One unique experience I have that is different from most is my time at YouTube and Google working with Fact Checking and YT News. And one of the most complicated and interesting problems we faced was presenting a breaking news story in the most factual way possible.
The journey from a journalist's keyboard to your phone's notification bar is a multitiered, multistep, instantaneous, and fault tolerant process, orchestrated on the terabytes! It relies on a combination of real-time data collection, advanced cluster algorithms, and natural language processing!
Understanding this process is key to understanding the modern news landscape. It's about seeing beyond the headline and grasping the machinery that shapes what we read. Let's break down the three main stages of how these large tech companies (Google, Meta, X, among many others) identify and define news stories.
The steps are
The first step in this process is the relentless, real-time collection of data. Google's web crawlers, for example, are constantly scanning the web for new and updated content. When it comes to news, this process is even more accelerated. The system doesn't just wait for a weekly sweep; it is specifically designed to recognize news sources and check them for updates in a matter of seconds.
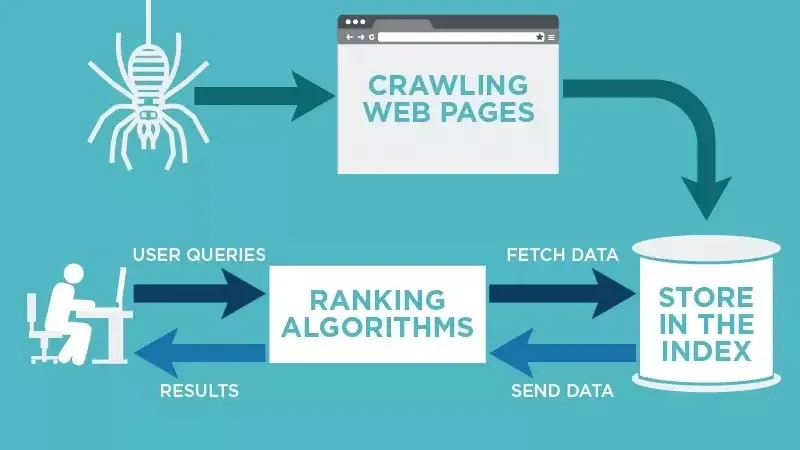
This process, known as web scraping, involves automated programs that visit millions of websites, extracting specific pieces of information. For a news article, this could include the headline, the body of the text, the author, the publication date, and any images or videos. They're not just looking at major outlets like The New York Times or the BBC; they are scraping thousands of local, national, and international news sources. This massive, continuous flow of data is the raw material from which news stories are built.
The goal here is not to understand the content yet, but simply to gather as much of it as possible, as fast as possible. “Quantity over quality” is the name of the game here. The system is essentially building an enormous, ever-changing library of all the new information being published on the internet at any given moment.
Once the data is collected, the next challenge is to make sense of it. A single event, like a natural disaster or a political announcement, will be reported by dozens, if not hundreds, of different news outlets. Each article will have a different headline, a different lead paragraph, and a slightly different angle. The task of the AI is to recognize that all these separate articles are actually about the same underlying event. This is where clustering comes in.
Clustering is an unsupervised machine learning technique that groups similar items together without any pre-defined categories. In the context of news, the AI analyzes the content of each article. It looks at the words used, the names of people and places mentioned, and the overall context. It then uses this information to calculate a "similarity score" between articles. Articles with a high similarity score are grouped together into a single cluster.
