TL;DR
@webappski/aeo-tracker is an open-source Answer Engine Optimization (AEO) tracker — a Node.js CLI that measures brand visibility on ChatGPT, Gemini, Claude, and Perplexity via official APIs. Free, MIT-licensed, ~$0.20 per weekly run, zero runtime dependencies. Open-source alternative to Profound, Otterly, Peec.ai, and HubSpot's AEO Grader — calls the real provider APIs (no web scraping), saves every raw response to disk for audit, and uses a two-model LLM cross-check on competitor extraction to filter hallucinated brand names.
AEO (also known as GEO — Generative Engine Optimization) is the discipline of measuring and improving how often AI answer engines name your brand; this tool is the measurement half. Below: why we built it, the real numbers it gave us, the actual extractor code, and the quickstart.
Why I didn't pay for Profound, Otterly, or Peec.ai
Every AEO tracker I tried gave me a different number for the same brand. HubSpot's free AEO Grader scored us 28 out of 100. One paid dashboard said 44. A third refused to index the brand at all. A fourth was gated behind a $400-per-month plan before it would run a single query. None of them would show me the actual ChatGPT response they scored against.
As an engineer, this was untenable. I needed an answer to two questions no vendor wanted to answer: (1) Are you actually calling ChatGPT, or are you scraping Bing and inferring? ChatGPT's API uses its own grounding pool; Bing's SERP uses another. A "ChatGPT visibility score" derived from web scraping is not a ChatGPT visibility score. (2) What counts as a mention? If my brand appears only in a cited URL but not in the answer text, do you count that?
Nobody had documented answers. Profound, Otterly, and Peec.ai are closed-source dashboards with proprietary scoring layers; HubSpot's grader sits on top of a web-scrape pipeline that anyone can replicate but nobody publishes. I stopped paying and built my own.
Three commands from install to HTML report
npm install -g @webappski/aeo-tracker
aeo-tracker init --auto
aeo-tracker run
aeo-tracker report --html
init --auto fetches your homepage, asks an LLM to suggest category-appropriate queries, validates them with a second model, and writes a config.
run calls each AI engine whose API key is set in your shell env. Model IDs are config-driven defaults you can override per-run — current defaults in lib/config.js are gpt-5-search-api, gemini-2.5-pro, claude-sonnet-4-6 and sonar-pro; pass any other provider-supported model via --model openai=… or by editing .aeo-tracker.json. report --html renders a Markdown report with inline SVG charts plus a fully interactive HTML dashboard.
A few design choices that map directly to the frustrations above:
- Direct API calls, nothing in between. No web scraping. No browser automation. No proxied sessions.
- Pre-flight query validation. A separate LLM pass checks each query for ambiguity, acronym overload, and category drift before any tokens hit the engines.
-
Raw responses saved to disk. Every query × engine combination writes a JSON file under
aeo-responses/YYYY-MM-DD/. Any number in the report is auditable back to the exact AI reply. -
Zero runtime dependencies.
package.jsonhas nodependenciesand nopeerDependencies—grepit yourself. The whole CLI, including the SVG renderer, is plain Node.js 18+. Auditable in an afternoon.
How does the two-model cross-check work?
The core design decision in the tracker is how it decides which competitor brands an AI answer mentioned. Single-model extractors hallucinate routinely — they confidently return brand names that never appeared in the source response. The fix is to ask two cheap LLMs in parallel to extract brand names from the same response, then merge their answers. Both agree → "verified" tier (solid badge in the report). Only one agrees → "unverified" tier (dashed badge). Neither → dropped before the merge.
Here's the actual prompt the extractor sends — it's the file lib/report/extract-competitors-llm.js, reproduced verbatim with comment headers stripped:
// Strict-JSON prompt. Identical for both models so responses are directly comparable.
export function buildExtractorPrompt({ text, brand, domain, category }) {
const categoryLine = category
? `\nUSER CATEGORY: ${category}\nOnly names that are DIRECT ALTERNATIVES`
+ ` to the user's offering in this category qualify as competitors.`
+ ` Platforms/sources/publications mentioned as data or distribution`
+ ` channels do NOT qualify.`
: '';
return `You extract COMPETITOR brand/product/agency names from an AI
answer-engine response.
