
https://github.com/forrestchang/andrej-karpathy-skills) — 原始仓库,当前 150,000+ stars
你有没有这样的经历——
用 Claude Code 帮你改一个函数,它顺手重命名了三个变量,删了一段「看起来没用」的注释,还把你写了两年的配置文件格式改了一遍。你没让它做这些,但它做了。你在 CLAUDE.md 里加了一条「不要修改无关代码」。下次又出了别的问题,又加一条。两个月后,你的 CLAUDE.md 有 180 行,Claude 照样我行我素。
这个场景我在三个不同的团队里见过。工程师们不是不努力,恰恰相反——他们太努力了,把 CLAUDE.md 当成了一个防御系统在建设,每出一个问题就打一个补丁,最后补丁比代码还多。
今年 1 月 26 日,Andrej Karpathy 在 X 上发了一条帖子,说这两年他的编程工作流发生了 20 年来最大的变化——从 80% 手写代码,变成了 80% 让 AI Agent 跑代码。他顺带列出了他观察到的 AI 写代码时的四种系统性失败模式。
第二天,开发者 Forrest Chang 把这四条观察翻译成了一个 CLAUDE.md 配置文件。到今天,这个仓库的 star 数已经超过 15 万。
这篇文章不是告诉你「赶紧去 copy 这个文件」——那太容易了,也没什么意义。我想聊的是:一个 70 行的文件为什么能跑赢几百行的「精心配置」?这背后有一个关于约束设计的反直觉原则,想清楚它,你写的每一个 CLAUDE.md 都会更有效。
很多人以为 Claude Code 出问题是随机的——有时候听话,有时候不听话,具体看运气。Karpathy 的观察否定了这个判断。他说这些失败是系统性的,每次出现,都来自同一批根因。
四种失败模式,逐一拆解。
第一种:静默假设(Silent Assumptions)
你说「帮我优化这个接口的性能」,Claude 默默选了一种解法,也许是加缓存,也许是改索引策略。它没告诉你它的假设,没问你当前的瓶颈在哪里,就开始写。等代码出来你才发现——它优化的方向完全不对,你们生产环境的瓶颈根本不在那里。
这不是 Claude 笨,这是它的训练目标之一就是「尽快给出答案」。在对话场景里这是优点,在写代码这件事上是隐患。
第二种:代码过度生长(Hypertrophy)
让它写一个简单的文件解析器,它给你来了一个带错误重试机制、支持多种编码格式、可以通过配置扩展的「企业级」版本。你没要这些,但它默认「加了更多等于更好」。
生产环境里最难维护的代码,往往不是逻辑复杂的那种,而是超出实际需求的那种——它的复杂度无法通过测试覆盖,无法通过代码审查发现,只有等到维护的时候才会爆。
第三种:附带修改(Collateral Changes)
这是最让工程师头疼的一种。让它修一个 Bug,它在修 Bug 的同时,顺手把旁边的函数重构了,把一个变量名「改得更规范了」,把一段死代码删了。每一个改动单独看都「有道理」,组合在一起就是一个很难 review 的 PR,和你以为的「只改了一行」相差甚远。
第四种:无验证完成(Unverified Completion)
「我已经修好了」。但它有没有跑测试?有没有检查边界条件?有没有验证和现有代码的兼容性?很多时候没有。它在完成一件你没有定义「完成标准」的任务。
这四个问题组合起来,就是工程师们普遍感受到的「AI 写的代码需要大量 review 才能用」——不是因为代码本身有语法错误,而是因为它做了你没要求的事、没做你真正需要验证的事。

图:四种失败模式与四条规则的对应关系
Forrest Chang 的 CLAUDE.md 文件里,对应这四种失败,写了四条规则。我把原文引用出来,逐条拆解它为什么这样写。
规则一:Think Before Coding(编码前先思考)
"State your assumptions explicitly. If uncertain, ask. Surface confusion and tradeoffs rather than proceeding silently."
针对静默假设。核心动作是把「隐藏的前提」显式化——在开始写代码之前,先说出你基于什么前提,如果有多种解读,先列出来,有不确定的地方先问。
这条规则改变的不是 Claude 的能力,而是它的行为模式——从「默认执行」改为「先对齐再执行」。对于一个做过大型项目的工程师来说,这和我们开需求评审会的逻辑是一样的:不是说你不懂技术,而是「对齐理解」这件事本身有价值。
规则二:Simplicity First(简单优先)
"Minimum code that solves the problem. Nothing speculative. No unrequested abstractions, no speculative features."
