如果必须用一句话概括大模型时代最重要的工程发现,那就是:
在模型参数固定的情况下,AI 的能力上限,主要由它在推理时能够同时访问的“有效信息量”所决定。
这不是比喻。
而是一条在工程实践中反复被验证的系统规律。
理解这一点,几乎可以解释过去几年 AI 领域所有看似神奇的能力跃迁。

人们对 AI 的直觉,往往来自对人类大脑的类比。
我们很容易想象:
但真实系统结构并非如此。
大语言模型的本质,是一次性的前馈计算:
Output = f(Input Tokens)在计算过程中:
但它们具有两个关键特征:
✔ 只存在于当前推理过程中
✔ 不会跨上下文持续保留
模型没有持续运作的“内部思考空间”。
每一次推理,本质上都是对当前可见信息的一次性整合计算。

Context 并不是存储结构。
它本质上是一种:
物理约束。
它代表的是:
模型在一次推理中可以同时访问的信息窗口。
在注意力机制中:
每个 token 都可以对所有可见 token 进行加权聚合。
因此:
Context 就是模型唯一的认知空间。
Context 并不会直接增加模型能力。
它只做一件事:
定义能力的上限边界。
模型无法理解它“看不到”的信息。
心理学研究表明:
人类工作记忆容量约为 7±2 信息单元。
对于大模型来说:
Context Window 本质上就是它的“工作记忆容量”。

传统认知认为:
模型越大 → AI 越强
这一观点并不错误,但并不完整。
参数规模 → 表达能力
决定:
Context → 认知空间
决定:
当表达能力足够强 + 可见信息足够多时,复杂推理能力才会真正涌现。
AI 能力 ≈ 表达能力 × 可见信息量

当 Context 从几百 token 扩展到几十万 token 时:
变化的并不是容量,而是系统性质。
模型开始表现出:
单次推理中可利用的信息密度大幅提升。
从信息论角度:
AI 能力上限取决于可利用的信息熵,而不仅是参数规模。
当输入信息增加时,会发生三种关键变化。
更多条件 → 概率分布收敛
结果:
每增加一个 token:
→ 潜在关联关系呈指数增长。
模型构建的是:
更密集的信息连接网络
这使它能:
信息越丰富:
本质上:
更多信息 = 更稳定的语义坐标系