The user's brand is "${brand}" (domain: ${domain}).${categoryLine}
A COMPETITOR is a real company, product, or service that a buyer could
choose INSTEAD OF the user's brand, in the same category.
EXCLUDE (not competitors, even if mentioned as useful):
- The user's own brand
- AI-engines themselves (ChatGPT, Gemini, Claude, Perplexity)
unless the user's category is "AI assistants"
- Data sources / review platforms / social networks (Reddit, G2,
Trustpilot, Quora, LinkedIn, Slack, Discord, YouTube, Wikipedia,
TechCrunch, Wired, Yelp, Capterra) unless the user's category
is "review platforms" or similar
- Tooling unrelated to the category (Upwork, Toptal, Shopify, Zoom)
- Metrics, KPIs, methodologies ("Citation Rate", "Share of Voice")
- Process steps ("Build a Prompt Library", "Establish a Baseline")
- Section headers ("Content Freshness", "Technical Optimization")
- Names mentioned only as contrast ("Unlike X, we ...")
EXAMPLES:
Category: "Answer Engine Optimization services"
"Top AEO agencies: NoGood, Minuttia, Optimist"
→ brands: ["NoGood", "Minuttia", "Optimist"]
"To get recommended by AI, get reviews on G2 and be mentioned on
Reddit and TechCrunch"
→ brands: [] (G2, Reddit, TechCrunch are data sources)
Category: "CRM software"
"Leading CRMs include Salesforce, HubSpot, Pipedrive"
→ brands: ["Salesforce", "HubSpot", "Pipedrive"]
RULES:
1. Return canonical form (original casing/punctuation from source).
2. Do NOT invent names — every returned name must appear verbatim
in the source text.
3. Deduplicate.
4. If nothing qualifies, return { "brands": [] } — being empty is
correct and useful.
Return STRICT JSON, no markdown, no prose:
{ "brands": ["Name1", "Name2", ...] }
SOURCE TEXT:
${text}`;
}
// Hallucination guard — second line of defence after the merge step.
// Catches names a model invents that don't actually appear in the response.
export function filterHallucinations(brands, sourceText) {
const lowerSource = (sourceText || '').toLowerCase();
return brands.filter(name => lowerSource.includes(name.toLowerCase()));
}
The merge step is small but load-bearing: case-insensitive match on first-seen canonical form, both-model intersection becomes "verified", set-symmetric-difference becomes "unverified". A model that invents HubSpot when the response never mentions it gets its invented entry silently filtered before merge — the verbatim-substring check catches it. Two models invent the same hallucination far less often than one does.
What does a real AEO tracker output look like?
This is the score card the tracker produced for our brand on 2026-04-23:
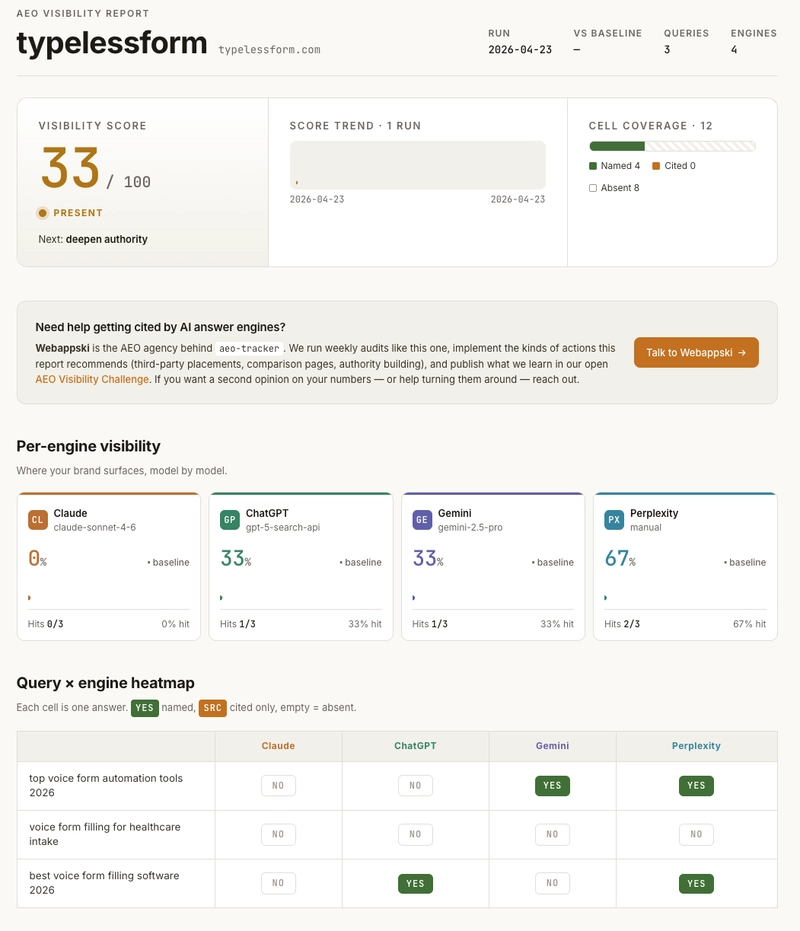
33 out of 100. PRESENT. Four out of twelve query-engine cells named the brand. Three queries × four engines = twelve cells. Pre-revenue baseline range is 0–15; six-month-old brands with SEO investment land 20–45; category leaders are 60–85. The tool charts movement over months, not grades for today.
