Making RAG Smarter with Token-Aware Chunking, HyDE, and Context-Aware Search
In Part 3, we improved chunking and optimized context. The system was faster and cleaner… but still not always correct.
What broke after Part 3?
By this point, the system looked solid:
- Smarter chunking
- Context compression
- FAISS + re-ranking
- Streaming responses
But when I started using it more realistically, a few problems showed up:
1. Token limits were still hurting quality
Even with better chunks, we were still not controlling how much context we send to the model.
2. Vague queries failed badly
Questions like:
- “Explain this”
- “What does it mean?”
…would often retrieve irrelevant chunks.
3. Follow-up questions felt disconnected
The system didn’t “remember” what we were talking about.
At this point, it stopped feeling like a “retrieval problem”
…and more like a context understanding problem.
So in Part 4, I focused on making RAG smarter.
What we’re building in this part
- Token-aware chunking (based on actual LLM limits)
- HyDE (Hypothetical Document Embeddings)
- Early version of context-aware retrieval
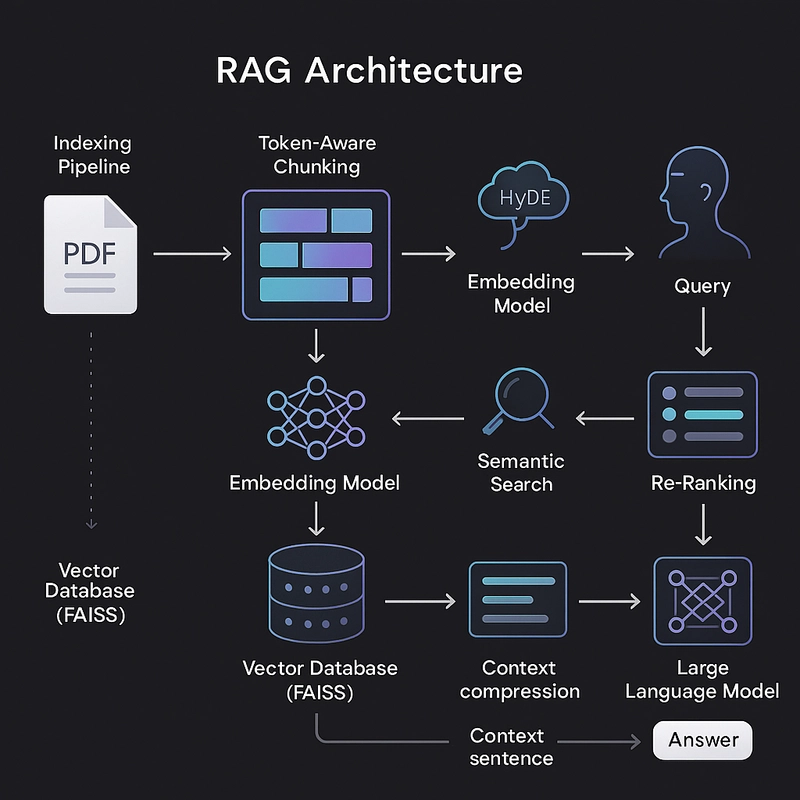
Updated Pipeline
Before jumping into code, here’s how the pipeline evolved:
Before (Part 3):
Query → Embedding → FAISS → Re-rank → Context → LLM
Now (Part 4):
Query → (HyDE) → Better Query → Embedding
→ FAISS → Re-rank → Token-aware Context
→ LLM (with constraints)
Problem 1: Token limits are real (and we were ignoring them)
Until now, chunking was based on:
- characters
- sentences
- separators
But LLMs don’t think in characters.
They think in tokens.
Why this matters
You might send:
- 2 chunks → fine
- 5 chunks → maybe fine
- 10 chunks → silently truncated or degraded
And the worst part?
You won’t even know it’s happening.
Solution: Token-aware chunking
Instead of guessing chunk sizes, we measure them using a tokenizer.
import tiktoken
tokenizer = tiktoken.get_encoding("cl100k_base")
def get_token_length(text):
return len(tokenizer.encode(text))
Now chunking becomes token-driven instead of size-driven.
