Цены DeepSeek V4 Pro вышли в апреле 2026: $1.74 за миллион входных токенов, $3.48 за выходные. Claude Sonnet 4.6 стоит $3 и $15 соответственно. То есть в 1.7–4.3 раза дороже, в зависимости от пропорции input/output. На SWE-bench и GPQA модели идут плечом к плечу. Английские бенчи говорят: Sonnet чуть впереди по reasoning, DeepSeek чуть позади, но дешевле. Берите DeepSeek, не прогадаете.
На английских.
Я прогнал обе модели на 50 типовых задачах российского разработчика: извлечение полей из счёта-фактуры, классификация тикетов поддержки, расчёт зарплаты по ТК, расшифровка ЭДО/УПД/ОФД. Без больших фантазий, без OpenAI evals, без академических бенчмарков. Просто запросы, которые мы и так делаем по работе каждый день.
Получилось интересно. Половину DeepSeek закрывает на одном уровне с Sonnet. А в другой половине ломается так, что в проде это будет очень больно.
Что тестировал
Четыре блока, разбивка по типу задач.
1. Классификация тикетов поддержки, 20 промптов. Обращения клиентов, нужно отнести к одной из категорий: ОПЛАТА / ТЕХПРОБЛЕМА / ДОСТАВКА / ВОЗВРАТ / ОБЩИЙ_ВОПРОС. Системный промпт: «ответь одним словом». Базовый сценарий любого e-commerce-чатбота.
2. Извлечение полей из документов, 15 промптов. Счета-фактуры, договоры, акты, авансовые отчёты. Извлечь контрагента, ИНН, сумму, дату, номер. Возврат строго в JSON. Подвохи: OCR-ошибки, противоречие дат, ОГРНИП вместо ИНН, опечатки в прописи, НДС обратной формулой. То есть всё то, с чем приходится возиться, если автоматизируешь бухгалтерию.
3. Reasoning на специфике РФ, 10 промптов. Расчёт зарплаты на руки, увольнение на испытательном по соглашению сторон, срок исковой давности с правилом ст. 191-194 ГК, налоговый вычет на обучение детей, расчёт возврата аванса при расторжении.
4. Локальная терминология, 5 промптов. Расшифровка профессиональных аббревиатур (ЭДО, УПД, ОФД, КИЗ, ВЭД), перевод айтишного жаргона на русский корпоративный.
