At VTEX, ensuring our payment processing flow operates with maximum efficiency is critical to providing a seamless shopper experience. As our transaction volume naturally expands, we identified a valuable opportunity to modernize and optimize our core database architecture.
Historically, one of the main relational databases supporting our payment processing flow stored more than 20 TB of data and expanded by approximately 800 GB per month. To proactively improve our service capacity, maintain low latency, and optimize our infrastructure, our engineering team designed a comprehensive solution based on two main pillars: modernizing legacy data structures with advanced compression and implementing an automated database tiering architecture. The first pillar focused on reducing the size and write cost of each payload, and the second focused on keeping the hottest data in the most efficient storage layer.
This was not yet causing direct merchant impact, but it was a clear scalability risk. The database required special attention during Black Friday preparation and load tests, and its growth rate indicated that continuing with the same data model would increase operational overhead and eventually raise the risk of a critical incident over time.
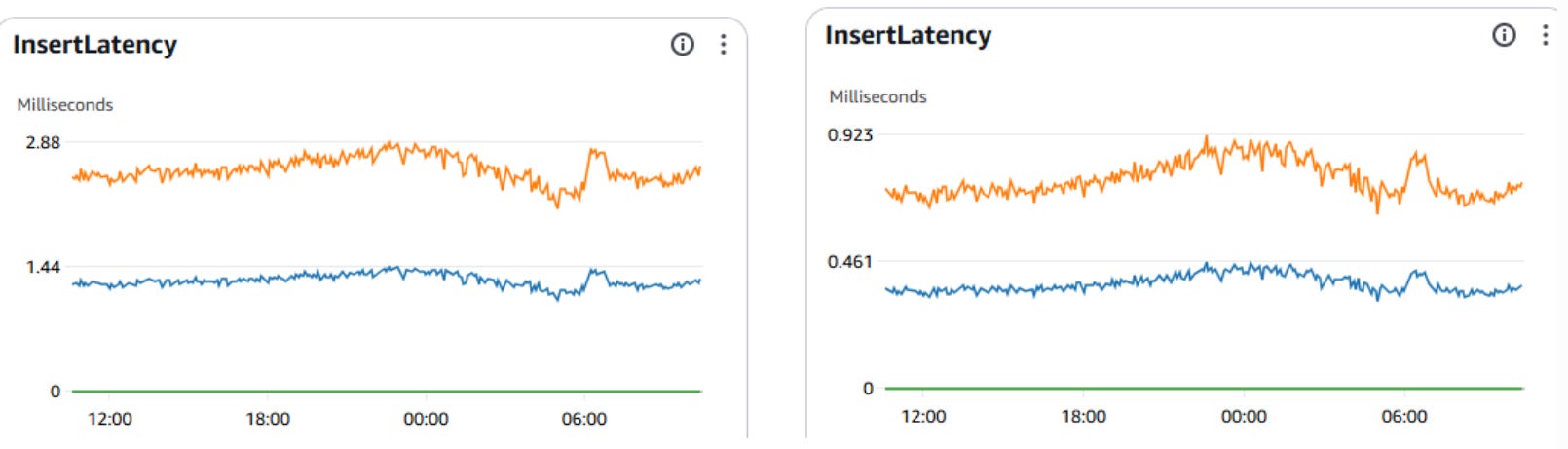
We successfully reduced database insert latency by 68%, bringing 2.88 ms operations to 0.92 ms. For a high-performance payment gateway, this improvement on the critical flow, performance is not just a nice-to-have, it is a requirement. This 68% reduction materially lowered write pressure on the database and improved the reliability of our platform.
Here is a deep dive into how we engineered this optimization.
Incorporating AI into our daily engineering practices has become a key driver for our productivity and work model. For this project, AI-driven analysis supported us by clustering payload patterns, inspecting script outputs, identifying compression opportunities, comparing benchmarks, and accelerating the generation of experimental code.
One of the contributors to our payload size was the use of a legacy XML structure for storing payment and transaction data. Our first step was to migrate this data representation from XML to JSON. For our application, the JSON is not only easier to manipulate in modern application flows, but it also requires fewer characters natively, immediately reducing our storage footprint.
