HDFS 即分布式文件系统(Hadoop Distributed File System)。HDFS 具有高容错性,且能运行在低廉的硬件上。HDFS 提供对应用程序数据的高吞吐量访问,适用于具有大数据集的应用程序。
NameNode 和 DataNode
HDFS 具有 Master/Slave 架构,根据名字可以联想到古时候奴隶主和奴隶的关系。一个 Hadoop 集群由单个 NameNode 和多个 DataNode 组成。
- NameNode
- 负责客户端请求的响应
- 负责元数据的管理,比如文件名称、副本系数、数据块存放的位置等
- DataNode
- 通常是集群中每个节点一个,存储文件对应的数据块(Block)
- 定期向 NameNode 发送心跳信息,汇报本身及其所有的 block 信息
HDFS 暴露了一个文件系统并允许用户数据存储在这些文件中。此外,一个文件会把被拆分到一个或多个数据块(block)中,这些数据块就存储在一系列 DataNode 中。NameNode 则是执行诸如打开、关闭、重命名文件和文件夹等文件系统操作,并且它还决定了数据块到 DataNode 的映射,即哪个数据块在哪个 DataNode 中,是由 NameNode 来决定的。DataNode 负责提供来自文件系统客户机的读写请求,还会根据来自 NameNode 的指令来执行对数据块的创建、删除和复制。
PS 文件拆分的依据是由底层的 blocksize 来决定。如果 blocksize 定义为 128M,那么对于一个 130M 的文件就会被拆分成两个分别为 128M 和 2M 的文件。
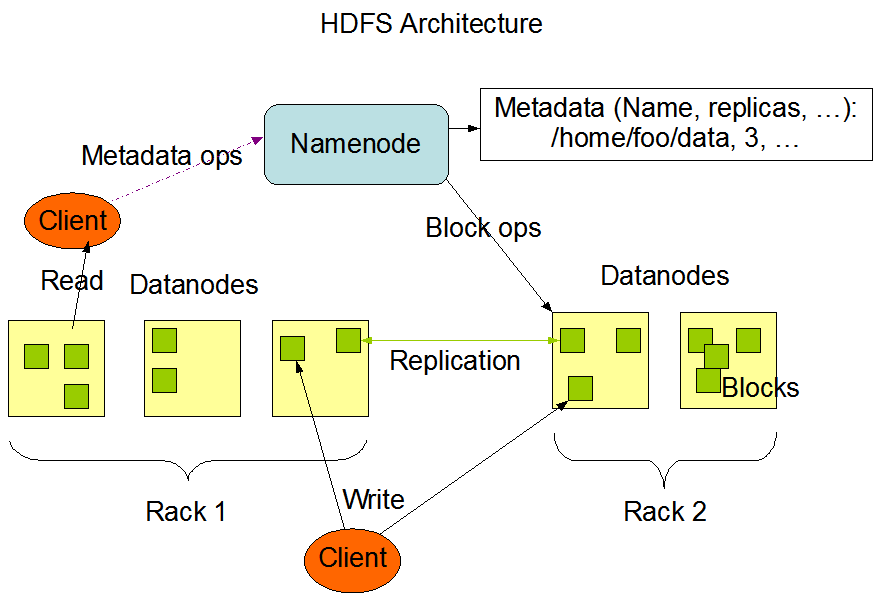
NameNode 和 DataNode 可以运行在廉价的机器上,通常是运行在具有 GNU/Linux 操作系统的机器上。HDFS 由 Java 语言构建,所以任何支持 Java 的机器都可以运行 NameNode 和 DataNode。
一个典型的部署方式是一个专有机器运行 NameNode,其它每台机器运行一个 DataNode。当然,并不排除一台机器运行多个 DataNode,但是在实际情况中很少发生。
文件系统命名空间
HDFS 支持传统的层级文件结构。用户或应用可以创建文件夹并在文件夹内存储文件。文件系统命名空间与其它大多数现存的文件一同类似,支持文件的创建、删除,移动和重命名。
NameNode 维护着文件系统命名空间。任何对命名空间或对它的属性的改变都会被 NameNode 记录下来。应用可以指定 HDFS 应当维护的文件副本系数。文件副本系数也叫做文件的副本因子(Replication Factor),这些信息由 NameNode 进行存储。
数据副本
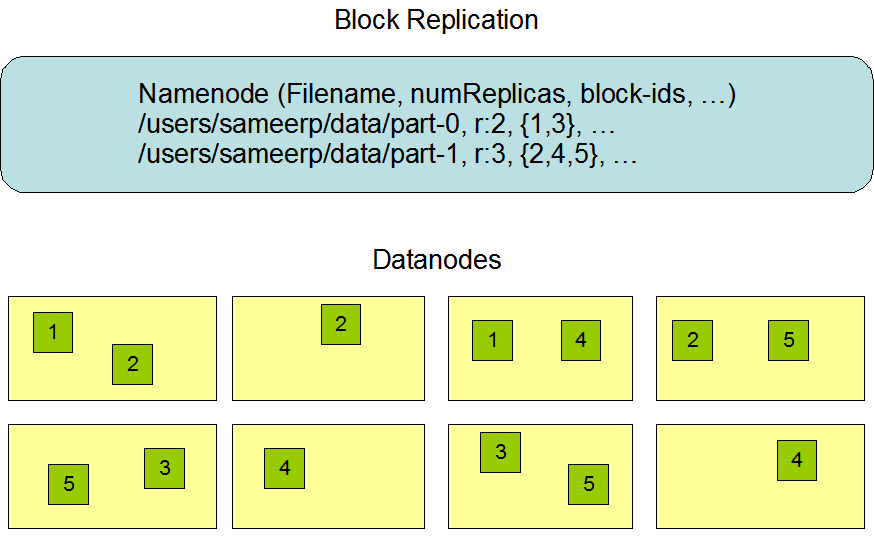
HDFS 旨在可靠地在大型集群中跨机器存储大文件,将文件存储为一系列数据块中。为了实现容错,一个文件的数据块会被复制多份。数据块大小和副本因子可以根据文件进行配置。
所有数据块中除了最后一个数据块之外的大小都是相同的。
应用可以指定文件的副本数。副本因子可以在文件创建时指定并可以在以后进行更改。HDFS 中的文件是一次写入的(除非追加和截断),并且任何时候只能有一个 Writer,并不支持多并发。
NameNode 会根据数据块的副本作出决定。它会定期接收集群中每个 DataNode 的心跳(Hearbeat)和数据块报告(Blockreport)。收到心跳意味着这个 DataNode 是正常工作的。数据块报告则包含 DataNode 上所有数据块的列表。
HDFS 优缺点
- 数据冗余、硬件容错
- 适合存储大文件
- 处理流式的数据访问
- 可构建在廉价机器上
缺点:
- 低延迟的数据访问
- 不适合小文件存储