存储方式的不同,MySQL 中常用的索引在物理上分为 B-树索引和 HASH 索引两类,两种不同类型的索引各有其不同的适用范围。
B-树索引又称为 BTREE 索引,目前大部分的索引都是采用 B-树索引来存储的。
B-树索引是一个典型的数据结构,其包含的组件主要有以下几个:
基于这种树形数据结构,表中的每一行都会在索引上有一个对应值。因此,在表中进行数据查询时,可以根据索引值一步一步定位到数据所在的行。
B-树索引可以进行全键值、键值范围和键值前缀查询,也可以对查询结果进行 ORDER BY 排序。但 B-树索引必须遵循左边前缀原则,要考虑以下几点约束:
哈希(Hash)一般翻译为“散列”,也有直接音译成“哈希”的,就是把任意长度的输入(又叫作预映射,pre-image)通过散列算法变换成固定长度的输出,该输出就是散列值。
哈希索引也称为散列索引或 HASH 索引。MySQL 目前仅有 MEMORY 存储引擎和 HEAP 存储引擎支持这类索引。其中,MEMORY 存储引擎可以支持 B-树索引和 HASH 索引,且将 HASH 当成默认索引。
HASH 索引不是基于树形的数据结构查找数据,而是根据索引列对应的哈希值的方法获取表的记录行。哈希索引的最大特点是访问速度快,但也存在下面的一些缺点:
MySQL 需要读取表中索引列的值来参与散列计算,散列计算是一个比较耗时的操作。也就是说,相对于 B-树索引来说,建立哈希索引会耗费更多的时间。
不能使用 HASH 索引排序。
HASH 索引只支持等值比较,如“=”“IN()”或“<=>”。
HASH 索引不支持键的部分匹配,因为在计算 HASH 值的时候是通过整个索引值来计算的。
2、类型
普通索引是 MySQL 中最基本的索引类型,它没有任何限制,唯一任务就是加快系统对数据的访问速度。
普通索引允许在定义索引的列中插入重复值和空值。
创建普通索引时,通常使用的关键字是 INDEX 或 KEY。
唯一索引与普通索引类似,不同的是创建唯一性索引的目的不是为了提高访问速度,而是为了避免数据出现重复。
唯一索引列的值必须唯一,允许有空值。如果是组合索引,则列值的组合必须唯一。
创建唯一索引通常使用 UNIQUE 关键字。
顾名思义,主键索引就是专门为主键字段创建的索引,也属于索引的一种。
主键索引是一种特殊的唯一索引,不允许值重复或者值为空。
创建主键索引通常使用 PRIMARY KEY 关键字。不能使用 CREATE INDEX 语句创建主键索引。
空间索引是对空间数据类型的字段建立的索引,使用 SPATIAL 关键字进行扩展。
创建空间索引的列必须将其声明为 NOT NULL,空间索引只能在存储引擎为 MyISAM 的表中创建。
空间索引主要用于地理空间数据类型 GEOMETRY。对于初学者来说,这类索引很少会用到。
全文索引主要用来查找文本中的关键字,只能在 CHAR、VARCHAR 或 TEXT 类型的列上创建。在 MySQL 中只有 MyISAM 存储引擎支持全文索引。
全文索引允许在索引列中插入重复值和空值。
不过对于大容量的数据表,生成全文索引非常消耗时间和硬盘空间。
创建全文索引使用 FULLTEXT 关键字。
3、复合索引
索引在逻辑上分为以上 5 类,但在实际使用中,索引通常被创建成单列索引和多列索引(又称复合索引,组合索引)。
单列索引就是索引只包含原表的一个列。在表中的单个字段上创建索引,单列索引只根据该字段进行索引。
单列索引可以是普通索引,也可以是唯一性索引,还可以是全文索引。只要保证该索引只对应一个字段即可。
组合索引也称为复合索引或多列索引。相对于单列索引来说,组合索引是将原表的多个列共同组成一个索引。多列索引是在表的多个字段上创建一个索引。该索引指向创建时对应的多个字段,可以通过这几个字段进行查询。但是,只有查询条件中使用了这些字段中第一个字段时,索引才会被使用。
例如,在表中的 id、name 和 sex 字段上建立一个多列索引,那么,只有查询条件使用了 id 字段时,该索引才会被使用。
总结:
多个单列索引在多条件查询时优化器会选择最优索引策略,可能只用一个索引,也可能将多个索引全用上! 但多个单列索引底层会建立多个B+索引树,比较占用空间,也会浪费一定搜索效率,故如果只有多条件联合查询时最好建联合索引!
