В этой статье я хочу остановиться на разборе предложенной мной архитектуры декодера и тех вариантов, с которыми я сравниваю её в исследовании, но сделать это проще и интуитивнее, чем в самой работе. На мой взгляд, существующие объяснения архитектур декодеров часто подаются разрозненно. Каждый подход описывают отдельно, без общей опоры. А ведь всё можно свести к одному фундаменту, и тогда становятся гораздо заметнее как сильные стороны каждого решения, так и их ограничения.
Для начала приведу все необходимые ссылки.
Само исследование: https://arxiv.org/abs/2604.18580
Структура статьи:
Transformer
Начнём с классики — трансформера, но посмотрим на него под другим углом: не на то, как он устроен и какие у него компоненты, а на то, как идейно к нему прийти. Для этого мы воспользуемся свёрткой. В нашем случае для простоты будем оперировать дискретными функциями со скалярными элементами.
К примеру, рассмотрим на входе последовательность из пяти элементов (слова, эмбеддинги и т. п.) и ядро из трех элементов. В классическом определении ядро свёртки отражается по нулю (переворачивается), но будем считать, что это уже сделано.
Наша цель — посмотреть, какую информацию такой миксер может извлекать из префикса последовательности. В decoder-only модели выход миксера затем используется для предсказания следующего элемента, но сначала рассмотрим саму операцию смешивания на примере длины 5.
Пусть вход
![]()
а ядро
![]()
Тогда выходы миксера на позициях могут быть, например,
![]()
В decoder-only модели такой выход в позиции t затем используется для предсказания следующего элемента ![]() Но дальше нас будет интересовать именно сам миксер: какую информацию из префикса он извлекает в позиции t. Поэтому
Но дальше нас будет интересовать именно сам миксер: какую информацию из префикса он извлекает в позиции t. Поэтому ![]() далее обозначает выход миксера, а не финальное предсказание следующего токена.
далее обозначает выход миксера, а не финальное предсказание следующего токена.
И, как видим, у нас есть две проблемы: ядро фиксировано по коэффициентам и имеет фиксированную длину окна. Такая свёртка в теории цифровой обработки сигналов называется FIR (Finite Impulse Response, конечный импульсный отклик) фильтром: его реакция на единичный импульс длится конечное число шагов, потому что ядро имеет конечную поддержку.
Попробуем исправить этот крайне неприятный недостаток: сделаем коэффициенты адаптивными относительно входа, например, просто через умножение ![]() . Тогда:
. Тогда:
![]()
и выход миксера в позиции t:
![]()
Например, если ![]()
![]()
При этом есть одно "но": даже если сделать коэффициенты зависящими от входа, это само по себе не снимает ограничения по длине. Пока мы работаем в фиксированном окне радиуса![]() , оператор остаётся локальным и видит только последние
, оператор остаётся локальным и видит только последние ![]() элементов. А если расширить суммирование на большее число позиций (вплоть до всего контекста), то при увеличении длины меняется режим вычисления: в сумме появляется больше слагаемых, и без нормировки выход начинает дрейфовать по масштабу и по распределению вкладов. Поэтому веса нужно сделать устойчивыми к росту
элементов. А если расширить суммирование на большее число позиций (вплоть до всего контекста), то при увеличении длины меняется режим вычисления: в сумме появляется больше слагаемых, и без нормировки выход начинает дрейфовать по масштабу и по распределению вкладов. Поэтому веса нужно сделать устойчивыми к росту ![]() , например, так, чтобы их сумма была фиксированной. И здесь естественно появляется softmax: он нормирует сырые коэффициенты в веса, суммирующиеся к единице, хотя, конечно, это ещё не attention как механизм как таковой.
, например, так, чтобы их сумма была фиксированной. И здесь естественно появляется softmax: он нормирует сырые коэффициенты в веса, суммирующиеся к единице, хотя, конечно, это ещё не attention как механизм как таковой.