针对代码过度生长。关键词是「minimum」和「nothing speculative」——不写猜测性的功能,不搭用不到的抽象层。
这条规则反直觉的地方在于:它不是说写简单的代码,而是说「只写解决当前问题的代码」。用不到的抽象不是准备,是负债。我见过太多「以后可能用到」的 interface,最后一次都没被调用过,但维护新人要花半小时理解它为什么存在。
规则三:Surgical Changes(精确手术式修改)
"Touch only what you must. Clean up only your own mess. When editing code, restrict modifications to what's required and match existing style."
针对附带修改。「touch only what you must」这句话很有力度——你碰到的每一行代码都是修改范围,不是你要修改的就不要碰。「clean up only your own mess」更直接:不要去整理别人的代码,即使你觉得它不够优雅。
我用一个架构评审会的场景来类比:你来解决一个性能问题,不是来重构整个模块的。即使你顺手发现了三个可以优化的地方,正确做法也是记下来,另开 ticket,而不是一个 PR 塞进去。理由很简单——review 不了,出了问题不知道是哪行改的。
规则四:Goal-Driven Execution(目标驱动执行)
"Define success criteria. Loop until verified. Transform imperative instructions into declarative goals with verification steps."
针对无验证完成。不说「做这件事」,说「做这件事,完成的标准是 X,做完之后验证 Y」。给成功标准,给验证步骤,而不只是给任务描述。
Karpathy 在 X 上对这条的解释最直白:「LLMs 特别擅长循环直到满足条件为止。不要告诉它做什么,给它成功标准,看着它自己搞定。」
这四条规则,每一条都指向一个具体的失败模式,没有一条是泛泛的「写好代码」。这不是风格指南,这是故障修复手册。
社区对这个文件的反应出乎意料的好。我梳理了一下原因,有几个层面。
数据层面:在 30 个代码库上的社区测试显示,没有 CLAUDE.md 的错误率约为 41%,用了这四条规则之后降到 11%,合规率约 78%。这不是一个学术 benchmark,是 X 上一个叫 Mnilax 的开发者做的开放实验,被 Dickie Bush 等人转发后广泛流传。数字有争议,但方向没有争议:少量精准的规则,比零规则有效得多。
工程直觉层面:四条规则每一条都能让工程师产生「对,就是这个问题」的共鸣。这不是 AI 优化技巧,这是 Code Review 里每周都在念叨的东西——只不过以前是对人说的,现在要对 AI 说。
极简层面:70 行,人类可读,几秒钟扫一遍。「最好的 CLAUDE.md 随着时间推移会越来越短——你删掉那些事实上用不着的规则。」这句话本身就是一种设计哲学的体现。
这才是我最想聊的部分。