当创建**(a,b,c)联合索引时,相当于创建了(a)单列索引**,(a,b)联合索引以及**(a,b,c)联合索引**
其他知识点:
1、需要加索引的字段,要在where条件中
2、数据量少的字段不需要加索引;因为建索引有一定开销,如果数据量小则没必要建索引(速度反而慢)
3、避免在where子句中使用or来连接条件,因为如果俩个字段中有一个没有索引的话,引擎会放弃索引而产生全表扫描
4、联合索引比对每个列分别建索引更有优势,因为索引建立得越多就越占磁盘空间,在更新数据的时候速度会更慢。另外建立多列索引时,顺序也是需要注意的,应该将严格的索引放在前面,这样筛选的力度会更大,效率更高。
六、equals与==
== 比较的是变量(栈)内存中存放的对象的(堆)内存地址,用来判断两个对象的地址是否相同,即是否是指相同一个对象。比较的是真正意义上的指针操作。
equals用来比较的是两个对象的内容是否相等,由于所有的类都是继承自java.lang.Object类的,所以适用于所有对象,如果没有对该方法进行覆盖的话,调用的仍然是Object类中的方法,而Object中的equals方法返回的却是==的判断。
java中的数据类型可以分为两类:
byte,short,char,int,long,float,double,boolean
基本数据类型之间的比较需要用双等号(==),因为他们比较的是值
接口、类、数组等非基本数据类型
Java中的字符串String属于引用数据类型。因为String是一个类
当他们用(==)进行比较的时候,比较的是他们在内存中的存放地址,所以,除非是同一个new出来的对象,他们的比较后的结果为true,否则比较后结果为false。因为没new一次就会重新开辟一个新的堆内存空间
Java中所有的类都是继承与Object这个基类的,在Object类中定义了一个equals方法,这个方法的初始行为是比较对象的内存地址,但在一些类库中已经重写了这个方法(一般都是用来比较对象的成员变量值是否相同),比如:String,Integer,Date 等类中,所以他们不再是比较类在堆中的地址了
String a = new String("ab"); // a 为一个引用 String b = new String("ab"); // b为另一个引用,对象的内容一样 String aa = "ab"; // 放在常量池中 String bb = "ab"; // 从常量池中查找 System.out.println(aa==bb); // true System.out.println(a==b); // false,非同一对象 System.out.println(a.equals(b)); // true
对于复合数据类型之间进行equals比较,在没有覆写equals方法的情况下,他们之间的比较还是内存中的存放位置的地址值,跟双等号(==)的结果相同;如果被复写,按照复写的要求来。
== 的作用:
基本类型:比较的就是值是否相同
引用类型:比较的就是地址值是否相同
equals 的作用:
引用类型:默认情况下,比较的是地址值,重写该方法后比较对象的成员变量值是否相同