Per-engine breakdown is where the real signal is: Perplexity 2/3 (strongest channel), ChatGPT 1/3 and Gemini 1/3 (one-each on different queries), Claude 0/3 (complete invisibility). Across our three test queries, Claude's grounding pool skewed toward dev.to, GitHub, and Product Hunt — domains where we don't yet have a footprint. Three queries, one category — treat it as a hypothesis to test on your own runs, not Anthropic policy.
The position matrix is even more interesting because it shows who AI named instead of you on each query:
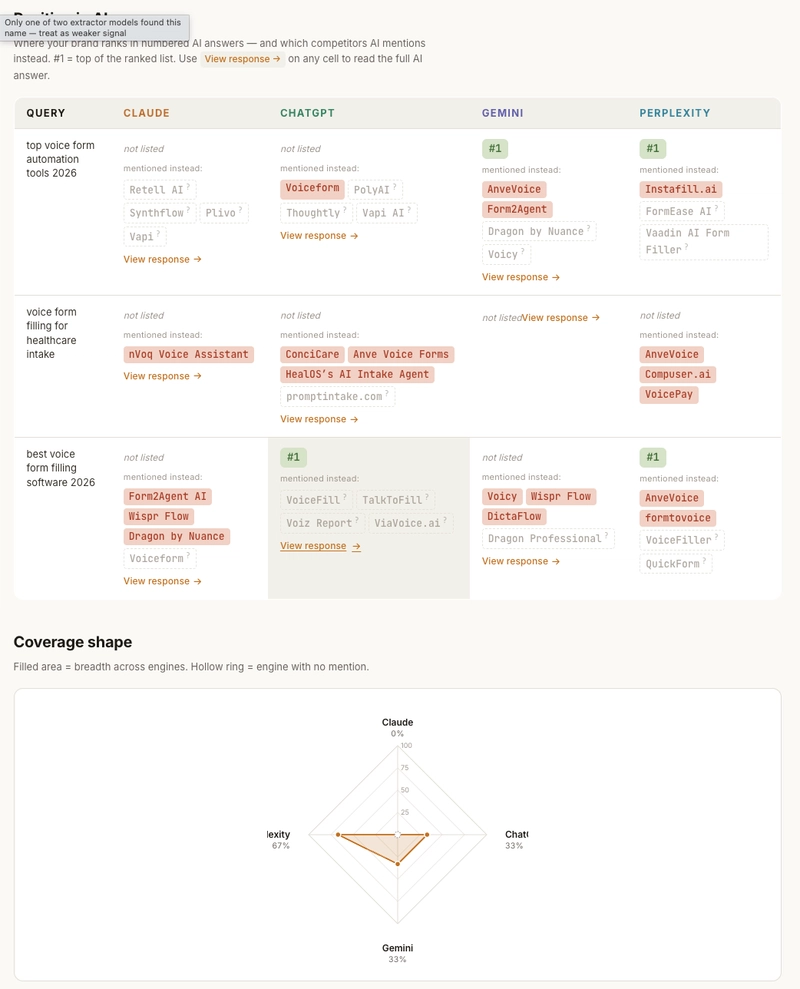
Aggregated across all cells: TypelessForm 4 mentions, AnveVoice 3, Wispr Flow 2, Form2Agent 1, Dragon by Nuance 1, Voiceform 1. The top-cited canonical source AI engines linked to was usevoicy.com — the same domain twice across two engines. One placement on usevoicy.com would propagate across every engine that grounds in it. That's an outreach target, not a content target.
