Недавно я задался вопросом: можно ли организовать полноценный agent dev loop (то есть, цикл разработки агентов), используя только локальные модели? Идея заманчивая — гонять агента по задачам бесконечно, не оглядываясь на счета от OpenAI или Anthropic и не переживая за утечку кода.
Чтобы проверить это, я выделил кластер и столкнул лбами три тяжеловеса из мира open source. Спойлер: архитектурно они все — Senior‑разработчики, но когда дело доходит до docker-compose up, начинаются проблемы.

Что и на чём тестировали
Для тестов я выбрал три модели с Hugging Face (без квантования, в полных весах):
Qwen3.5–122B‑A10B — надежда на «убийцу GPT-4» от Alibaba.
Qwen3.5–27B — младшая модель, чтобы понять, есть ли смысл в 100B+ параметров.
Gpt‑oss-120b — специализированный «кодер» от OpenAI.
Инференс — vLLM внутри Kubernetes. Скорость работы была вполне комфортной, хотя итерации затягивались из‑за попыток моделей исправить собственные ошибки.
Почему стандартные бенчмарки нам не подошли?
Когда речь заходит об оценке кодинговых способностей LLM, все обычно смотрят на HumanEval или MBPP. Это классика, но у них есть огромная проблема: они проверяют «алгоритмический интеллект» в вакууме. Модель может идеально написать «быструю сортировку» или решить задачку с LeetCode, но при этом полностью завалить проектирование реального микросервиса.
Вот, что нас не устраивало в существующих решениях:
Snippet‑level vs System‑level. Большинство бенчмарков (включая популярный BigCode Bench) тестируют написание одной изолированной функции. В реальности же нам нужно, чтобы модель понимала структуру проекта, умела в Dependency Injection и видела связи между слоями.
Проблема заучивания (Data Contamination). Популярные задачи из бенчмарков уже давно попали в обучающие выборки моделей. Мы же хотели проверить работу на «свежем» ТЗ, которое модель не видела в интернете.
Игнорирование архитектуры. Существует SWE‑bench, который проверяет умение исправлять баги в реальных репозиториях. Это круто, но это тест на «сообразительного джуна‑ремонтника». Мы же хотели проверить роль «ведущего инженера» (Architect), который проектирует систему с нуля (Greenfield).
Отсутствие «эффекта домино». В обычных тестах каждая задача независима. В нашем Progressive Benchmark ошибка на уровне L1 (неправильно настроенный Alembic) гарантированно «взрывала» проект на уровне L3. Это проверка на долгосрочную консистентность решений, которую почти никто не замеряет.
Ближе всего к нашей задаче стоит Aider Leaderboard, но он фокусируется на редактировании существующего кода. Мы же пошли дальше и создали замкнутый цикл: локальный инференс → Greenfield‑задача → автоматическое ревью «строгим судьёй» (Sonnet 4.6).
Методология «Greenfield в пять шагов»
Чтобы тест был максимально приближен к реальности, я разбил процесс создания сервиса на пять этапов. В индустрии такие задачи принято называть User Stories (или просто «стори») — это описание функциональности с точки зрения ценности для проекта.
Для оценки прогресса я ввел внутреннюю шкалу сложности — Levels of Complexity (L1–L3). Это позволило мне понять, на каком именно этапе «интеллект» модели начинает пасовать перед инженерными реалиями:
L1 (Foundation): Скелет и окружение.
Это «нулевой цикл» строительства. Модель должна развернуть структуру папок, настроить зависимости и убедиться, что приложение просто стартует. Тест на знание инструментов (FastAPI, Alembic, Docker).L2 (Core & Architecture): Сердце и правила.
Здесь мы проверяем «чистоту» мышления. Модель должна спроектировать бизнес‑логику и правильно связать компоненты через Dependency Injection (DI). Здесь нет внешних баз данных, только чистые архитектурные паттерны.L3 (Infrastructure & Runtime): Выход в реальный мир.
Самый сложный этап. Приложению нужно научиться общаться с внешними системами — PostgreSQL и RabbitMQ. Здесь проверяется умение работать с асинхронностью, транзакциями и сетевыми задержками. Именно на L3 мы обычно прощаемся с надеждами на «полную автоматизацию».
Каждая следующая стори строилась на коде предыдущей. Если модель допускала архитектурную ошибку на L1, она неизбежно «стреляла себе в ногу» на L3.
Я не стал просить модели написать «сортировку пузырьком». Вместо этого я предложил им реализовать микросервис с нуля, проходя через 5 уровней сложности:
L1-01 (Skeleton): База на FastAPI, Alembic, PostgreSQL и структура папок по DDD.
L2-01 (DI & Use Cases): Внедрение зависимостей, репозитории через Protocol.
L2-02 (Domain Logic): Проектирование агрегата с инвариантами и иммутабельными Value Objects.
L3-01 (Persistence): Настоящий маппинг Domain ↔ ORM и транзакции.
L3-02 (Async Consumer): Интеграция с RabbitMQ (aio‑pika) с обработкой ретраев и идемпотентностью.
Правила игры были описаны в файле AGENTS.md. Агенту просто скармливали стори и просили: "Please implement the given story".
Кто судил?
Чтобы исключить «вкусовщину», я использовал Reviewer Agent на базе Claude Sonnet 4.6. У него был строгий промпт и 10-балльная шкала по трем метрикам:
IF (Instruction Following): Соблюдение правил из
AGENTS.md.CQ (Code Quality): Корректность архитектуры и выполнение требований стори.