Token-based chunking strategy
Key idea:
- Build chunks until a token limit
- If exceeded → split intelligently
- Maintain overlap using tokens, not characters
MAX_TOKENS = 250
OVERLAP_TOKENS = 50
Smarter chunk building
Instead of blindly splitting:
- Prefer paragraphs
- Then sentences
- Then fallback
def generate_chunks_recursive_tokens(text, page_num):
paragraphs = text.split("\n\n")
current_chunk = []
current_tokens = 0
for paragraph in paragraphs:
paragraph_tokens = get_token_length(paragraph)
if current_tokens + paragraph_tokens > MAX_TOKENS:
chunks.append({
"text": "\n\n".join(current_chunk),
"page": page_num
})
current_chunk, current_tokens = _get_overlap(current_chunk)
current_chunk.append(paragraph)
current_tokens += paragraph_tokens
Why this works better
- Matches actual LLM limits
- Avoids hidden truncation
- Improves context density
- Makes responses more reliable
Problem 2: RAG fails on vague queries
This was the bigger issue.
Even with good chunking, queries like:
“Explain this concept”
…don’t contain enough semantic signal.
So FAISS retrieves something… but often not the right thing.
Solution: HyDE (Hypothetical Document Embeddings)
This is one of the most interesting tricks in RAG.
Instead of embedding the raw query…
👉 We first generate a hypothetical answer
👉 Then embed that
Why this works
A vague query becomes a rich semantic representation.
Example:
User query:
Explain this
HyDE generates:
This concept refers to a method where...
Now embedding this gives:
- More keywords
- Better semantic alignment
- Stronger retrieval
Implementation
Step 1: Generate hypothetical answer
def generate_hypothetical_answer(query, chat_history):
recent_user = [m["content"] for m in chat_history[-4:] if m["role"] == "user"]
history_text = " | ".join(recent_user[-2:])
prompt = (
f"Write a 2-sentence technical summary answering: {query}\n"
f"Recent user context: {history_text}"
)
response = ollama.generate(
model=HYDE_MODEL,
prompt=prompt,
stream=False
)
return response['response']
Step 2: Augment the query
hypothetical_answer = generate_hypothetical_answer(query, chat_history)
search_query = f"{query} {hypothetical_answer}"
Step 3: Embed the enriched query
response = ollama.embed(model=EMBED_MODEL, input=search_query)
Impact
- Better retrieval for vague queries
- Improved relevance
- More stable responses
At the cost of:
- ~1–2 seconds extra latency
Worth it? In most cases — yes.
Early Step: Context-aware retrieval
Another issue we started addressing:
Follow-up questions were treated as completely new queries.
Example:
User: Explain attention mechanism
User: How does it work?
Second query loses context.
What we added
A simple but effective improvement:
- Detect vague follow-ups
- Inject previous page context
if not target_page and vague_followups.match(query.strip()):
last_pages = get_last_referenced_pages(chat_history)
if last_pages:
query = f"{query} page {last_pages[0]}"
Result
- Follow-ups become meaningful
- Retrieval stays anchored
- Conversation feels connected
Putting it all together
Now the system:
- Understands token limits
- Improves weak queries
- Handles basic conversation flow
From learning project → real system
This is where things started to change.
Earlier:
- It worked
- It demonstrated RAG
Now:
- It behaves more like a real assistant
- Handles imperfect queries
- Works under constraints
What’s next?
We’ve improved:
- Data representation (chunks)
- Query understanding (HyDE)
But one big gap still remains:
We still don’t know why RAG fails when it fails.
In Part 5, we’ll go deeper into:
- Debugging the RAG pipeline
- Visualizing FAISS vs re-ranking
- Understanding retrieval quality
- Making the system more transparent
Code
Full implementation available here:
👉 https://github.com/SharathKurup/chatPDF/blob/token_aware_rag/
Final thoughts
At a high level, RAG seems simple:
Retrieve → augment → generate
But in practice, most of the work is here:
- How you represent data
- How you interpret queries
- How you control context
This part was about tightening those pieces.
And it makes a noticeable difference.
If you’ve been building with RAG, I’d recommend trying:
- Token-aware chunking
- HyDE
They’re relatively small changes — but high impact.
Let me know what you think or what you’d improve.