How to run an AEO tracker on your own brand
Two API keys, minimum:
npm install -g @webappski/aeo-tracker
export OPENAI_API_KEY="sk-proj-..."
export GEMINI_API_KEY="AIzaSy..."
aeo-tracker init --yes --brand=YOURBRAND --domain=YOURDOMAIN.COM --auto
aeo-tracker run
aeo-tracker report --html
That covers the ChatGPT and Gemini columns at roughly $0.20 per weekly run. Add an Anthropic key for the Claude column (+~$0.30) or a Perplexity key for the Perplexity column (+~$0.05). Full four-engine coverage: ~$0.55 per run. Each provider's free tier is enough for the first month.
After the first run, the workflow is two commands once a week: aeo-tracker run && aeo-tracker report --html. The HTML report auto-opens in your browser.
Why is this open source instead of a SaaS?
Because the measurement should be commodity. The interpretation and execution shouldn't.
I'm not building this alone — the tracker is the open-source half of what my consulting agency does for clients. We run Webappski, and a client who can independently run aeo-tracker run and see their own raw numbers is a client who can check our work. We charge for the rest — the third-party placements, the comparison pages, the authority building, and the weekly read-out that turns numbers into action. The CLI handles measurement; everything that turns measurement into mention growth is the consulting half.
If that's interesting: https://webappski.com/en/aeo-services. If not: the tool is yours anyway. No telemetry, no analytics, no traffic to our servers. Your keys and your data stay on your machine.
FAQ
How does it compare to Profound?
Profound is a closed-source dashboard. @webappski/aeo-tracker is an open-source CLI you install locally with npm. Profound aggregates engine results behind a proprietary scoring layer; aeo-tracker exposes the raw AI responses and lets you compute the score yourself. Profound starts in the high-three-figure range monthly; aeo-tracker is free + ~$0.20 per run in API spend. Trade-off: Profound has historical dashboards and a sales rep; aeo-tracker has source code and a git log.
How much does it cost to run?
The tool is free under MIT. You pay only for the AI API calls you make with your own keys: ~$0.20 per run at the two-engine minimum (OpenAI + Gemini), ~$0.55 per run for four-engine coverage (adding Anthropic + Perplexity). Each provider's free tier is enough to start.
What does a 33/100 score mean?
It means 4 out of 12 query-engine cells named the brand in the answer text — three queries × four engines = twelve cells. The tracker counts how many returned a verified mention. Reference ranges: 0–15 for a pre-revenue brand at launch; 20–45 for a 6-month-old brand with on-page SEO; 60–85 for the category leaders. The score is a snapshot, not a verdict — week-over-week diff is where the tool earns its keep.
What is "TypelessForm" — the brand the screenshots reference?
TypelessForm is the brand we tested the tracker on. It's a one-shot voice form-filling widget — drop a <script> tag on any HTML form and visitors can fill every field of the form by speaking one sentence. 25+ languages, GDPR-compliant, free tier. The product itself lives at https://typelessform.com (the hotel-booking write-up is the fastest way to see what "one-shot" means). The tracker is a separate project from the widget — same maintainer, different repo.
Links
- npm: https://www.npmjs.com/package/@webappski/aeo-tracker
- GitHub repo: https://github.com/DVdmitry/aeo-tracker (star if useful — helps other developers find it)
- Full original article with all five tracker screenshots: https://typelessform.com/blog/free-open-source-aeo-tracker
- AEO consulting (the human layer): https://webappski.com/en/aeo-services
- Issues / PRs welcome: https://github.com/DVdmitry/aeo-tracker/issues
Try it and tell me what surprised you
Run it on your own brand and post your engine breakdown in the comments — the Claude vs Perplexity diff is the most surprising part. I want to see whether the 0/3 Claude blind spot is TypelessForm-specific or category-wide. Same pattern in your run? Fork the repo and let's debug it in an issue.