七、@Controller和@RestController
1) 如果只是使用@RestController注解Controller,则Controller中的方法无法返回jsp页面,或者html,配置的视图解析器 InternalResourceViewResolver不起作用,返回的内容就是Return 里的内容。
2) 如果需要返回到指定页面,则需要用 @Controller配合视图解析器InternalResourceViewResolver才行。
3)使用@Controller 注解,在对应的方法上,视图解析器可以解析return 的jsp,html页面,并且跳转到相应页面。若返回json等内容到页面,则需要加@ResponseBody注解。
4)@RestController注解,相当于@Controller+@ResponseBody两个注解的结合,返回json数据不需要在方法前面加@ResponseBody注解了,但使用@RestController这个注解,就不能返回jsp,html页面,视图解析器无法解析jsp,html页面
总结:
前后端分离的情况下,返回json等数据用@RestController。
返回到jsp,html页面用@Controller。
八、封装,继承,多态
转载
JAVA基础——面向对象三大特性:封装、继承、多态 - 云开的立夏 - 博客园 (cnblogs.com)
九、sleep()与wait()的区别
1、sleep方法是Thread类的静态方法;wait方法是Object类的成员方法。
2、sleep方法使当前线程暂停执行指定的时间,让出cpu给其他线程,但是它的监控状态依然保持着,当指定的时间到了又会自动恢复运行状态。在调用sleep方法后,线程不会释放对象锁;
而当调用wait方法时,线程会放弃对象锁,进入等待此对象的等待锁定池,只有针对此对象调用notify()方法后本线程才进入对象锁定池处于准备状态。
3、sleep方法可以在任何地方使用;wait方法只能在同步方法和同步代码块中使用(配合synchronized使用)。
十、Mybatis中#{}与${}的区别
1、变量替换后,#{} 对应的变量自动加上引号 '',${} 对应的变量不会。
#{}:select * from t_user where uid=#{uid}
${}:select * from t_user where uid= '${uid}'
2、#{} 能防止sql 注入,${} 不能防止sql 注入。
所谓SQL注入,就是通过把SQL命令插入到Web表单提交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令。
入参id的值传入“1 or userId=2”,入参pwd的值传入“111111”。以#{}格式传入入参后的执行sql:
select * from user where userId=”1 or userId=2” and password = “111111”;
以${}格式传入入参后的执行sql:
select * from user where userId=1 or userId=2 and password = 111111;
很显然,以${}格式传入入参后的执行sql打乱了我们的预期sql格式及查询条件,从而实现sql注入。
3、$方式一般用于传入数据库对象,例如传入表名。
4、排序时使用order by 动态参数时需要注意,用$而不是#。
5、一般能用#的就别用$。
十一、Mybatis的一二级缓存
1、一级缓存
Mybatis的一级缓存是指Session缓存。一级缓存的作用域默认是一个SqlSession。Mybatis默认开启一级缓存。
也就是在同一个SqlSession中,执行相同的查询SQL,第一次会去数据库进行查询,并写到缓存中;
第二次以后是直接去缓存中取。
当执行SQL查询中间发生了增删改的操作,MyBatis会把SqlSession的缓存清空。
一级缓存的范围有SESSION和STATEMENT两种,默认是SESSION,开启状态,如果不想使用一级缓存,可以把一级缓存的范围指定为STATEMENT,这样每次执行完一个Mapper中的语句后都会将一级缓存清除。
如果需要更改一级缓存的范围,可以在Mybatis的配置文件中,在下通过localCacheScope指定。
<setting name="localCacheScope" value="STATEMENT"/>
需要注意的是
当Mybatis整合Spring后,直接通过Spring注入Mapper的形式,如果不是在同一个事务中每个Mapper的每次查询操作都对应一个全新的SqlSession实例,这个时候就不会有一级缓存的命中,但是在同一个事务中时共用的是同一个SqlSession。
如果多个数据库请求在同一个事务中,那么多个请求都在共用一个SqlSession,反之每个请求都会创建一个SqlSession。
测试在方法中不加事务时,每个请求是否会创建一个SqlSession:
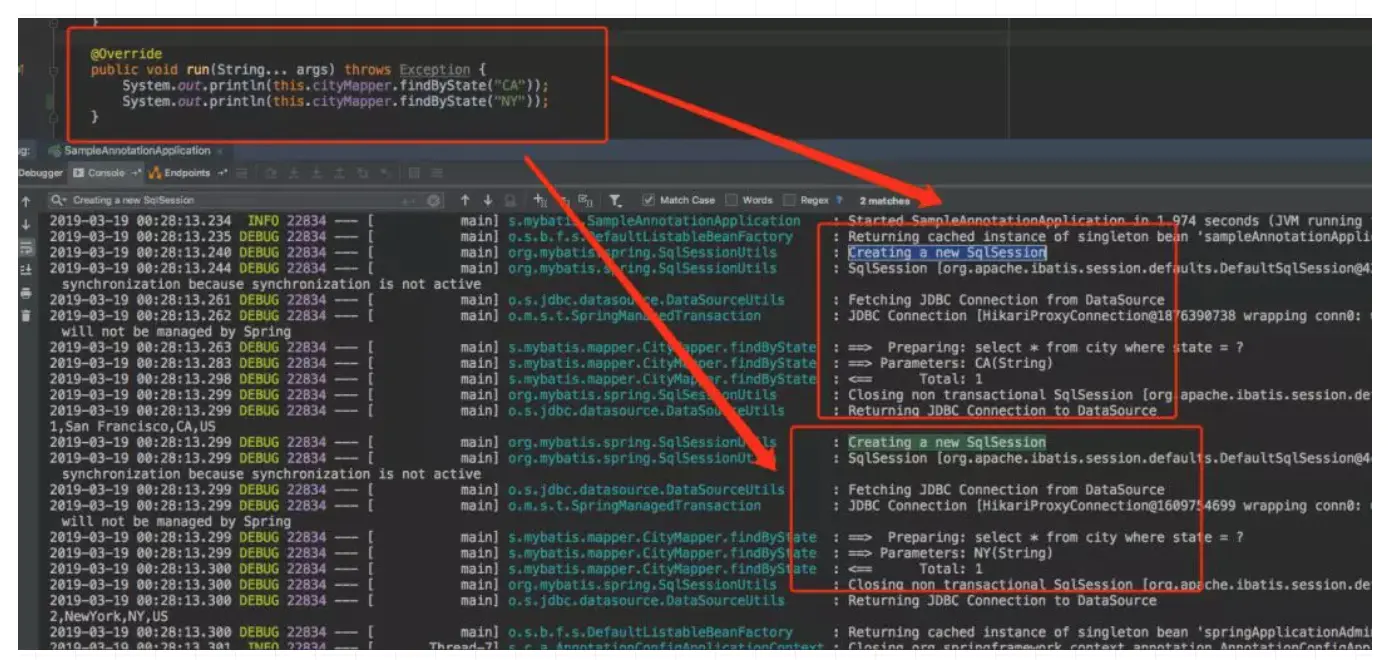
从日志可以看出,在没有加事务的情况下,确实是Mapper的每次请求数据库,都会创建一个SqlSession与数据库交互,下面我们再看看加了事务的情况:
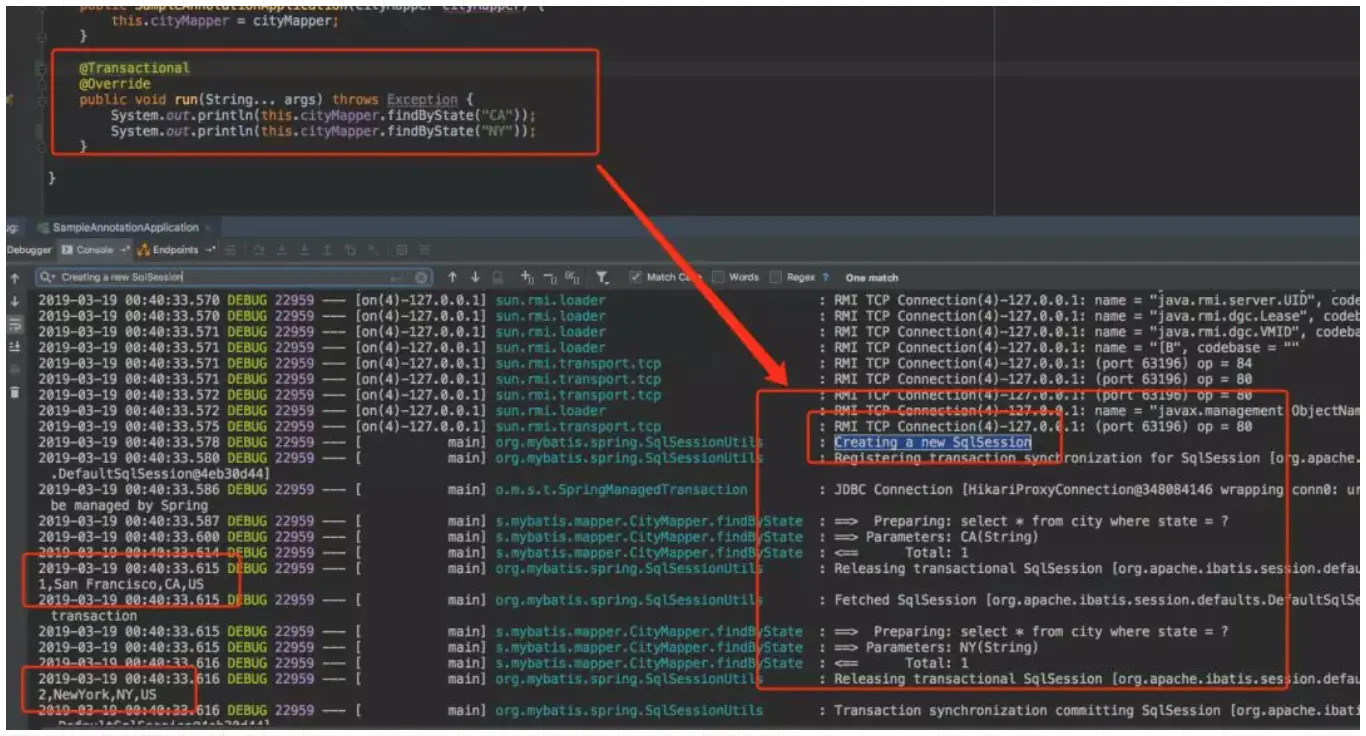
从日志可以看出,在方法中加了事务后,两次请求只创建了一个SqlSession。
2、二级缓存
Mybatis的二级缓存是指mapper映射文件。二级缓存的作用域是同一个namespace下的mapper映射文件内容,多个SqlSession共享。Mybatis需要手动设置启动二级缓存。
二级缓存是默认关闭的。如想开启,指定cacheEnabled为true。
<settings> <setting name="cacheEnabled" value="true" /> </settings>
要使用二级缓存除了上面一个配置外,我们还需要在我们每个DAO对应的Mapper.xml文件中定义需要使用的cache
<mapper namespace="...UserMapper">
<cache/><!-- 加上该句即可 -->
...