Прогон через web-интерфейсы. Sonnet 4.6 без adaptive thinking, DeepSeek V4 в режиме «Быстрый» без deep thinking. Оба в базовом режиме, как у обычного пользователя.
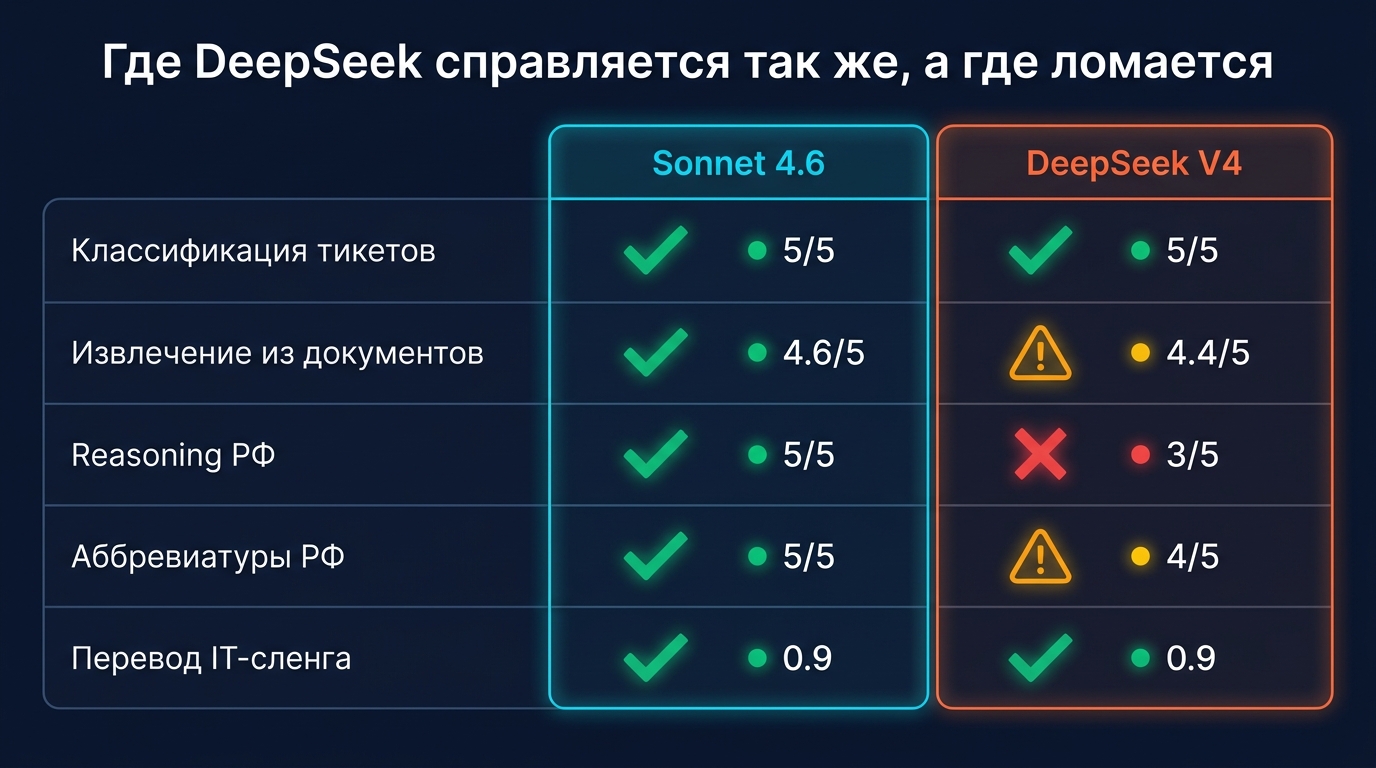
Где обе модели справляются одинаково
Простая классификация: обе по 5/5. Тикет про задержку трек-номера → ДОСТАВКА. Жалоба на бракованный утюг → ВОЗВРАТ. Вопрос про промокод → ОБЩИЙ_ВОПРОС. Двойное списание подписки → ВОЗВРАТ. Спорный кейс с несовпадением статусов оплаты обе единогласно отнесли к ТЕХПРОБЛЕМЕ, то есть не к моему golden ОПЛАТА, но между собой согласились. Для меня это значит: если делаешь чатбот для поддержки на 1-й линии, переплачивать за Sonnet смысла нет. DeepSeek тут полная замена.
То же самое с базовым reasoning. Срок исковой давности до 05.03.2026: обе ответили правильно с точностью до дня. Возврат аванса 15% от договора посчитали обе. Увольнение на испытательном: обе сказали что прав работник, обе сослались на ТК (Sonnet на ст. 71, DeepSeek на ст. 78), оба верно, просто с разных сторон.
В извлечении полей тоже большая часть совпадает. ОГРНИП обе не путают с ИНН, оставляют поле null, как и должны. Опечатку «четыресто» в прописи обе игнорируют, берут цифры из строки «Цифрами: 471 100 руб.». Авансовый отчёт с двойным НДС обе разбирают правильно: берут полную сумму с НДС, не вычитают из неё, и дату документа, а не дату чека.
Если 80% задач такие, переход на DeepSeek сэкономит ~75% бюджета без потери качества. Это не маркетинг, это арифметика.
Где DeepSeek ломается
Дальше идут детали, ради которых статья и пишется.
Налог на доходы. DeepSeek посчитал лишние 13.3%
Промпт: сотрудник в Москве, оклад 150 000 руб., налоговый резидент РФ, сколько на руки за месяц.
Sonnet: 130 500 руб. Это правильный ответ. НДФЛ 13% от 150 000 = 19 500, на руки 130 500.
DeepSeek: 110 550 руб.