В нашем примере:
![]()

![]()
Например, при ![]()
![]()
![]()
Несмотря на то что мы исправили две ключевые проблемы, такая система всё ещё не справляется со многими задачами. Возьмём, например, простую подзадачу для миксера: хотим, чтобы выход в позиции t извлекал предыдущий вход,
![]()
Это означает, что на каждом шаге вес на позиции ![]() должен быть больше, чем на позиции
должен быть больше, чем на позиции ![]() и на позиции
и на позиции ![]() В частности, достаточно следующих требований:
В частности, достаточно следующих требований:
![]()
Но softmax монотонен по своим аргументам: если ![]() то обязательно
то обязательно ![]() Значит из требований получаем:
Значит из требований получаем:
![]()
Получается противоречие: одновременно требуется ![]() и
и ![]()
Если интуитивно, то когда оценки зависят только от важности токена самого по себе, то есть фактически только от источника, модель не может менять предпочтение, кого копировать, в зависимости от шага ![]() Именно здесь и появляется необходимость в том, чтобы оценки зависели от того, кто читает и на что смотрит. И вот тут уже естественно появляется классический attention (с позиционным кодированием): вместо важности токена самой по себе, мы нормируем совместимость пары t
Именно здесь и появляется необходимость в том, чтобы оценки зависели от того, кто читает и на что смотрит. И вот тут уже естественно появляется классический attention (с позиционным кодированием): вместо важности токена самой по себе, мы нормируем совместимость пары t![]()
![]()

![]()
Где ![]() отвечает за позиционную информацию
отвечает за позиционную информацию
И на нашем примере с конечным окном ![]() мы смотрим только на
мы смотрим только на ![]() При
При ![]()
![]()
![]()
![]()
В общем виде, когда ![]() является вектором, вместо скаляра
является вектором, вместо скаляра ![]() используются линейные отображения для построения
используются линейные отображения для построения ![]() и
и ![]() с произвольным
с произвольным ![]() Вот и всё: теперь к этому attention добавляем MLP и получаем слой трансформера.
Вот и всё: теперь к этому attention добавляем MLP и получаем слой трансформера.
А теперь поговорим немного о свойствах этой архитектуры.
Память
Чтобы честно сравнить память трёх архитектур, нужно выбрать согласованный режим анализа. Потому что можно подобрать такие параметры, при которых каждая из них будет лучше другой, или наоборот. В контексте исследования я рассматривал контролируемый общий режим, в котором моделям сложно сфокусироваться на определённом элементе входной последовательности, то есть ломаем sharp retrieval. В случае трансформера это диффузный режим. А для самой оценки нужно понять, как выход в момент t чувствителен к токену в прошлом ![]() используя якобианы.
используя якобианы.
Для создания диффузного режима в трансформере достаточно, чтобы разброс логитов, то есть разница между максимальным и минимальным значением перед softmax, был ограничен константой, не растущей с длиной контекста. Тогда softmax не может устойчиво сконцентрировать почти всю массу на одном токене, и веса остаются распределёнными по большому числу позиций.
При этом я доказываю оценки для режимов:
Однослойный: Если рассматривать режим без заморозки коэффициентов attention, верхняя оценка равна:
![]()
А вот нижняя оценка из-за добавления градиента по коэффициентам attention тривиальна: она больше или равна нулю, потому что путь по коэффициентам attention может частично компенсировать value-путь, в худшем случае может почти занулить.
Многослойный: рассматриваем стек из ![]() слоёв attention и смотрим полный градиент от выхода на позиции t к входу на позиции
слоёв attention и смотрим полный градиент от выхода на позиции t к входу на позиции ![]()
В этом режиме верхняя оценка равна:
![]()
Глубина добавляет дополнительные маршруты через промежуточные позиции и даёт логарифмическое усиление по сравнению с одним слоем:
![]()
Но при фиксированной глубине ![]() влияние старых токенов всё равно затухает:
влияние старых токенов всё равно затухает:
![]()
А нижняя оценка, как и в однослойном режиме, остаётся тривиальной: она больше или равна нулю.