「规则越多越好」是一个直觉上正确、逻辑上错误的判断。表面上看,每次 Claude 出问题你加一条规则,下次不就不出这个问题了?实际上不是这么工作的。
上下文窗口的稀释效应
Claude 处理 CLAUDE.md 的方式,不是「逐条检查是否违规」,而是在生成响应时把规则文件作为上下文权重的一部分。当你的规则文件有 200 行,每一条规则分配到的注意力权重就低了一大半。
2025 年 Jaroslawicz 等人的研究给出了一个残酷结论:「指令数量翻倍,合规率减半。」 更直接的数据:即使是最好的模型,在 Agent 场景里,完美遵守所有指令的任务不超过 30%。你有 200 条规则,Claude 有效遵守其中 60 条,而且不是固定的那 60 条。
防御性写法的副作用
大多数工程师写 CLAUDE.md 的模式是这样的:发现 Claude 做了 X → 加一条「不要做 X」。这是响应式的、防御性的写法。问题在于,你不可能穷举所有的 X,而且「不要做 X」「不要做 Y」「不要做 Z」堆在一起,Claude 要在这个「禁令列表」里工作,认知负担很高,反而可能导致它在「有没有违反某条禁令」这件事上花太多注意力,而不是在「把这个任务做好」这件事上。
和 Karpathy 四条规则的本质区别
Karpathy 的四条规则不是禁令清单,是行为框架。它们定义的不是「不准做什么」,而是「决策时的优先次序和工作方式」。
「Think before coding」不是「不准瞎写」,是「先对齐再执行」。
「Simplicity first」不是「不准写复杂代码」,是「默认选最简解法」。
「Surgical changes」不是「不准动其他代码」,是「你的范围只有这里」。
「Goal-driven execution」不是「必须写测试」,是「定义验证标准,跑到标准满足为止」。
框架和禁令的区别,在于框架提供的是判断依据,禁令提供的是行为约束。判断依据让 Claude 在遇到新情况时知道怎么选,禁令只能管你已经见过的情况。
用架构的语言说:禁令是 blacklist,框架是 principle。principle 的复用性远高于 blacklist。
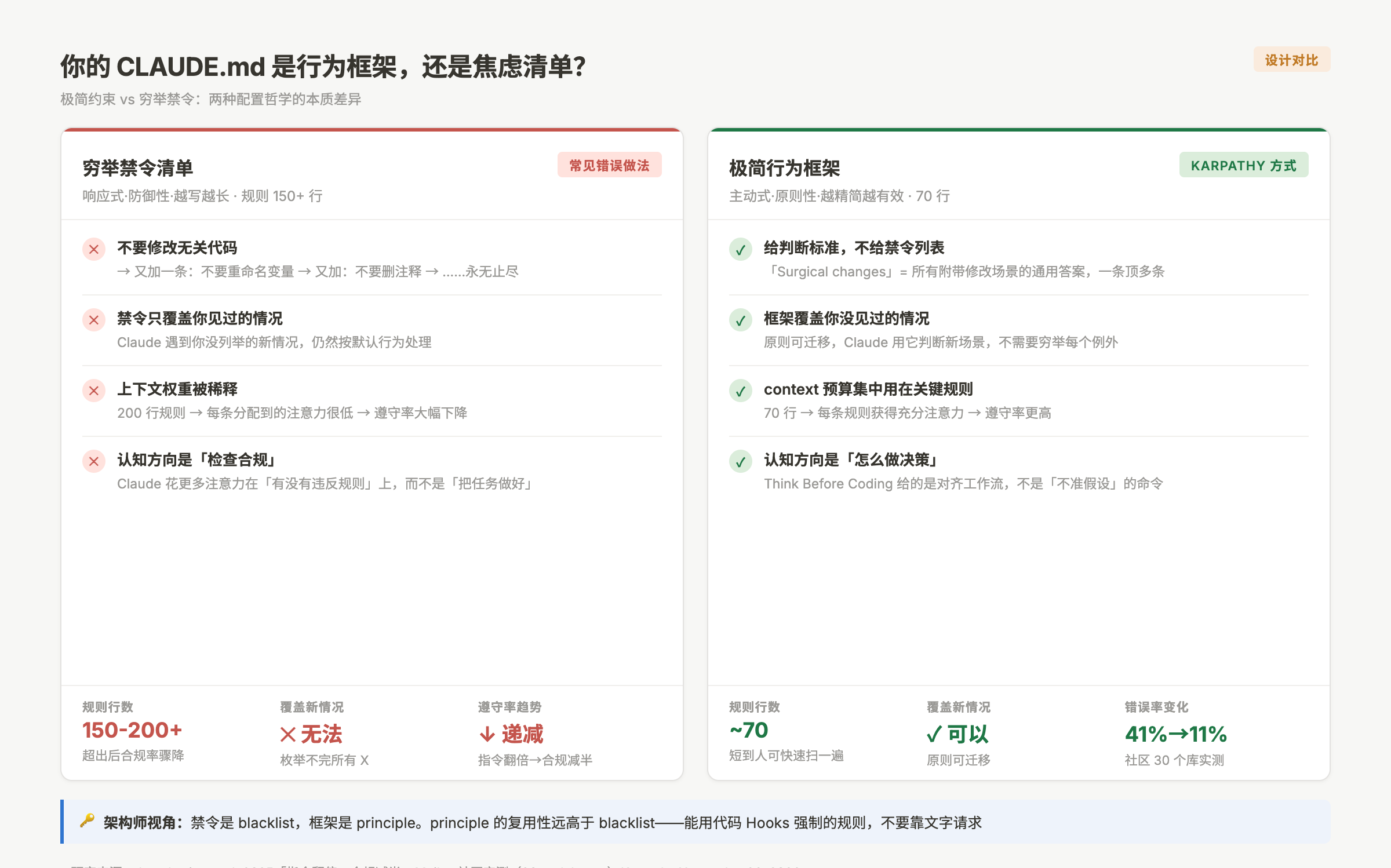
图:框架式约束与禁令清单的本质区别
如果你现在有一个 CLAUDE.md,用下面三个问题扫一遍:
问题一:规则超过 80 行了吗?
如果超过了,先压缩。把所有「不要做 X」「禁止 Y」的条目找出来,问自己:这条规则对应的是一个 Claude 的系统性行为问题,还是某一次的偶发事故?偶发事故的规则,没有保留价值。
问题二:你的规则在说「禁止什么」还是「怎么做决策」?
比较这两个写法:
写法 A:「不要修改和任务无关的代码。不要重命名变量。不要删除注释。不要格式化代码。不要重构函数签名。」
写法 B:「Surgical changes:只改任务要求的部分,不动其他任何东西,包括格式、注释和命名。」
写法 A 有五条规则,写法 B 有一条。在实际效果上,写法 B 覆盖的情况更多,因为它给的是判断标准,不是列举清单。
问题三:有没有可以被强制执行的规则,用了 Hooks?