</mapper>
3、尽量减少二级缓存的使用
可能会有很多人不理解这里,二级缓存带来的好处远远比不上他所隐藏的危害。
缓存是以namespace为单位的,不同namespace下的操作互不影响。
insert,update,delete操作会清空所在namespace下的全部缓存。
通常使用MyBatis Generator生成的代码中,都是各个表独立的,每个表都有自己的namespace。
为什么避免使用二级缓存
在符合【Cache使用时的注意事项】的要求时,并没有什么危害。
其他情况就会有很多危害了。
针对一个表的某些操作不在他独立的namespace下进行。
例如在UserMapper.xml中有大多数针对user表的操作。但是在一个XXXMapper.xml中,还有针对user单表的操作。
这会导致user在两个命名空间下的数据不一致。如果在UserMapper.xml中做了刷新缓存的操作,在XXXMapper.xml中缓存仍然有效,如果有针对user的单表查询,使用缓存的结果可能会不正确。
更危险的情况是在XXXMapper.xml做了insert,update,delete操作时,会导致UserMapper.xml中的各种操作充满未知和风险。
有关这样单表的操作可能不常见。但是你也许想到了一种常见的情况。
多表操作一定不能使用缓存
为什么不能?
首先不管多表操作写到那个namespace下,都会存在某个表不在这个namespace下的情况。
例如两个表:role和user_role,如果我想查询出某个用户的全部角色role,就一定会涉及到多表的操作。
<select id="selectUserRoles" resultType="UserRoleVO"> select * from user_role a,role b where a.roleid = b.roleid and a.userid = #{userid} </select>
像上面这个查询,你会写到那个xml中呢?
不管是写到RoleMapper.xml还是UserRoleMapper.xml,或者是一个独立的XxxMapper.xml中。如果使用了二级缓存,都会导致上面这个查询结果可能不正确。
如果你正好修改了这个用户的角色,上面这个查询使用缓存的时候结果就是错的。
十二、对SpringMVC的理解
定义:SpringMVC是属于Spring生态的一个模块,是一个轻量级web框架。
目的:简化传统的Servlet+JSP模式下的web开发方式。
优点:
1、把传统的MVC框架里面的Controller控制器做了拆分,分成前端控制器DispatcherServlet和后端控制器Controller。
2、把Model模型拆分诚业务层Service和数据访问层Repository。
3、在视图层可以支持不同的视图,比如FreeMark、velocity、JSP等。
流程:
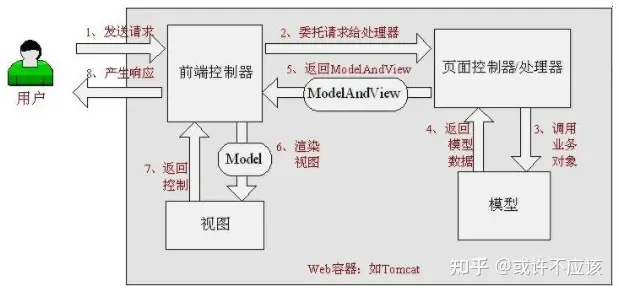
十三、对Spring IOC的理解
1、定义:
IOC全称Inversion Of Control,控制反转。
它的核心思想是把对象的管理权限交给容器,应用程序如果需要使用某个对象的实例,直接从IOC容器中获取就可以了。
2、bean的声明方式:
xml文件中的<bean>标签
@Service,@Repository等注解
@Configuration配置类里面的@Bean注解
Spring在启动时会解析这些注解,并保存在容器中。
3、IOC工作流程:
第一阶段,初始化阶段。根据xml或注解生成BeanDefinition,注册到容器中。
第二阶段,使用阶段。通过@Autowired注解或者BeanFactory.getBean()方法从IOC容器中获取实例。
十四、hashmap和hashtable的区别
允许null值。HashMap允许键(Key)和值(Value)为null,而Hashtable不允许键和值为null。
初始量和扩容机制。HashMap的初始容量为16,扩容时容量翻倍;而Hashtable的初始容量为11,扩容时也是容量翻倍但加1。
线程安全性。Hashtable是线程安全的,因为它被synchronized;而HashMap不是线程安全的,因此在多线程环境下使用时需要额外的同步措施。
十四、@Autowired和@Resource有什么区别
1、@Autowired 是 Spring 定义的注解,而 @Resource 是 Java 定义的注解,它来自于 JSR-250(Java 250 规范提案)。