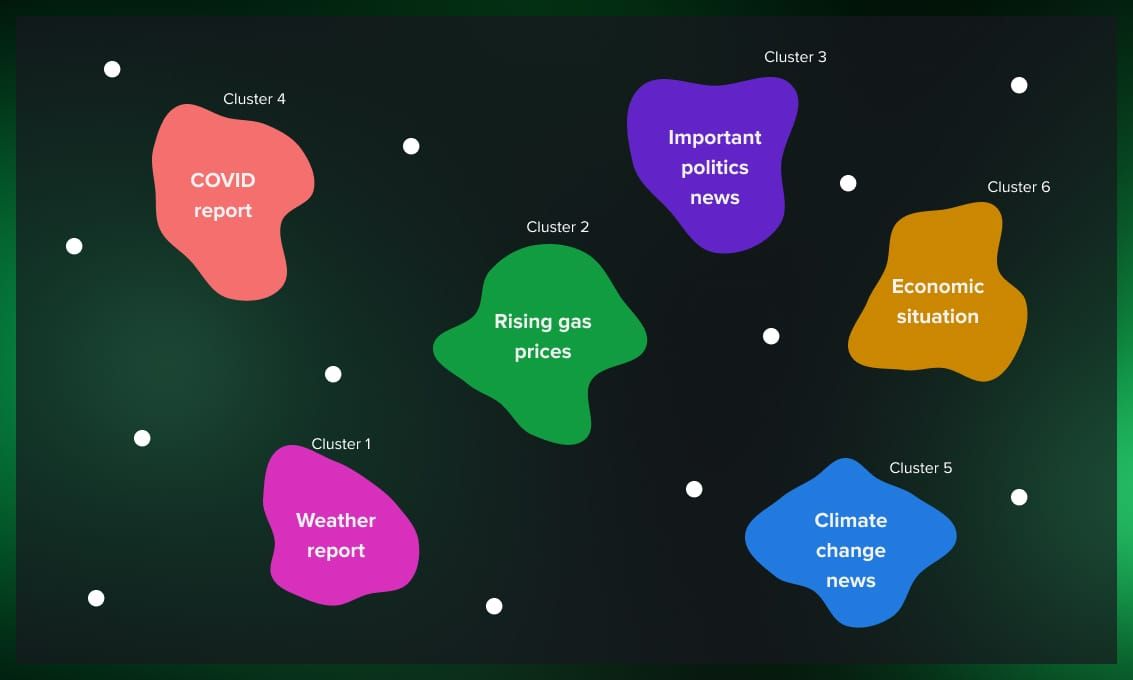
For example, a news article from Reuters, one from a local paper in California, and another from a foreign news agency, might all report on the same wildfire. Despite their different titles and writing styles, the AI would recognize that they all mention the same location, the same time frame, and similar key phrases like "wildfire," "evacuation," and "containment efforts." It would then place all these articles into a single cluster, which it now identifies as a unique "story." This is why when you go to Google News, you see a single headline with a carousel of different articles. The system is showing you that cluster!
The final stage is turning these clusters of articles into a coherent, single news story that a user can understand at a glance. This involves information extraction, which is the process of pulling out the most important facts from the cluster of articles.
The AI analyzes all the articles within a cluster to identify the who, what, when, where, and why of the event. It might determine that the most common headline theme is "Hurricane Hits the Coast," and that the most frequently mentioned location is "Florida." It would also extract key details like the number of people affected, the names of any officials involved, and the most recent updates on the situation.
The system then uses this extracted information to generate a concise summary and a compelling headline. It might also use the information to organize the story, creating a timeline of events or highlighting specific facts in a "key updates" section.
💡
The 3 steps to get Real Time News Stories are: Web Scraping, Clustering, and Info Extraction
The ability of these systems to process, cluster, and synthesize information in real-time has fundamentally changed how we consume news. It has created a world where you can get a broad overview of a global event from multiple perspectives with a single click. It also raises important questions about the role of human editors and the potential for these algorithms to inadvertently amplify certain narratives. The next time you see a breaking news alert on your phone, take a moment to think about the complex journey it took to get there.
I'm curious to hear your thoughts on this. Do you think the automation of news aggregation is a net positive for journalism, or does it come with hidden dangers? What are the benefits of a single, clustered news story versus reading individual reports from different outlets? Share your opinions in the comments below.
Sources:
A Survey of Information Extraction Based on Deep Learning. (n.d.). MDPI. https://www.mdpi.com/2076-3417/12/19/9691
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。