If you’re building a software product, your deployment process matters from day one. It’s not a “later” problem or just DevOps work in the background. It directly impacts how stable your product is, how fast you recover from issues, and how confident your team feels when shipping changes.
Most teams know this. But in practice, their release process looks very different.
Instead of a clear system, they end up with a patchwork of CI jobs — a deploy step here, a Slack alert there, a quick workaround that quietly becomes permanent.
It works. Until it doesn’t.
And when something breaks, the same question comes up: what just happened?
If that sounds familiar, this article is for you.
CI and CD are not the same thing
I’ve been building tech products for over ten years now, managing development teams through the full release cycle, from early-stage pipelines to production systems under real operational pressure. That experience made the gap between CI and CD for me impossible to ignore.
Usually, teams treat CI platforms as the default place to do everything: build, test, package, deploy, promote, and sometimes even roll back. At first it feels efficient. Your source code is already in GitHub or GitLab, your pipeline definitions live next to your code, your runners are already there. So why not push deployment and release orchestration into the same system too?
Because convenience at the beginning often becomes coupling at scale.
CI and CD are related, but they are not the same responsibility. CI is about validating change – build the code, run the tests, produce an artifact, confirm the commit is healthy. It answers one question: "Is this change valid?"
CD is about controlled change propagation – selecting a release candidate, deciding where it goes, defining an approval flow, promoting through environments, enforcing role-based access, capturing audit history, handling rollback safely. It answers a completely different question: "Who deployed which version, where, when, and what happened next?"
Those are different questions and they clearly deserve different systems.
The hidden cost of using CI for releases
Using GitHub Actions or GitLab pipelines for deployments is not wrong. It is often the fastest way to get started. But once deployment logic lives inside CI, several problems pile up.
1. Your release process becomes coupled to your source platform
If your CI platform is degraded, your release process is too. GitHub's incident history shows multiple events where Actions jobs failed or were delayed (sometimes in the same window that affected pull requests and API requests).
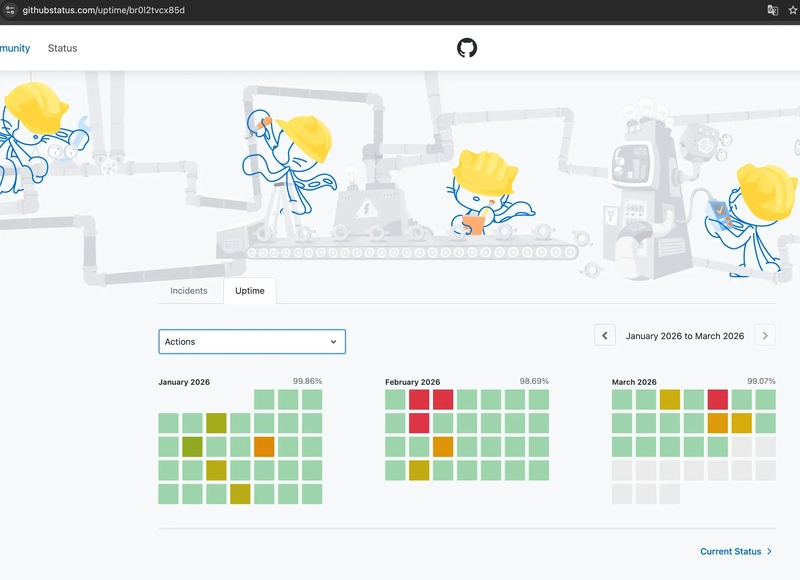
When your builds, approvals, and production releases all depend on the same platform, one outage freezes both development and delivery simultaneously. If you need to ship a hotfix during that window, "everything in one place" stops looking like an advantage, it becomes a single operational dependency.
2. CI pipelines are great at execution but awkward at release governance
Pipelines are good at running jobs. They are less natural as systems of record for release intent. Yes, you can build approvals into workflows. Yes, you can model environment promotion in YAML. Yes, you can encode rollback logic in scripts. But over time teams start asking questions that CI was never built to answer cleanly:
- Which exact version was approved for staging?
- Who approved the promotion to production, and when?
- Was QA sign-off captured before the release went out?
- What was the previous successful version?
- Can we roll back automatically if a deployment health check fails?
At that point deployment stops being "just another job" and becomes an operational workflow, one the pipeline was never designed to own.
3. Release logic becomes too tightly bound to repository events
Most CI-driven deployment patterns are built around repository triggers: push to branch, merge to main, create a tag. That works when your release process is simple. But at some point teams start wanting things pipelines were never designed for — build once, deploy many times; promote the same artifact from staging to production without rebuilding it; let operations trigger a deployment without touching the codebase; roll back without re-running anything. The pipeline starts fighting back. That friction is usually the first sign that deployment has outgrown CI.
What this costs at 2am
The real cost becomes visible during a production incident when every minute matters. These are the questions that come up in the first ten minutes:
- Who deployed the version currently running in production?
- Was QA sign-off captured before this version was promoted?
- What was the last known stable version before this deployment?
- Can we roll back in the next five minutes without re-running a build?
When CI-driven deployments cannot answer these (because the information is scattered across pipeline logs, Slack threads, and individual memory) the incident takes longer to take care of.
For teams building tech products, every minute of downtime has a direct user-facing impact. And there is a less visible cost too: the team gets slower without understanding why.