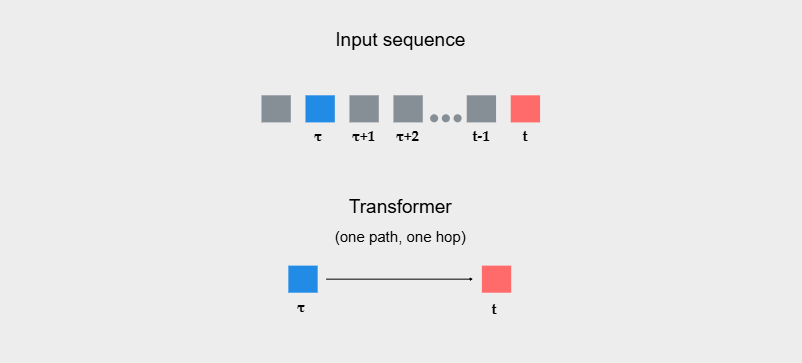
В исследовании я также ввожу термины one path / many paths (пути) и one-hop / multi-hop (переходы). Они интуитивно объясняют, почему в диффузных режимах память ведёт себя по-разному у трёх архитектур. В контексте трансформера и механизма внимания удобно представить маршрутизацию влияния как ориентированный ациклический граф (DAG) по временным индексам: для трансформера это граф с прямыми рёбрами ![]() (при
(при ![]() ), где вес ребра задаётся вниманием
), где вес ребра задаётся вниманием ![]() Тогда влияние из
Тогда влияние из ![]() в t внутри одного слоя реализуется одним переходом (one-hop) и по одному пути (one path). Так как интуитивно, обратиться к определённому элементу attention может только одним способом в одном слое — дать ему максимальный вес, то есть один путь и один шаг.
в t внутри одного слоя реализуется одним переходом (one-hop) и по одному пути (one path). Так как интуитивно, обратиться к определённому элементу attention может только одним способом в одном слое — дать ему максимальный вес, то есть один путь и один шаг.
S4D и Mamba
Целью данных SSM является исправить недостаток attention, а именно квадратичную сложность вычислений при росте длины последовательности, при этом оставаясь примерно на том же уровне качества на длинных контекстах. И в целом цель хорошая, если бы не несколько фундаментальных "но", которые мы в этом разделе обсудим. Но, чтобы прийти интуитивно к Mamba, мы сделаем это через промежуточный этап в виде S4D, возьмём нашу предыдущую LTI-систему и посмотрим на неё с другой стороны.
И вместо того, чтобы сначала делать коэффициенты адаптивными, а потом пытаться обобщить это на произвольную длину, сделаем наоборот: исправим сначала проблему конечного импульсного отклика, а потом уже будем думать про адаптивность. Основная идея такая: мы можем передавать дальше не только текущий взвешенный вход, но и состояние ![]() в котором накапливается прошлое. Тогда каждый новый вклад будет суммироваться с накопленным предыдущим, и система сможет помнить сколь угодно далёкий вход.
в котором накапливается прошлое. Тогда каждый новый вклад будет суммироваться с накопленным предыдущим, и система сможет помнить сколь угодно далёкий вход.
В цифровой обработке сигналов такая система известна как IIR-фильтр, а эта форма записи — как разностное уравнение. И теперь у нас есть кроме forward-ветки, которую мы рассматривали в предыдущем пункте ещё и feedback. И отталкиваясь от предыдущего пункта, мы учитываем как в нашем примере три последних ![]() и взвешиваем их коэффициентами
и взвешиваем их коэффициентами ![]()
![]()
Очевидно, что сейчас в качестве коэффициента в обратной связи мы используем единицу, но нам никто не мешает сделать его произвольным:
![]()
И тут всплывает довольно важный момент про устойчивость системы. Есть два близких, но разных способа на это смотреть.
BIBO-стабильность: если вход ограничен, то выход тоже должен оставаться ограниченным. Обычно это рассматривают при нулевом начальном состоянии.
Внутренняя устойчивость: если вход равен нулю, но начальное состояние ненулевое, то собственная динамика системы не должна разгоняться.
Рассмотрим простой случай:
![]()
где
![]()
Коэффициент обратной связи равен 1.
Если для наглядности взять постоянный вход ![]() то при
то при
![]()
получаем
![]()
Тогда
![]()
и значит
![]()
То есть выход растёт линейно. Поэтому при ![]() глобальную BIBO-стабильность в общем случае гарантировать нельзя.
глобальную BIBO-стабильность в общем случае гарантировать нельзя.
Коэффициент по модулю больше 1.
Если ![]() то система неустойчива. Это можно увидеть двумя способами.
то система неустойчива. Это можно увидеть двумя способами.
Во-первых, как нарушение внутренней устойчивости. Пусть вход равен нулю:
![]()
но начальное состояние ненулевое. Тогда
![]()
При ![]() это растёт экспоненциально.
