In dynamic production environments, unpredictable traffic loads and frequent code changes can make it difficult for organizations to consistently optimize their cloud infrastructure, resulting in application performance issues, latency, and wasted cloud spend. Teams that manage large-scale cloud infrastructure deployments are often forced to tune their workloads’ configurations using a complicated mesh of script jobs—or worse, manual remediation by on-call engineers prompted by alerts. Although serverless platforms such as AWS Lambda self-manage many operations behind the scenes, Lambda workloads come with a unique set of challenges and variables that typically aren’t optimized by using the default settings, including:
Rightsizing function memory to meet demand
Managing provisioned concurrency and warmups to prevent cold starts
Setting appropriate timeout limits
Mitigating out-of-memory errors
The advent of autonomous cloud management platforms powered by machine learning (ML) has enabled organizations to continuously optimize their modern applications based on container or serverless architectures. These tools help teams achieve the appropriate balance of performance and cost—and remediate issues—while reducing the manual effort required to maintain these complex systems. Sedai leverages data from monitoring services (including Datadog) to autonomously optimize the configuration of several key cloud infrastructure platforms, including AWS Lambda. By autonomously optimizing your configurations and remediating issues, Sedai helps your teams reduce cloud costs, improve application performance, and ensure high availability.
Sedai now integrates with Datadog out of the box and offers a subscription to their software in the Datadog Marketplace to automatically detect and analyze your Datadog-instrumented Lambda instances. Using the integration, you can configure Sedai to start optimizing your functions with minimal configuration overhead, and continuously monitor Sedai’s optimization actions from within Datadog. In this post, we’ll discuss how you can use Sedai with Datadog to:
Autonomously optimize Lambda functions for cost and performance
Autonomously detect and remediate issues with your Lambda deployments as they arise
By configuring the integration, you can set up Sedai to continually ingest metrics—including request latency, job duration, errors, traffic volume, and more—from your Datadog-instrumented AWS Lambda deployments. Using these metrics, Sedai’s ML tools learn about your deployments’ behavior, detecting seasonalities and other trends. Sedai will then start taking autonomous actions to optimize your workloads, including:
Setting memory levels (and the associated hidden CPU) to optimize for peak performance, lowest cost, or a balance between the two
Tuning the concurrency of your functions to prevent cold starts when traffic spikes
Let’s say your team is using a Lambda function to analyze customer data for product recommendations in an ecommerce application, and monitoring this function using Datadog’s Lambda integration. Naturally, the volume of data processing that this function handles will scale up and down significantly depending on the amount of customer traffic your app is getting. With the Datadog Sedai integration, your team can quickly provision Sedai to begin analyzing the function’s performance. After Sedai’s ML algorithms complete a learning period, Sedai will take action to optimize the function’s memory, timeout settings, concurrency, and other parameters. These optimization actions are then recorded as Datadog events for visibility to the teams monitoring the application.
In an out-of-the-box dashboard, the owners of your product recommendation service can view infrastructure metrics being sent to Sedai alongside Datadog events that signal Sedai’s automated optimization actions. In the example shown below, we can observe an increase in the average allocated memory size of our getquote Lambda function in the graph widget labeled “Average Lambda Memory Size.” This corresponds with Sedai’s events automatically scaling up the memory allocation of that function, which are collected in the event stream widget labeled “Sedai Serverless Auto Optimization Completed Events.”