Rollback deserves particular attention here. In many CI-driven setups, rollback isn’t a defined operation. It’s a scramble:
- find the old tag
- re-run a pipeline
- hope nothing has drifted
- reconstruct whatever parameters were used last time
That’s improvisation under pressure. A release system should treat rollback as a first-class capability – tested, predictable, and fast.
Because at 2am, clarity matters more than anything else.
Independent systems, shared pipeline
The fix is not to replace your CI setup. GitHub Actions is powerful, GitLab CI is well-designed, and Jenkins is still deeply useful in many organizations. This is an architectural argument, not a tooling one.
Keep CI where it belongs – building, testing, packaging, publishing a versioned artifact. Let it answer "is this change ready?" and stop there. Then hand off to a separate, independent release layer that owns everything that happens next: which version ships, to which environment, with whose approval, under which rollback policy, with a full audit record that survives independently of your source platform.
That separation gives you something most teams are missing: a controlled release process instead of an automated shell script with side effects.
The best release process is not the one with the fewest steps, it is the one that still makes sense at 2am during a production incident.
How to actually separate CI from CD (and what to use)
If your infrastructure is already mature, there are several established paths.
Spinnaker is a powerful open-source CD platform with strong support for multi-cloud deployments and promotion workflows but it comes with significant operational overhead.
Argo CD is a solid choice for Kubernetes-native teams. It follows a GitOps model and has strong community support, but it is tightly coupled to Kubernetes environments.
Flux takes a similar GitOps approach with a lighter footprint, though it shares the same Kubernetes focus.
And tools like GitLab can handle both CI and deployment in a single platform, something that works well for many teams, especially early on.
But these tools solve different slices of the problem. They also assume a certain level of infrastructure maturity. For many teams, they introduce as much complexity as they remove.
But the key idea is super simple: separate the system that builds artifacts from the one that promotes and deploys them.
That became very obvious to me when I started testing deployment workflows outside of a single-machine setup – running services across isolated environments, with separate infrastructure components, and real failure conditions. The moment you leave the comfort of a local setup, hidden assumptions in pipeline-based deployments start to surface quickly.
That’s the reason the idea of Orbnetes came into my mind. It’s a self-hosted release orchestration layer designed to sit on top of your existing CI, without requiring Kubernetes or heavy operational overhead.
Instead of rebuilding per environment or encoding release logic in pipelines, the system focuses on:
**- promoting immutable artifacts
- defining explicit approval flows
- and keeping a release record independent of CI**
The goal isn’t to replace your CI, but to give deployments their own control plane – one that still makes sense when things go wrong.
How Orbnetes works in practice
Your CI pipeline stays exactly as it is. It builds, tests, and produces an artifact.
Orbnetes picks up from that point. It integrates with systems like GitHub and GitLab, as well as internal artifact storage or webhooks, and turns build outputs into versioned releases.
Each artifact is validated (for example via checksum) and stored as a release candidate. From that point on, deployments use the same immutable artifact across environments – no rebuilding, no hidden differences between staging and production.
That one decision alone removes an entire class of deployment inconsistencies.
Deployments are executed through** lightweight agents** running inside your infrastructure. They are cross-platform, isolated, and centrally managed, so environments stay independent, but the release process stays consistent.
Instead of embedding deployment logic in CI pipelines, it lives in blueprints – YAML definitions designed for release orchestration rather than build automation.
name: production-release
inputs:
target_env:
type: string
required: true
jobs:
backup:
tags: [linux]
steps:
- name: pre-deploy-backup
run: echo "Backup before deploy"
deploy:
needs: [backup]
tags: [linux]
steps:
- name: deploy-release
run: echo "Deploying artifact"
verify:
needs: [deploy]
tags: [linux]
steps:
- name: health-check
run: echo "Verifying deployment"
The syntax is intentionally familiar, but the responsibility is different: this is about releasing software, not building it.
Blueprints are versioned, reusable, and visible to the whole team rather than hidden inside a pipeline file that only a few people understand.
Before a release reaches a sensitive environment, it goes through explicit approval flows. Roles are separated: the people who build, approve, and deploy are not implicitly the same. Every action is recorded.
If something fails, rollback is not a guess. The system restores the last known good version using the already validated artifact. It is defined upfront, not improvised during an incident.
Every release becomes a tracked event:
- what version was deployed
- where it went
- who approved it
- what happened next
And importantly, this record exists independently of your CI platform. If GitHub has an outage, your release history (and your ability to operate) does not disappear with it.
Don't wait for an incident to fix this
CI tells you whether your software is ready. CD determines how it actually reaches production.
Those are different responsibilities and treating them as the same system is where teams start to lose control.
At a small scale, pipeline-driven deployments feel efficient. Everything is in one place, automation is easy, and shipping is fast. But as systems grow, that convenience turns into coupling. And coupling turns into fragility (usually revealed at the worst possible moment).
During an incident, the problem is never just the bug. It’s the lack of clarity:
- What exactly is running in production?
- Who approved it?
- What changed?
- How fast can we safely roll back?
The goal is not to add more steps or slow teams down. It’s to make releases predictable, observable, and controlled even under pressure.
That starts with a simple shift: build in CI, release through CD, keep them connected, but not fused.
If this resonates with how your team works, Orbnetes is free to try. The documentation covers full setup in under 30 minutes, and the blueprints library has ready-made examples for common deployment patterns across Linux, Docker, and multi-environment setups.
Remember that your deployment process is part of your product. Treat it that way:)