это растёт экспоненциально.
Во-вторых, это можно увидеть именно как нарушение BIBO-стабильности. Возьмём нулевое начальное состояние и ограниченный импульсный вход:
![]()
Тогда выход будет содержать множитель
![]()
При ![]() он становится неограниченным. Значит ограниченный вход может породить неограниченный выход.
он становится неограниченным. Значит ограниченный вход может породить неограниченный выход.
Коэффициент по модулю меньше 1.
Если ![]() то собственная динамика затухает:
то собственная динамика затухает:
![]()
Кроме того, импульсный отклик такой системы имеет вид геометрической прогрессии. Поэтому вклад прошлого суммируется с экспоненциально убывающими весами, и при ограниченном входе выход остаётся ограниченным. В этом случае система является BIBO-стабильной.
Но при этом нам никто не мешает использовать произвольное число элементов для взвешивания в обратной связи. В общем виде разностное уравнение будет выглядеть как:
![]()
И здесь важно, что устойчивость уже описывается не одним числом ![]() а корнями характеристического уравнения, составленного из этих коэффициентов. Но это отдельная обширная тема. В данном случае достаточно просто принять это как факт. И дальше ситуация уже не так тривиальна, как с одним коэффициентом: отдельные
а корнями характеристического уравнения, составленного из этих коэффициентов. Но это отдельная обширная тема. В данном случае достаточно просто принять это как факт. И дальше ситуация уже не так тривиальна, как с одним коэффициентом: отдельные ![]() действительно могут быть по модулю больше 1, но при этом система всё равно может быть устойчивой, если все корни характеристического уравнения лежат внутри единичного круга.
действительно могут быть по модулю больше 1, но при этом система всё равно может быть устойчивой, если все корни характеристического уравнения лежат внутри единичного круга.
Теперь нужно связать разностное уравнение с формой миксера S4D, которая выглядит подобным образом в простом скалярном случае:
![]()
![]()
Здесь ![]() являются параметрами перехода состояния, и их не следует путать с коэффициентами
являются параметрами перехода состояния, и их не следует путать с коэффициентами ![]() в разностной форме
в разностной форме ![]()
И хотя на первый взгляд она кажется немного другой, так как у нас![]() параллельных фильтров, которые учитывают только предыдущее состояние, я сейчас покажу, как из неё получить разностное уравнение.
параллельных фильтров, которые учитывают только предыдущее состояние, я сейчас покажу, как из неё получить разностное уравнение.
Рассмотрим два состояния без входа: ![]() Для простоты возьмём
Для простоты возьмём ![]()
![]()
выпишем ![]()
![]()
Подставляем динамику в ![]()
![]()
Теперь у нас система:
![]()
Умножим первое уравнение на ![]() и вычтем из второго:
и вычтем из второго:
![]()
Сдвинем на один шаг назад:
![]()
Но по динамике второго состояния ![]() Домножим предыдущее равенство на
Домножим предыдущее равенство на ![]()
![]()
Значит правые части совпадают, и получаем:
![]()
![]()
И теперь если мы рассмотрим разностное уравнение для IIR фильтра:
![]()
То ![]() и
и ![]() равны:
равны:
![]()
При этом ![]() являются полюсами, а значит достаточно, чтобы они были по модулю меньше 1. Что и описывается в исследовании, посвящённом S4D.
являются полюсами, а значит достаточно, чтобы они были по модулю меньше 1. Что и описывается в исследовании, посвящённом S4D.
Теперь, чтобы увидеть, что такое Mamba, достаточно просто сделать коэффициенты внутри состояний зависимыми от входа, то есть:

При этом создатели архитектуры Mamba заложили подобную селективность:
![]()

И тогда, если представить миксер Mamba в виде разностного уравнения, то мы получим:
![]()
Данный вид получается из-за того, что параметры внутри каждого состояния зависят от входа, а значит их невозможно свести к одному коэффициенту при преобразовании в разностную форму.
Но при этом, как мы можем заметить, в разностной форме каждый коэффициент внутри окна зависит от входных данных в этом окне.
Как получить данную формулу.