2、@Autowired 是先根据类型(byType)查找,如果存在多个 Bean 再根据名称(byName)进行查找。
@Resource 是先根据名称查找,如果(根据名称)查找不到,再根据类型进行查找。
3、@Autowired 只支持设置一个 required 的参数,而 @Resource 支持 7 个参数。
@Resource(name = "userinfo", type = UserInfo.class) private UserInfo user;
4、@Autowired 和 @Resource 支持依赖注入的用法不同,常见依赖注入有以下 3 种实现:
这 3 种实现注入的实现代码如下。
a) 属性注入
@RestController
public class UserController {
// 属性注入
@Autowired
private UserService userService;
@RequestMapping("/add")
public UserInfo add(String username, String password) {
return userService.add(username, password);
}
}
b) 构造方法注入
@RestController
public class UserController {
// 构造方法注入
private UserService userService;
@Autowired
public UserController(UserService userService) {
this.userService = userService;
}
@RequestMapping("/add")
public UserInfo add(String username, String password) {
return userService.add(username, password);
}
}
c) Setter 注入
@RestController
public class UserController {
// Setter 注入
private UserService userService;
@Autowired
public void setUserService(UserService userService) {
this.userService = userService;
}
@RequestMapping("/add")
public UserInfo add(String username, String password) {
return userService.add(username, password);
}
}
其中, @Autowired 支持属性注入、构造方法注入和 Setter 注入,而 @Resource 只支持属性注入和 Setter 注入。
5、当一个接口存在多个实现类时,Autowired和Resource都需要通过名称才能匹配到对应的Bean。
Java中如何实现一个接口拥有多个实现类 - Neonuu - 博客园 (cnblogs.com)
十五、抽象类和接口相关问题
1. 什么是抽象类?
抽象类是一种特殊的类,它不能被实例化。它主要用于以下目的:
提供公共的基类:当一个类中有一些方法需要在子类中实现时,可以将这些方法声明为抽象方法,并让子类去实现它们。
共享代码:抽象类可以包含非抽象方法,这意味着可以在多个子类之间共享代码。
2. 什么是接口?
接口是一种完全抽象的类,它只包含常量和方法的签名,而没有实现。接口主要用于以下目的:
定义行为的规范:通过接口,可以定义一个类的行为规范,任何实现该接口的类都必须实现接口中的所有方法。
多继承:Java不支持类的多重继承,但通过实现多个接口,一个类可以实现多重继承的行为。
3. 抽象类和接口的区别
实现方式:抽象类使用extends关键字,而接口使用implements关键字来实现。
字段:抽象类可以有字段,而接口中的字段默认是public static final(即常量)。
方法:抽象类可以有非抽象方法(即实现的方法),而接口中的所有方法默认是public abstract(即抽象方法)。
构造器:抽象类可以有构造器,用于初始化状态或传递参数给子类。而接口不能有构造器。
访问修饰符:在Java 8及以后版本,接口中的方法可以有默认方法和静态方法(default和static),而抽象类的方法只能是抽象的或者具体的。
4.接口可以继承接口吗?