То есть DeepSeek удержал 26.3%. Почти ровно вдвое больше реального НДФЛ. Откуда взялись лишние 13.3%, модель не объяснила (промпт просил только число). Похоже, добавила страховые взносы. Но они платятся работодателем, не из зарплаты сотрудника. Это распространённая путаница даже у самих сотрудников, и DeepSeek её повторила.
Если ты автоматизируешь зарплатный расчёт через LLM, и эта ошибка проскочит в систему, ты выдашь сотруднику в 1.18 раза меньше денег, чем должен. На зарплате 150К это минус 19 950 рублей в месяц. На команде из 30 человек получается почти 600 000 в месяц «недоплачено» по версии модели. Где-то на третий день кто-то откроет 1С и разнесёт это всё в новостях.
OCR-ошибки в номере документа. Sonnet чинит, DeepSeek нет
Скан счёта-фактуры с типичными OCR-артефактами: русская «н» в ИНН распозналась как английская H, нули прочитались как буквы O, единица как маленькая l. Текст промпта (в оригинале как есть):
Сцет № СФ-2O26/O412 om 14 апpеля 2026 г.
Поставщuк: ООО "Технополuс", ИHН 7728l23456...
Сумма k оnлaте: 248 5OO руб.
Обе модели в JSON выдали правильную сумму (248 500), правильный ИНН (7728123456, заметили l → 1), правильную дату. До этого момента ничья.
Но в поле «номер документа» Sonnet выдал нормализованный вариант: «СФ-2026/0412». А DeepSeek оставил как есть в исходнике: «СФ-2O26/O412».
Это критично. Если сравниваешь номер документа с базой 1С через WHERE number = ?, у тебя в одном случае будет совпадение, в другом нет. И ты будешь искать дубликат счёта или пропавшую запись, ругаться на OCR, копать индексы. А проблема в том, что половину документов модель привела к каноническому виду, половину оставила с буквами вместо цифр.
Sonnet не идеален в этом: на длинных текстах он тоже иногда оставляет артефакты. Но в этом тесте он зачистил все четыре OCR-подмены последовательно, а DeepSeek справился только с тремя из четырёх. Pattern matching в номерах у Sonnet чуть строже.

Налоговый вычет. DeepSeek сам себе противоречит
Это самый странный кейс. Промпт:
Отец оплатил обучение 25-летнего сына в магистратуре по очной форме (стоимость 200 000 руб./год). Может ли отец получить социальный налоговый вычет за обучение сына? Ответь: ДА или НЕТ + 1 предложение почему.
По ст. 219 НК РФ возрастной лимит для вычета на обучение детей: до 24 лет. 25 уже нельзя. Правильный ответ: НЕТ.
Sonnet:
НЕТ. Социальный налоговый вычет за обучение детей предоставляется только до достижения ребёнком 24 лет (пп. 2 п. 1 ст. 219 НК РФ), а сыну уже 25.
Чисто, со ссылкой на статью, к делу.
DeepSeek:
ДА, потому что отец имеет право на вычет за обучение родного сына в возрасте до 24 лет по очной форме, но в данном случае сыну уже 25 лет, что превышает установленный возрастной лимит.
Видишь? Первое слово: ДА. Дальше идёт объяснение, которое сводится к НЕТ. Модель сама с собой не согласна в одном предложении.
Если ты парсишь первое слово ответа в pipeline (а в большинстве prompt-инженерных решений именно так, берёшь префикс «ДА» или «НЕТ» через startswith), у тебя на этой выборке будет неправильный класс. Ассистент скажет «оформляйте вычет», бухгалтерия отправит документы, ФНС откажет, клиент вернётся с претензией. Sonnet в этом тесте такого не делал ни разу.
Аббревиатура КИЗ. DeepSeek фантазирует
Промпт: расшифруй ЭДО, УПД, ОФД, КИЗ, ВЭД через запятую.
Sonnet: «электронный документооборот, универсальный передаточный документ, оператор фискальных данных, контрольный идентификационный знак, внешнеэкономическая деятельность». Пять из пяти.