Рассмотрим одно состояние:
![]()
где

В Mamba параметры ![]() зависят только от текущего токена
зависят только от текущего токена ![]()
Введём
![]()
![]()
Тогда для ![]()
![]()
Умножая на ![]() получаем
получаем
![]()
Обозначим
![]()
![]()
Тогда
![]()

Локальная невырожденность:
![]()
Тогда существует единственный набор коэффициентов
![]()
такой, что
![]()
![]()
Теперь
![]()
а для ![]()
![]()
Следовательно,
![]()
По построению
![]()
Значит
![]()
Правая часть является линейной комбинацией входов
![]()
Поэтому существуют коэффициенты ![]() такие что
такие что
![]()
Для ![]()
![]()
Следовательно,
![]()
Так как ![]() диагональна,
диагональна,
![]()
Значит
![]()
Поэтому ![]() зависит только от параметров на индексах
зависит только от параметров на индексах
![]()
а матрица ![]() зависит только от параметров на индексах
зависит только от параметров на индексах
![]()
Следовательно
![]()
зависит только от параметров на индексах
![]()
Но параметры индексов ![]() зависят только от
зависят только от ![]() поэтому
поэтому
![]()
![]()
Здесь все множители ![]() зависят только от параметров на индексах
зависят только от параметров на индексах
![]()
а коэффициенты ![]() зависят от
зависят от
![]()
Следовательно
![]()
Поэтому, при ![]() получаем
получаем
![]()
И теперь можно перейти к анализу свойств данной архитектуры.
Память
Как мы уже определились в предыдущем пункте, сравнение памяти должно быть честным и согласованным, и несмотря на то что в Mamba нет attention как в трансформере, за роль аналога диффузного режима будет отвечать величина ![]()
У Mamba есть режим, который в одном исследовании назвали freezing time, суть в том, что если ![]() то
то![]() , а
, а ![]() состояние сохраняется, а новый вход не попадает. А значит оно может в этом случае хранить его сколь угодно долго, напоминая режим attention с one-hot. Для контролируемого режима достаточно предположить, что этот механизм плохо работает и не может корректно определить, где заморозить время, а где нет (failed freezing time), то есть ломаем sharp retrieval. И для этого режима в исследовании я показываю оценки также для однослойного и многослойного вариантов.
состояние сохраняется, а новый вход не попадает. А значит оно может в этом случае хранить его сколь угодно долго, напоминая режим attention с one-hot. Для контролируемого режима достаточно предположить, что этот механизм плохо работает и не может корректно определить, где заморозить время, а где нет (failed freezing time), то есть ломаем sharp retrieval. И для этого режима в исследовании я показываю оценки также для однослойного и многослойного вариантов.
Однослойный. В этом режиме верхняя оценка равна:
![]()
Нижняя оценка в этом режиме тривиальна и будет больше либо равна нулю.
Многослойный. Рассматриваем стек из ![]() слоёв Mamba и полный градиент. В этом режиме верхняя оценка равна:
слоёв Mamba и полный градиент. В этом режиме верхняя оценка равна:
![]()
То есть глубина добавляет дополнительные маршруты через промежуточные слои и даёт полиномиальный множитель перед экспонентой, но общий характер памяти не меняется: экспонента всё равно доминирует. Например,
![]()
Но при фиксированной глубине![]() влияние старых токенов всё равно затухает:
влияние старых токенов всё равно затухает:
![]()
Нижняя оценка, как и в однослойном режиме, остаётся тривиальной: она больше либо равна нулю.
Но допустим мы рассмотрим отдельно реальную ситуацию с freezing time, и тут есть некоторые подводные камни, о которых я рассказываю в исследовании. Механизм заморозки опирается на распознавание по входным представлениям, а поскольку ![]() вычисляется как функция от входа, то когда разделимость сигнала падает и появляется шум в последовательности, распознавание может стать ненадёжным: модель не поддерживает режим
вычисляется как функция от входа, то когда разделимость сигнала падает и появляется шум в последовательности, распознавание может стать ненадёжным: модель не поддерживает режим ![]() на всём релевантном промежутке, и возникают шаги
на всём релевантном промежутке, и возникают шаги ![]() существенно больше нуля. Поскольку реальные последовательности часто содержат шум, подобный режим может встречаться довольно часто.
существенно больше нуля. Поскольку реальные последовательности часто содержат шум, подобный режим может встречаться довольно часто.