CON (Conciseness): Отсутствие лишнего кода и овер‑инжиниринга.
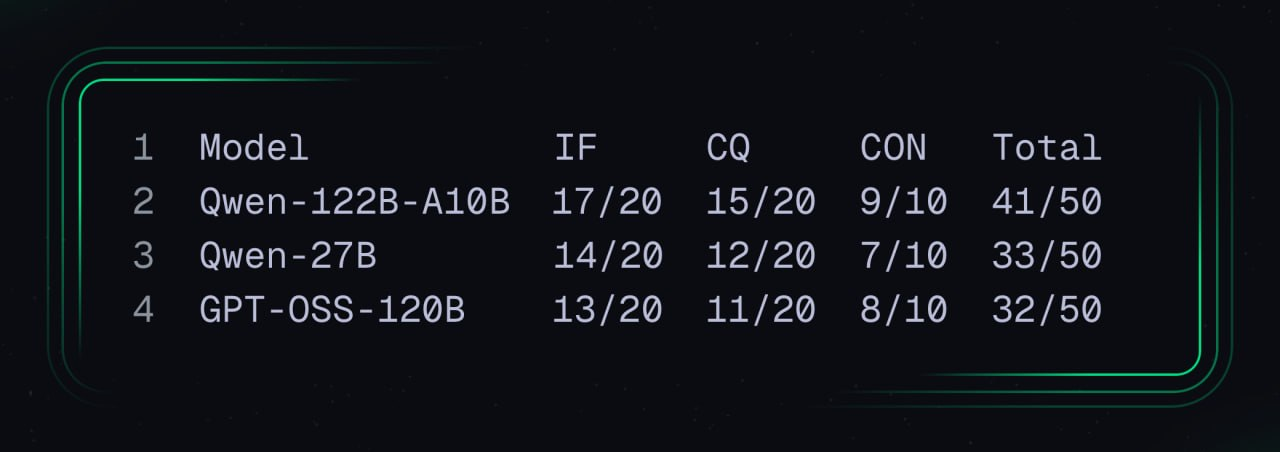
Результаты лидерборда
Модель | Итоговый балл | Вердикт ревьюера |
Qwen-122B‑A10B | 41/50 | «Архитектор» с тягой к самодеятельности |
Qwen-27B | 33/50 | Хороший теоретик, плохой практик |
GPT‑OSS-120B | 32/50 | Хаотичный Senior под дедлайном |
Более подробное распределение баллов можно увидеть на рисунке ниже:
Анатомия провалов: почему код не поехал
С первыми этапами все участники справились сравнительно легко. Самое интересное началось на уровнях L3, где нужно было связать всё воедино. Вот типичные подводные камни, о которые спотыкались модели.
1. Галлюцинации в инфраструктуре (GPT‑OSS-120B)
Модель столкнулась с ошибкой mypy при работе с Pydantic. Вместо того чтобы поправить аннотации, она решила... написать свой Pydantic. В корне проекта появился пакет pydantic/, где BaseModel была пустым датаклассом. Линтер успокоился, но рантайм, конечно, упал с TypeError на первой же попытке инициализировать юзера.
Кроме того, модель проигнорировала требование с PostgreSQL и настроила Alembic на SQLite. Почему? Потому что так проще пройти чеклист.
2. Асинхронные ловушки (Qwen-122B и 27B)
Работа с RabbitMQ (L3-02) также стала камнем преткновения.
Qwen-122B выдала отличную структуру, но допустила
AttributeError— попыталась обратиться к свойству.queueу объекта канала, которого там нет.Qwen-27B просто забыла про
awaitпри подтверждении сообщений (ack/nack). В асинхронном коде Python это фатально: корутина создается, но не выполняется, и сообщения копятся в очереди вечно.
3. Архитектурный карго-культ
Все модели отлично рисуют слои. Они знают, что domain не должен импортировать infrastructure. Но когда дело доходит до сшивки слоев через DI‑контейнер, они часто пасуют. Например, Qwen-27B создала репозиторий, который принимал сессию БД в __init__, но в конфиге DI она забыла её передать. Код выглядит красиво, но падает при первом же вызове эндпоинта.
Выводы: можно ли это использовать?
Мой главный инсайт по итогам эксперимента: локальные LLM знают паттерны, но не знают, что именно «ломается в 2 часа ночи».
В Greenfield‑проектах они идеальны как «генераторы скелетов». Сэкономить 2–3 часа на написании бойлерплейта, папок и базовых моделей — реально. Для agentic dev loop же полагаться на них целиком пока рано. Без внешнего «надсмотрщика» (вроде Sonnet 4.6), который будет бить их по рукам за ошибки в рантайме, они быстро превращают проект в нагромождение красивого, но нерабочего кода.
Самой ценной частью эксперимента оказались не сами модели, а идея с Judge LLM. Использование топовой модели (Sonnet 4.6 на момент написания этой статьи) в качестве автоматического ревьюера позволило выловить критические баги (вроде shadowing Pydantic), которые человеческий глаз может пропустить при беглом просмотре PR.
Что дальше?
Если вы планируете внедрять локальные LLM в разработку, мой совет: не тратьте время на написание идеального системного промпта для кодинга. Лучше инвестируйте в Reviewer Agent.
Если вы не ревьюите код от AI — вы не программируете, вы играете в «русскую рулетку».