To push the optimization further, we decided to compress the JSON data using algorithms that rely on dictionaries to optimize compression. Because the new approach relies on dictionaries to optimize compression and decompression speeds on repeating data patterns, such as ours, we conducted extensive empirical tests to find the ideal balance between chunk sizes and dictionary sizes.
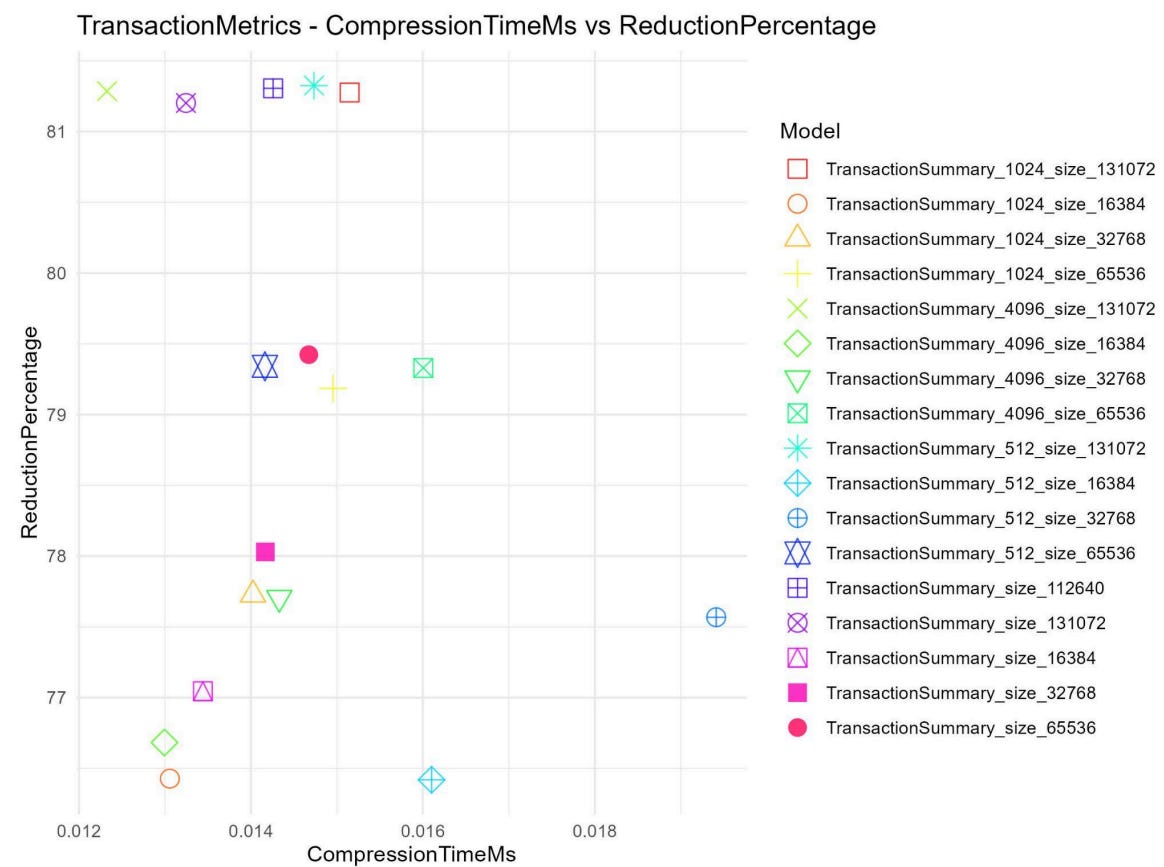
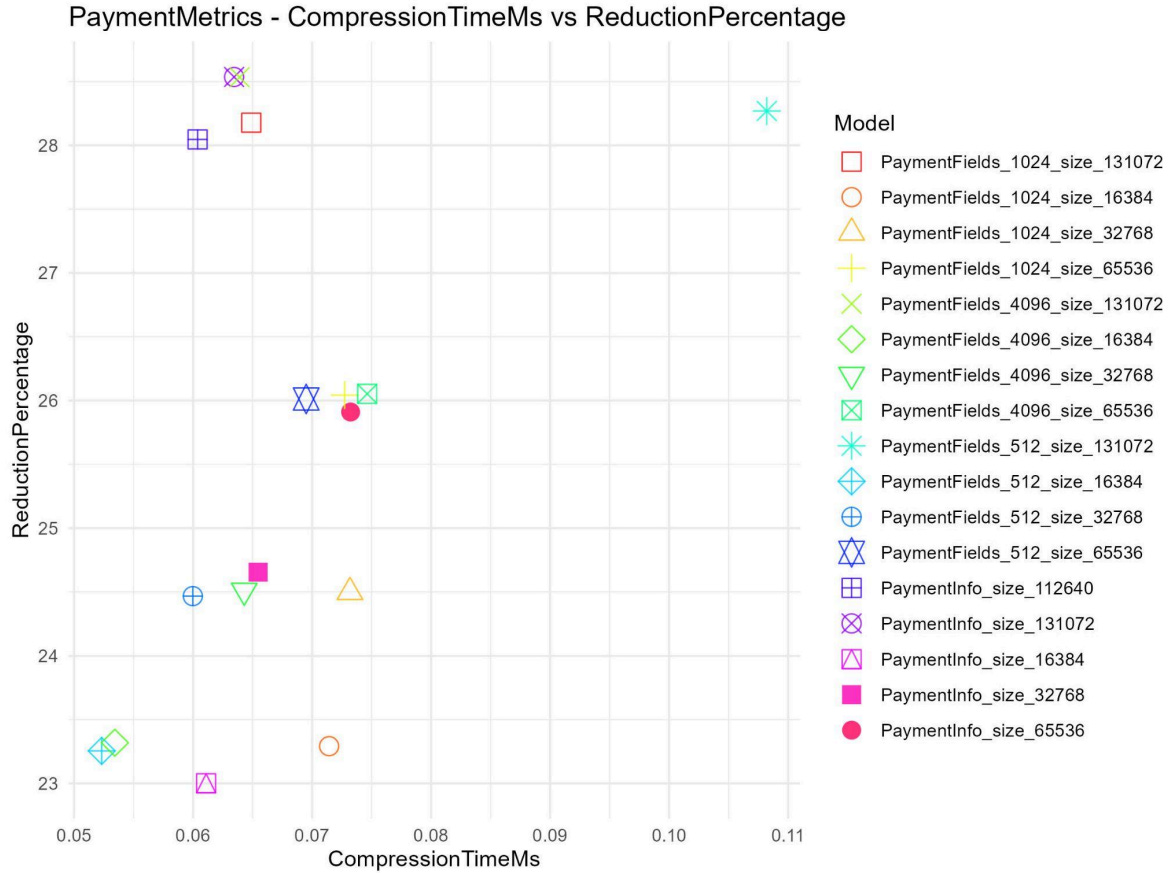
Our engineering team evaluated a dataset of 200,000 records (100,000 transactions and 100,000 payments) split evenly between training and testing. We tested dictionary variations using chunks of 512, 1024, and 4096, combined with dictionary sizes of 16KB, 32KB, 64KB, and 128KB.
Benchmarks showed clear gains:
Transaction data: Using a configuration of 4K chunks and a 128 KB dictionary size, we achieved an 81% reduction in size, shrinking the average payload from 5 KB to just 948 bytes. The performance overhead was negligible, with compression taking only 0.012 ms and decompression taking 0.006 ms.
Payment data: Using the same parameters, we achieved a 28% reduction (from an average of 6.8 KB to 4.9 KB). Compression times remained highly performant at 0.064 ms, and decompression at 0.011 ms.
The difference between transaction and payment compression ratios was expected. Transaction payloads follow a more controlled and repetitive structure, which makes them more suitable for dictionary-based compression. Payment payloads vary more depending on merchant behavior, payment methods, countries, providers, and integrations, reducing the amount of repeated patterns available for compression.
Scatter plots illustrating our compression benchmarking. The top-left quadrant represents our target zone: maximum payload reduction with minimal latency overhead. Notice how configurations using 128KB dictionaries appear among the best-performing results, reaching the upper boundary of compression for both Transaction and Payment payloads.