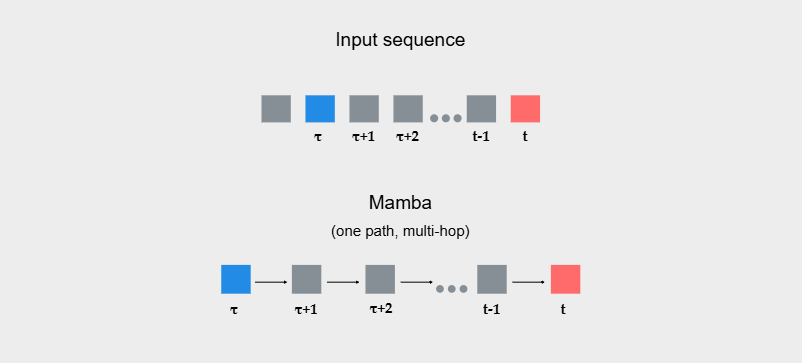
Ну и напоследок перед тем, как перейти к Sessa, представим маршрутизацию влияния в Mamba в виде ориентированного ациклического графа. Но он устроен иначе, чем в трансформере: это цепочка с рёбрами только между соседними шагами ![]() где вес ребра задаётся переходом состояния. Тогда влияние из
где вес ребра задаётся переходом состояния. Тогда влияние из ![]() в t внутри одного слоя проходит по одному пути
в t внутри одного слоя проходит по одному пути ![]() (one path), но требует
(one path), но требует ![]() последовательных переходов (multi-hop). Интуитивно, при фиксированной модели и произвольной последовательности, чтобы обратиться к далёкому элементу
последовательных переходов (multi-hop). Интуитивно, при фиксированной модели и произвольной последовательности, чтобы обратиться к далёкому элементу![]() модели нужно пройти через цепочку обратной связи. Как мы разбирали выше, динамика на каждом шаге учитывает только конечное число элементов в forward- и feedback-ветках. Поэтому получается один путь, но много переходов. Это и объясняет, почему Mamba часто имеет экспоненциальное затухание.
модели нужно пройти через цепочку обратной связи. Как мы разбирали выше, динамика на каждом шаге учитывает только конечное число элементов в forward- и feedback-ветках. Поэтому получается один путь, но много переходов. Это и объясняет, почему Mamba часто имеет экспоненциальное затухание.
Sessa: Selective State Space Attention
Теперь перейдём к архитектуре, которую я предлагаю как альтернативу Mamba и Transformer.
Идея заключается в том, чтобы объединить два направления: добавить feedback и одновременно сделать forward- и feedback-ветки адаптивными к текущему токену и длине последовательности. Иными словами, добавить feedback в Transformer используя attention.
Сам слой Sessa имеет вид:
![]()
после чего из ![]() строятся две ветки миксера: forward-ветка
строятся две ветки миксера: forward-ветка
![]()
и feedback-ветка
![]()
или, в параллельной матричной форме,
![]()
Финальный выход слоя равен
![]()
Если записать миксер в разностной форме, как в предыдущем пункте, получаем:
![]()
Как получить данную формулу.
![]()
Подставляя ![]() во вторую формулу, получаем
во вторую формулу, получаем
![]()
Теперь обозначим
![]()
Тогда
![]()
В случае трансформера это эквивалентно
![]()
В Mamba коэффициенты зависят от конечного окна входов, а более далёкая история передаётся через состояние. В Sessa же feedback-коэффициенты напрямую строятся по всему префиксу.
Теперь перейдём к свойствам.
Память.
Для сравнения памяти в случае Sessa применяется диффузный режим, аналогичный трансформеру. Для этого режима однослойный и многослойный вариант:
Однослойный: Если рассматривать полный градиент одного блока без заморозки весов attention:
![]()
У Sessa в этом режиме хвост ![]() с
с ![]() то есть медленнее хвоста Transformer
то есть медленнее хвоста Transformer ![]()
Нижняя оценка здесь тоже тривиальна и будет больше либо равна нулю.