可以。在Java中,接口之间的继承使用extends关键字实现。一个接口不仅可以继承一个父接口,还可以同时继承多个父接口,这被称为多继承。(类不能多继承,一个子类只允许有一个父类)这种机制允许子接口继承父接口中定义的所有抽象方法和常量,从而实现代码的复用和功能的扩展。
接口继承的特点:
语法:使用extends关键字,多个父接口用逗号分隔。
多继承支持:与类的单继承不同,接口支持多继承,这是Java弥补单继承限制的重要方式。
方法继承:子接口会继承所有父接口中的抽象方法,实现类只需实现这些方法一次。
常量继承:父接口中定义的public static final常量也会被子接口继承。
无实现继承:接口继承只继承方法声明和常量,不继承方法实现(除非是默认方法或静态方法)。
// 父接口1 interface Flyable { void fly(); } // 父接口2 interface Swimmable { void swim(); } // 子接口继承多个父接口 interface Amphibious extends Flyable, Swimmable { void land(); // 新增方法 } // 实现类需要实现所有继承的方法 class Frog implements Amphibious { public void fly() { System.out.println("Frog can fly"); } public void swim() { System.out.println("Frog can swim"); } public void land() { System.out.println("Frog can land"); } }
5.抽象类可以继承抽象类吗?
可以。
6.抽象类可以继承普通类吗?
可以。
7.String类能否被继承?
不能,String类是final类,不可以被继承。
十六、常用工具类
1.StirngUtils(org.apache.commons.lang3.StringUtils)
//判断是否为空 StringUtils.isEmpty(null);//true StringUtils.isEmpty("");//true StringUtils.isEmpty(" ");//false StringUtils.isBlank(null);//true StringUtils.isBlank("");//true StringUtils.isBlank(" ");//true //字符串比较 StringUtils.equals("java","java");//true StringUtils.equalsIgnoreCase("java","JAVA");//true StringUtils.contains("java","av");//true StringUtils.indexOf("aabaabaa", 'b')//返回2 StringUtils.indexOf("aabaabaa", 'c')//返回-1 //字符串截取 StringUtils.substring("java",1)//返回"ava" StringUtils.substring("helloworld",1,4)//返回"ello" StringUtils.split("a,b,c,d",",")//返回["a","b","c","d"] StringUtils.split("a,b,,,c,,d",",")//自动过滤空字符串,返回["a","b","c","d"] //字符串修改 StringUtils.reverse("java");//反转,返回"avaj" StringUtils.replace("java","av","kk");替换,返回"jkka"
2.Collections
// 示例用法 List<Integer> list = new ArrayList<>(); list.add(2); list.add(6); list.add(3); list.add(5); // 升序排序 Collections.sort(list); System.out.println(list); // 反转列表 Collections.reverse(list); System.out.println(list); // 查找最大值和最小值 System.out.println(Collections.max(list)); System.out.println(Collections.min(list));
3.CollectionUtils
// 示例用法 // 判空 CollectionUtils.isEmpty(list); List<Integer> list2 = new ArrayList<>(); list2.add(3); list2.add(4); list2.add(5); list2.add(8); // 获取并集 Collection<Integer> unionList = CollectionUtils.union(list, list2); // 获取交集 Collection<Integer> intersectionList = CollectionUtils.intersection(list, list2); // 获取差集 Collection<Integer> subtractList = CollectionUtils.subtract(list, list2);
4.BeanUtils
简化java bean 对象之间的属性拷贝
// 示例用法
// 属性拷贝(两个对象可以是不同的类,只要属性名相同就会拷贝)
People people1 = new People(); people1.setAge(11); people1.setName("张三"); People people2 = new People(); BeanUtils.copyProperties(people1, people2); System.out.println(people2);Employee employee = new Employee();
BeanUtils.copyProperties(people1, employee);
System.out.println(employee);
//使用 Map 中的键值对填充 JavaBean 的属性。 Map<String, Object> map = new HashMap<>(); map.put("name", "Jane Smith"); map.put("age", 28); Person person = new Person(); BeanUtils.populate(person, map); System.out.println(person.getName()); // 输出 "Jane Smith" System.out.println(person.getAge()); // 输出 28
//返回一个包含 JavaBean 属性名称及其值的 Map Person person = new Person(); person.setName("John Doe"); person.setAge(30); Map<String, Object> properties = BeanUtils.describe(person); for (String key : properties.keySet()) { System.out.println(key + ": " + properties.get(key)); }
5.DegestUtlis
提供数据加密方法,如MD5、SHA256加密
// 示例用法 String md5Hex = DigestUtils.md5Hex("Dylan"); String sha256Hex = DigestUtils.sha256Hex("Dylan");
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。