While compressing the payload solved the size per row, we still needed a robust lifecycle strategy for the data itself. We decided to create a new database and establish an automated tiering flow to distribute load based on data access frequency.
The new architecture lifecycle is structured as follows:
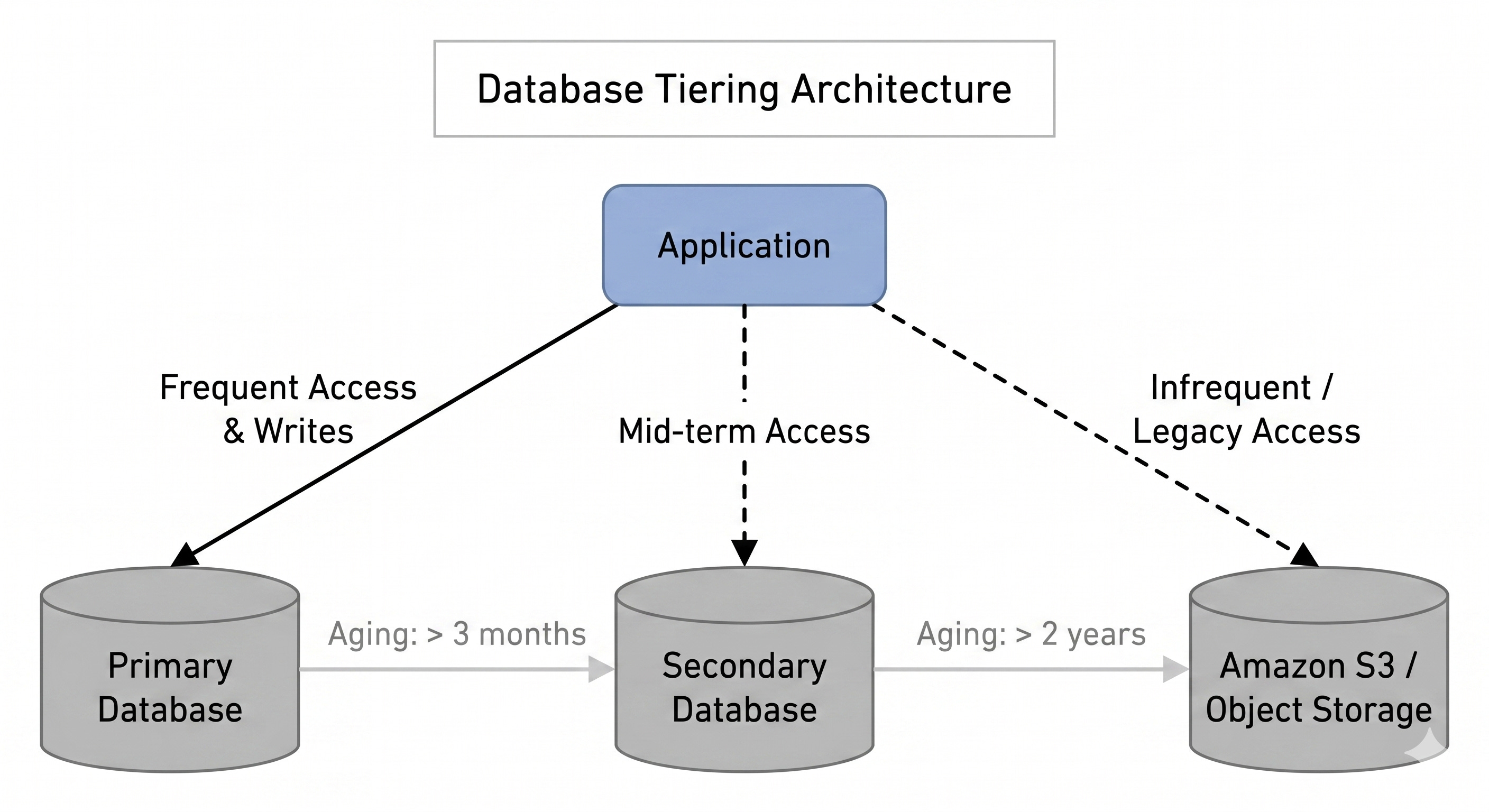
Primary Database: A highly performant database that holds only the most recent data (up to 3 months), keeping indexes lean and queries lightning-fast.