Многослойный: рассматриваем стек из ![]() слоёв Sessa и полный градиент от выхода на позиции t к входу на позиции
слоёв Sessa и полный градиент от выхода на позиции t к входу на позиции![]() В этом режиме верхняя оценка равна:
В этом режиме верхняя оценка равна:
![]()
Эквивалентно, если смотреть на доминирующий по порядку член при фиксированной глубине, то можно писать:
![]()
То есть глубина здесь даёт не просто логарифмическое усиление, как у трансформера, а более сильное накопление вклада по мере композиции слоёв. Поэтому затухание может быть заметно медленнее.
Например,
![]()
При этом, если
![]()
то влияние старых токенов при фиксированной глубине всё ещё затухает. Вне этого режима теорема в таком виде гарантирует уже не обязательное затухание, а контролируемую верхнюю оценку.
Нижняя оценка, как и в однослойном режиме, остаётся тривиальной: она больше либо равна нулю.
Теперь перейдём к рассмотрению маршрутизации влияния в Sessa как ориентированный ациклический граф.
Допустим, мы применяем к начальному состоянию ![]() рекурентно миксер Sessa получая еще дополнительно три состояния
рекурентно миксер Sessa получая еще дополнительно три состояния ![]() Исходя из формул миксера, это будет выглядеть следующим образом:
Исходя из формул миксера, это будет выглядеть следующим образом:

подставим ![]() в
в ![]()
![]()
подставим ![]() и
и ![]() в
в ![]()

подставим ![]() в
в ![]()
![\begin{aligned} s_3 &= f_3 + B_{3,2}s_2 + B_{3,1}s_1 + B_{3,0}s_0 \\[4pt] &= f_3 + B_{3,2}\Big(f_2 + B_{2,1}f_1 + (B_{2,1}B_{1,0}+B_{2,0})f_0\Big) + B_{3,1}\Big(f_1 + B_{1,0}f_0\Big) + B_{3,0}f_0 \\[4pt] &= f_3 + B_{3,2}f_2 + (B_{3,2}B_{2,1}+B_{3,1})f_1 \\[4pt] &\quad + \Big( \underbrace{B_{3,2}B_{2,1}B_{1,0}}_{\text{путь }0\to1\to2\to3} +\underbrace{B_{3,2}B_{2,0}}_{\text{путь }0\to2\to3} +\underbrace{B_{3,1}B_{1,0}}_{\text{путь }0\to1\to3} +\underbrace{B_{3,0}}_{\text{путь }0\to3} \Big)f_0 \end{aligned}](https://irss.plus//node/data/uploads/original/image/c7/54/c7543f478f1c9f681e506ed0b9236841.svg)
Если посмотреть на коэффициент при ![]() то есть влияние из момента 0 в момент 3:
то есть влияние из момента 0 в момент 3:
![]()
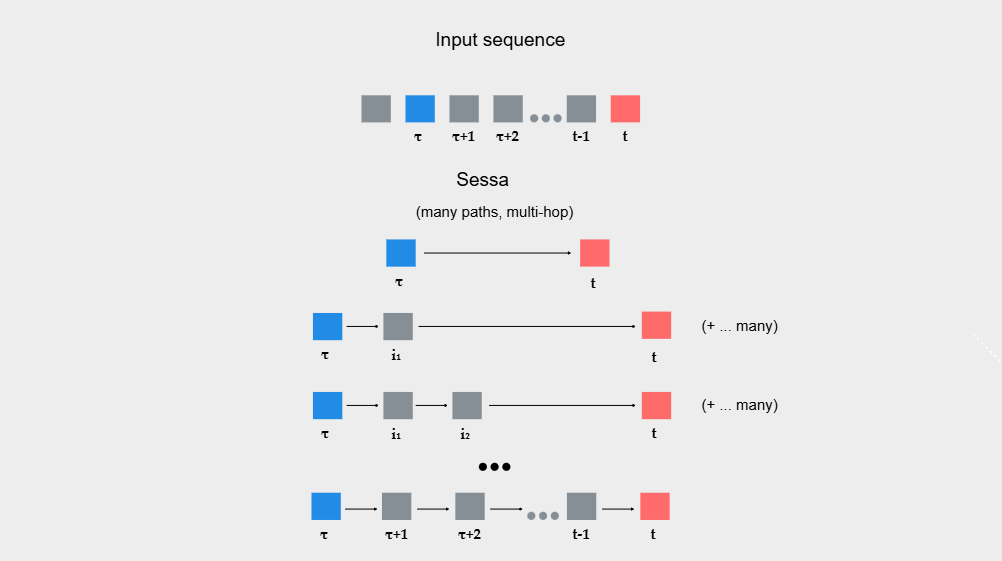
Можно выделить many paths и multi-hop:
Путь ![]() с одним переходом:
с одним переходом: ![]() ,
,
Путь ![]() c двумя переходами:
c двумя переходами: ![]() и путь
и путь ![]() также с двумя переходами:
также с двумя переходами: ![]() ,
,
Путь ![]() с тремя переходами:
с тремя переходами: ![]()
За счёт того, что модель может добираться до элементов различными путями, это и даёт более медленное затухание.