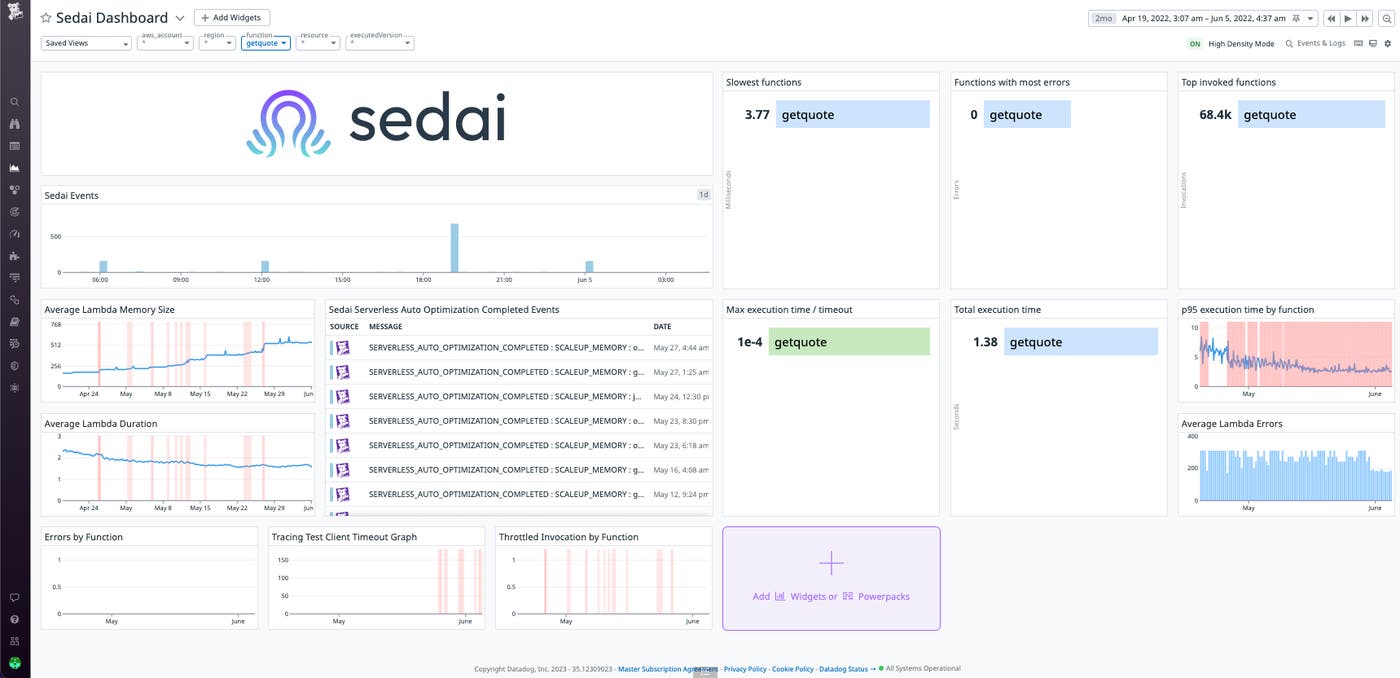
Sedai’s automated configuration management can continually tune the memory allocation, concurrency, and other configuration parameters for every function in your Lambda deployments. This includes purchasing optimization: Sedai’s autonomous concurrency management can purchase provisioned concurrency to lower the amount of pricier on-demand capacity required by your app to meet customer demand. This enables Sedai to fully own the configuration management process and continually optimize your infrastructure footprint, with no need for manual approval.
Autonomous systems free up SREs and DevOps staff to focus on the most important, new, and unique issues in their applications by taking care of a large volume of lower-level incidents that can be managed with machines. In addition to configuring your infrastructure in response to projected traffic patterns, Sedai also detects issues in serverless function metrics (including out-of-memory errors, timeouts, and throttling) and autonomously remediates them (allocating more memory, increasing the timeout threshold, and adding more reserved concurrency, respectively).
Datadog’s Sedai integration makes it easy for your teams to incorporate Sedai’s autonomous remediation capabilities into their existing incident response workflows. In addition to tracking Sedai’s remediation events in dashboards, you can also alert on them, or use Datadog’s Events Explorer to track them in a live feed alongside other triggered monitors, CI/CD updates, and configuration changes from across your infrastructure.

From both the Events view and a triggered monitor, your team members can see the incidents that were prevented or resolved by Sedai. When an issue arises that Sedai cannot address, you can quickly pivot to declare a new incident in Datadog Incident Management, and bring over key context such as error messages, relevant host and process names, and more. Datadog’s Incidents workflow makes it easy for an SRE or DevOps engineer to efficiently loop in teammates and begin tackling the problem. For more information, see our blog post on Datadog Incident Management.
With its sophisticated ML tools, Sedai can save your SREs and DevOps personnel significant time and effort by autonomously optimizing your infrastructure configurations and detecting and resolving performance regressions—all while keeping your cloud costs as low as possible. Within minutes, you can set up Datadog’s Sedai integration to start autonomously managing your cloud workloads while also monitoring Sedai’s autonomous actions alongside telemetry from across your infrastructure. For more information about the integration, see Sedai’s blog post. And for help installing the integration, see our documentation.
The ability to develop and promote third-party tools in the Datadog Marketplace that extend the capabilities of Datadog is one of the benefits of membership in the Datadog Partner Network. You can learn more about the Datadog Marketplace in our blog post, and you can contact us at marketplace@datadog.com if you’re interested in developing an integration or application.
If you’re brand new to Datadog, sign up for a 14-day free trial to get started.
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。