DeepSeek: первые три и пятый расшифровал правильно. На КИЗ выдал: «Код идентификации запчасти (код идентификации изделия)».
Это не правильная расшифровка. КИЗ в контексте бухгалтерии и ОФД это контрольный идентификационный знак системы маркировки «Честный знак». Применяется к одежде, обуви, табаку, парфюмерии, ко всему, что попало под обязательную маркировку. К запчастям он отношения не имеет.
Модель угадала контекст («идентификация»), но не угадала специфику РФ. Похоже, в обучающих данных DeepSeek просто меньше материалов про российскую систему маркировки, чем у Sonnet.
Сводная таблица
Категория (всего промптов) | Sonnet 4.6 | DeepSeek V4 | Где DeepSeek хуже |
|---|---|---|---|
Классификация тикетов (20) | 100% | 100% | — |
Извлечение из документов (15) | 92% | 88% | OCR-нормализация |
Reasoning РФ-специфика (10) | 100% | 60% | НДФЛ, ст. 219 НК |
Локальная терминология (5) | 100% | 80% | КИЗ → выдумка |
В сухом остатке:
На простых задачах паритет
На задачах со спецификой РФ Sonnet надёжнее в среднем на ~15%
DeepSeek склонен фантазировать там, где не уверен. Особенно в локальных нюансах
Цены и решение
DeepSeek V4 Pro: $1.74 / $3.48 за 1M input/output. Sonnet 4.6: $3 / $15. По input разница 1.7x, по output 4.3x. На реальной нагрузке (где output обычно короче input) разница ~3x.
То есть, чтобы переплата за Sonnet была экономически оправдана, его «дополнительная точность» должна окупать 3-кратную разницу в цене. На каких задачах это работает.
🟢 Берите DeepSeek, если задача из списка: классификация, базовый перевод, типовой Q&A, генерация шаблонных ответов, простой code completion. Большинство сценариев чатбота 1-й линии. Внутренние ассистенты, где ошибка не превращается в финансовое решение. Прототипы и MVP.
🟡 Думайте, если задача из этих: extract из плохо отсканированных документов, генерация текста с цифрами для бизнес-отчётов, reasoning по российскому законодательству на простых нормах. Тут DeepSeek работает, но иногда фантазирует. Можно использовать как первый прогон + валидация Sonnet/правилами на ключевых полях.
🔴 Берите Sonnet, если задача из этих: расчёты с деньгами на основе НК/ТК РФ, генерация юридических заключений, любая задача где первое слово ответа парсится в систему как класс, OCR-нормализация номеров, маркировка/таможня/ВЭД. То есть всё, где галлюцинация = реальная финансовая или юридическая боль.
Что я понял после прогона
Первое. Английские бенчмарки нам не помогут выбрать модель для российской задачи. На GPQA и SWE-bench DeepSeek и Sonnet почти равны. На НДФЛ и КИЗ разница пропасть. Локальный домен это не про размер модели, это про данные обучения. Sonnet видел больше русских документов, статей НК, корпоративных переписок. И это видно.
Второе. Цена за токен ничего не значит без оценки риска ошибки. Если у тебя 100 000 запросов в месяц и ошибка на одном из 100, это 1000 неправильных ответов. На чатботе про скидки пофиг. На расчёте зарплаты катастрофа. Всегда смотри на стоимость одной ошибки в твоей системе.
Третье. Самопротиворечивые ответы (как в R4, где DeepSeek сказал «ДА» и сразу же объяснил почему «НЕТ») это худший тип ошибки. Они проскальзывают через простую валидацию по первому слову, проскальзывают через простую регулярку, и ловятся только если читать ответ целиком. Когда строишь pipeline на LLM, добавляй валидацию consistency, особенно для DeepSeek.
И четвёртое, банальное. Прежде чем переходить на новую модель, гоняй её на своих 30-50 типовых запросах. Не на бенчмарках, не на чужих обзорах. На своих. Пара часов работы, и ты понимаешь, что вы получите в проде.
DeepSeek V4 действительно дешевле. Но «дешевле» и «лучше для твоей задачи» это не одно и то же.