Если более интуитивно, то за счёт attention в feedback-части модель может обратиться к любому предыдущему feedback-шагу. Этот шаг, в свою очередь, уже учитывает предыдущие шаги, а также все входы через attention в forward-части. Поэтому и возникает множество путей с возможностью реализации множества переходов.
Гибкое селективное извлечение (flexible selective retrieval):
Это один из наиболее интересных и практически важных результатов. Суть в том, что в каждой из трёх моделей можно настроить параметры так, чтобы она без проблем извлекала необходимый вход. Но при анализе селективного извлечения лучше не смотреть только на якобианы, потому что память, транспорт нужного сигнала и селективность — это немного разные вещи. То есть память, которую мы рассматривали выше, отвечает за то, дошло ли влияние вообще. Транспорт нужного сигнала отвечает за то, дошёл ли именно нужный компонент. А селективность — за то, победил ли нужный источник всех конкурентов. И все эти три вещи нужны для данного анализа.
При этом у селективности есть три профиля:
Затухающий профиль. Чем дальше источник во времени, тем слабее гарантированная селективность. Модель всё ещё может извлекать нужный токен, но это становится всё труднее с ростом расстояния из-за того, что разница между текущим токеном и остальной массой затухает.
Замороженный профиль. Качество retrieval не деградирует с расстоянием, то есть по мере роста лага разница между текущим токеном и остальной массой остаётся одного и того же порядка.
Возрастающий профиль. Разница между текущим токеном и остальной массой может не просто не падать, а расти, то есть идет накопление преимущества.
Все три профиля в комбинации и дают гибкое селективное извлечение. Вне ограничительных режимов каждую из архитектур можно настроить так, чтобы она успешно извлекала нужный вход.
Но в диффузном режиме и его аналоге для Mamba различия становятся принципиальными. Суть в том, что он не только нужен как равноценный режим сравнения памяти, сам по себе он часто может возникать, особенно на длинном контексте, то есть коэффициенты attention начинают конкурировать за массу, или в последовательности немало шума и Mamba теряет нужный токен. А значит данный анализ полезен на практике для длинного контекста.
Каждая из архитектур с одним слоем может реализовать только затухающий профиль. Но когда слоёв становится два или больше, только Sessa может реализовать замороженный и возрастающий профиль. То есть диффузный режим для неё не проблема. Интуитивно это связано с тем, что в многослойной модели возникает столько путей ко входу, что, несмотря на диффузность внимания, сама структура памяти может сфокусировать всю эту массу на нужном входе.
Позиционное кодирование и универсальная аппроксимация.
Sessa, как и Mamba, может кодировать APE внутри себя без явных таблиц или экстраполяции, в отличие от трансформера. Следовательно, её можно обучать без встроенного позиционного кодирования, но стоит учитывать, что к нему или к его альтернативному варианту модель должна ещё прийти в процессе обучения.
Ну, а так как есть APE, то универсальная теорема аппроксимации для отображения последовательности в последовательность сама собой напрашивалась как дополнительный теоретический результат. И это довольно приятно, так как трансформеру для универсальной аппроксимации необходим именно внешний APE.
Итог
Как видно, модели декодеров можно описать на общем фундаменте, где явно проявляются их различия. В статье я сравнил только три архитектуры, но к этому списку вполне можно добавить и другие.
Что касается Sessa, в исследовании я был больше сфокусирован на теории. Но в ближайших планах обучить модель на несколько миллиардов параметров и посмотреть, что там уже с длинным контекстом на больших масштабах.
Если вы хотите поддержать это исследование, я был бы очень благодарен за ваш голос на Hugging Face. Спасибо!