有一类规则比 CLAUDE.md 更可靠:Hooks。Claude Code 的 Hooks 是在特定 Agent 行为发生前后触发的脚本,它不依赖 Claude 读到规则、理解规则、决定遵守规则这一串概率链——它是代码强制的。
「每次生成代码后必须跑 lint」——用 Hook。
「提交前必须跑测试」——用 Hook。
「修改配置文件前必须备份」——用 Hook。
能用代码强制的事情,不要靠文字请求。CLAUDE.md 的规则只能管它决定遵守的时候。
我用 Karpathy 的四条规则工作了两周,说一下真实体验。
最明显的变化是「啊这里有歧义」的频率提高了。以前我发一个模糊的任务,Claude 直接就跑了,跑完才发现方向不对。现在它会先说:我理解你的需求是 A,基于这个前提我打算这样做,如果你的实际需求是 B,我需要调整一下方向。这个「对齐确认」动作,节省的时间远比多发了一条消息要值。
变化二是 diff 干净了很多。同样是「修这个 Bug」,以前的 PR 经常出现 20+ 个文件变更,其中 15 个是「顺带」的修改。用了 Surgical Changes 这条规则之后,diff 基本就是你要求改的那几行。Code Review 轻松了,出了问题也好 rollback。
变化三是「任务完成」这件事变得更可信了。以前 Claude 说「好了」,我还是要手动跑一遍测试。现在它会说「我跑了 unit test,全过,也验证了 edge case X 和 Y」。这不是 100% 可靠,但比以前好多了。
需要老实说的是:这四条规则对于复杂的大型任务效果最明显,对于「帮我看一下这行代码有没有问题」这类小任务,它有时候会过度谨慎——先对齐再执行,结果你觉得它在「问废话」。规则要加,但不是所有场景都一样适用。
Q:这个 CLAUDE.md 只适合 Claude Code,用 Cursor 或者 Copilot 有用吗?
A:规则的内容适用于任何有类似 context 文件机制的工具。Cursor 的 .cursorrules、Windsurf 的 .windsurfrules 里用同样的逻辑都有效果。但 Claude Code 在「Goal-Driven Execution」这条规则上受益最明显,因为它的 Agent 模式本身就支持循环执行直到条件满足。
Q:Karpathy 的四条规则能直接 copy 用吗?需要修改吗?
A:可以直接用,原仓库(github.com/forrestchang/andrej-karpathy-skills)里的 CLAUDE.md 是经过社区打磨的版本,比 Karpathy 在 X 上的原始描述更具体。建议先整体 copy 跑两周,再根据你项目的具体情况微调。不建议一上来就大改——它的精简是有意为之的,你加的每一条规则都要想清楚「这条真的有必要吗,还是我只是想图个安心」。
Q:规则文件超过 80 行就一定不好吗?
A:不是绝对的。如果超过的部分是项目特定的技术约束(比如「这个项目用 Spring Boot 3.x,不要用 3.x 废弃的 API」),是有必要的。但如果超过的部分是大量「不要做 X」的禁令,特别是那些描述 Claude 通用行为倾向的规则,大概率在浪费 context 预算。一个有用的判断方法:把规则分成「通用行为框架」和「项目特定约束」两部分,通用行为框架保持简短,项目约束按需添加。
Q:这四条规则会不会让 Claude 的速度变慢?
A:Think Before Coding 会增加一轮确认往返,在简单任务上确实多一步。但 Goal-Driven Execution 反过来会减少「以为做完了但其实没做完」的返工。总的来说,复杂任务的净效率是正的,简单任务可以在 prompt 里加「直接执行,不需要确认前提」来跳过这步。

说到底,CLAUDE.md 是一个思维框架,不是一个行为合规文件。Karpathy 的四条规则胜在它告诉 Claude「怎么做决策」,而不是「不准做什么」。
后者你永远列举不完,前者四条就够了。你的 CLAUDE.md 如果写得越来越长,大概率说明你在用第二种思路在做第一种事。
写完这篇,码哥自己把团队的 CLAUDE.md 改了一遍,从 160 行压到 40 行,主要删的都是那些「不要做 X」的禁令。
跑了一周,差别比预期还明显。你身边有人也在配置 Claude Code 的 context 文件,这篇可以直接转给他,省他走一遍弯路。
下一篇打算聊 Claude Code Hooks 的具体用法——代码强制执行的那部分,感兴趣关注一下。
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。