Secondary Database: A support database that stores mid-term data, containing records that are between 3 months and 2 years old.
Object Storage: Data older than 2 years is automatically migrated to Amazon S3.
To guarantee zero downtime and no impact on active merchants during the migration, we utilized feature flags to safely roll out the new database. Our application was configured to perform “dual writes” to both the old and new databases. The migration ran over several weeks and was monitored through internal validation tests and production metrics before the dual-write path was deprecated. For reading operations, we implemented a fallback mechanism: the system attempts to read from the new database first; if the record is not found, it falls back to the old database. Once data consistency was validated, we safely deprecated the dual-write logic.
By combining data compression with a sustainable tiering architecture, we achieved significant performance gains across our payment processing flow.
Slicing Storage Growth in Half: Before this initiative, our database grew at a rate of 800 GB per month. Following the modernization to JSON and compression, the new database now grows at just 400 GB per month, a 50% reduction in storage accumulation.
Reducing Write Throughput: The lighter payloads directly impacted our I/O operations. We achieved a 50% reduction in write throughput, dropping from 5 MB/s down to 2.6 MB/s.
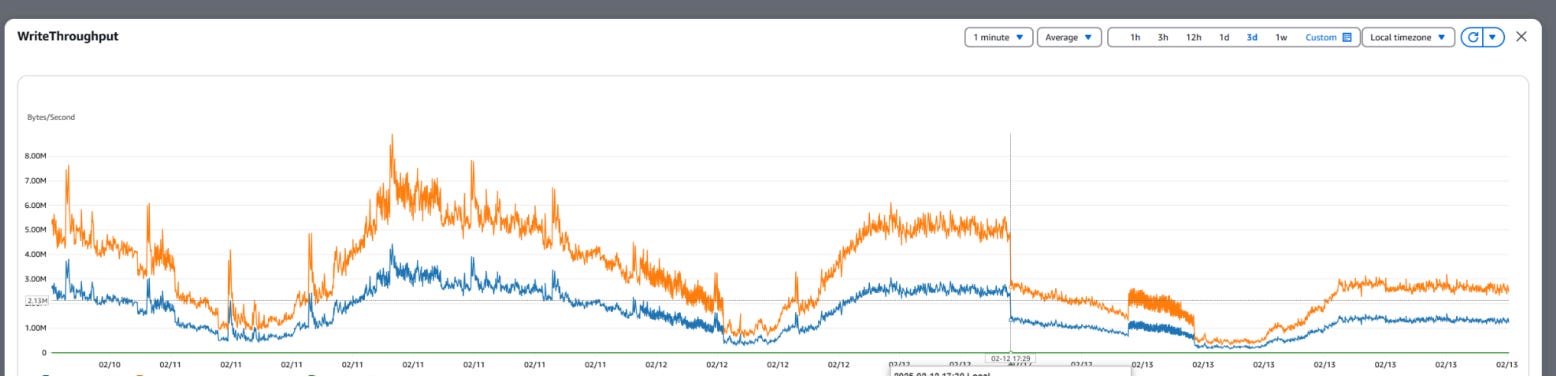
68% Improvement in Insert Latency: By comparing the legacy database with the new instance, we observed insert latency decrease from 2.88 ms to 0.92 ms in production metrics. This represents a ~3x improvement in write performance during the dual-write migration phase, as shown in the side-by-side comparison below, where the left chart represents the legacy database and the right chart represents the new instance.
Scaling a high-throughput system requires constantly rethinking how data is stored, compressed, and retrieved. By moving away from legacy XML formats, implementing efficient compression, and applying a rigorous data tiering strategy, we built a more resilient payment processing infrastructure. This initiative not only optimized our resource utilization but also translated directly into lower latency, ensuring the VTEX platform delivers consistent reliability. Ultimately, this creates a payment platform better prepared for peak events, larger transaction volumes, and continued business growth without adding unnecessary operational risk. For our engineering teams, it establishes a healthier foundation to scale the payment flow with controlled storage growth and reduced operational pressure.
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。