从工程角度看,可以得到一个极其清晰的结论:
大模型不仅是计算系统,更是信息可见性系统。
它的核心限制往往不是算力,而是:
推理时可同时访问的信息量。
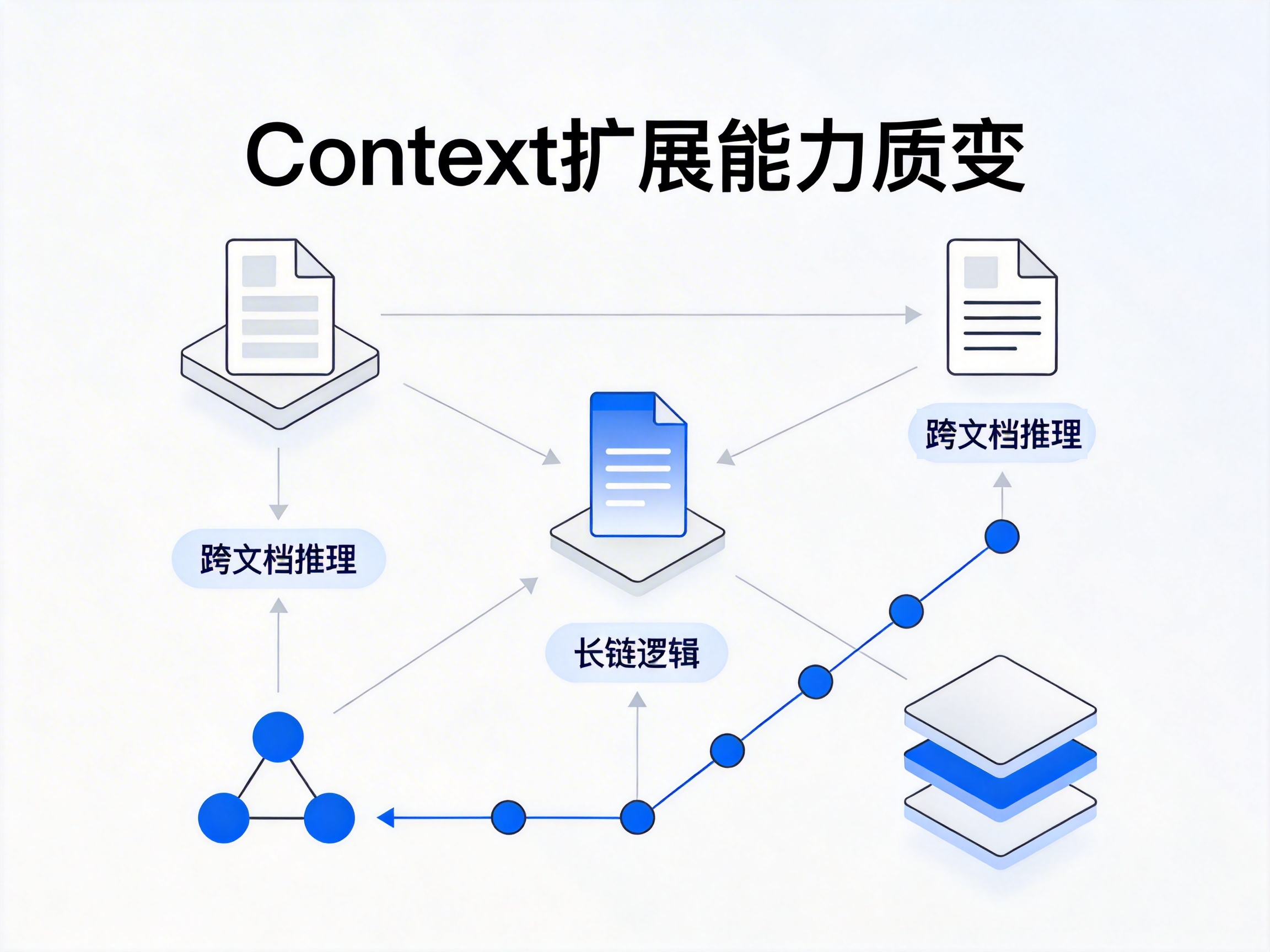
过去几年关键技术看似不同:
但它们的目标完全一致:
让模型在推理时看到更多正确的信息。
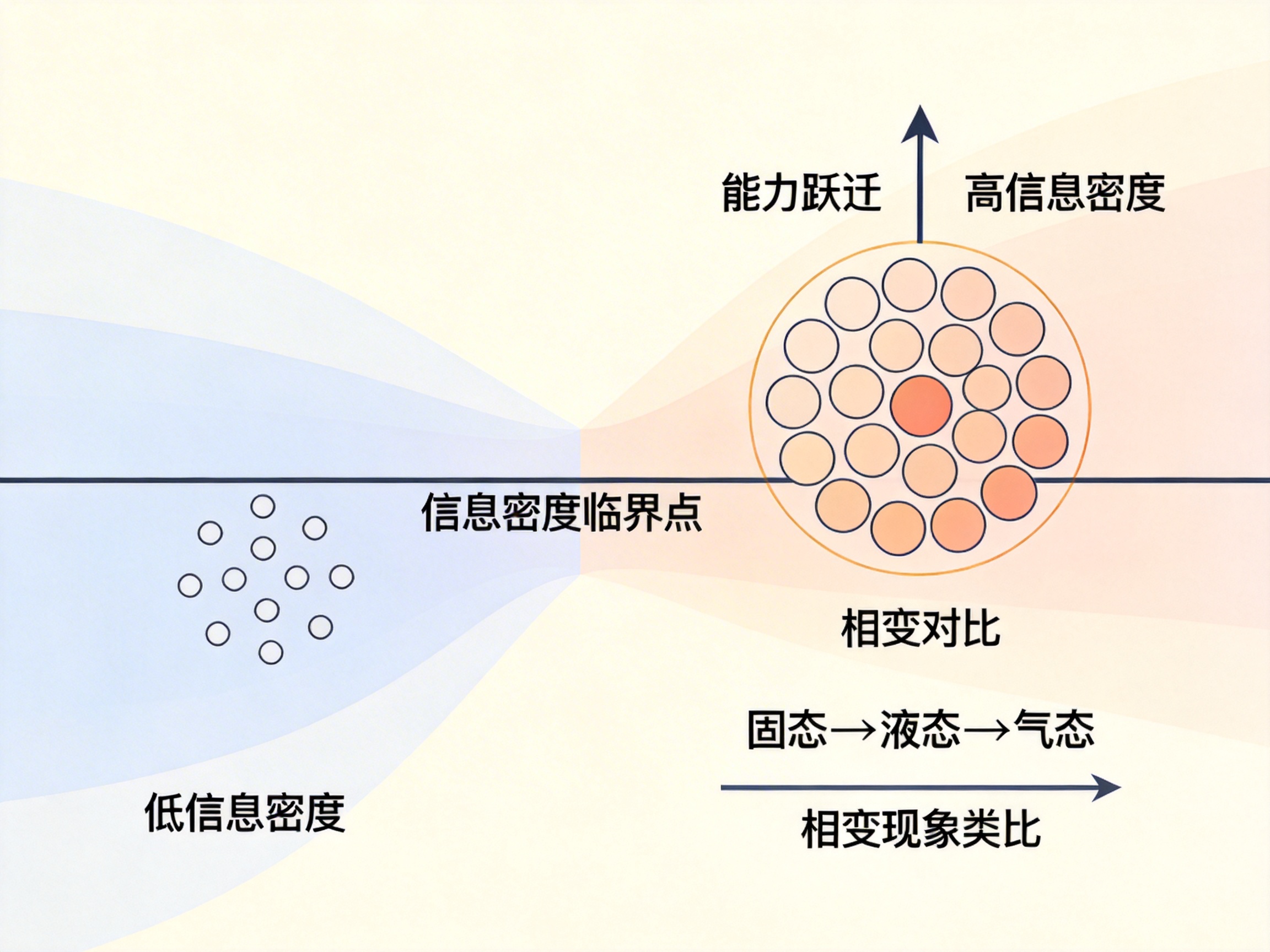
当信息密度达到某个阈值时:
系统会发生能力跃迁。
这并不是模型突然“学会思考”。
而是因为:
信息量首次足以支撑复杂结构推理。
这是一种典型的相变现象:
同样:
当信息密度足够高时,复杂智能行为自然涌现。
大语言模型本质上是无状态系统:
现实中的“记忆感”来自外部系统:
因此:
模型没有内生记忆,但可以在系统支持下表现出稳定记忆行为。

参数规模决定模型能“想多复杂”,
Context 决定模型能“看到多少”,
真正的智能水平,取决于推理时的信息密度。

```
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。