编译器笔记:增量编译
如何让编译程序尽可能的快?并行化编译是最原始的做法——让每个单元都互相独立编译,并且尽可能多地同时编译。更进阶的做法就是——增量编译。
增量编译原理
增量编译的基础可以是并行化编译,也可以是串行编译。但是这只是过程,最重要的是能对每个文件进行单元化编译。
这是并行化编译的基础,从速度上考虑增量编译的单元应该是文件而不是文本内容,如果一个文件内容变化了一点但是需要大量的
differ 计算那我们不如直接从 0 开始编译。
如何实现一个简单的增量编译
我会用最简单的话来讲述实现增量编译的原理,甚至简单到不需要有太多编译相关的知识。
我们假定在 .caches 文件夹下有一个 compile.json
文件,用于记录上一次编译所产生的文件的信息:包含最小编译单元的 Digest(比如
MD5,SHA256),该单元输出的 Digest。
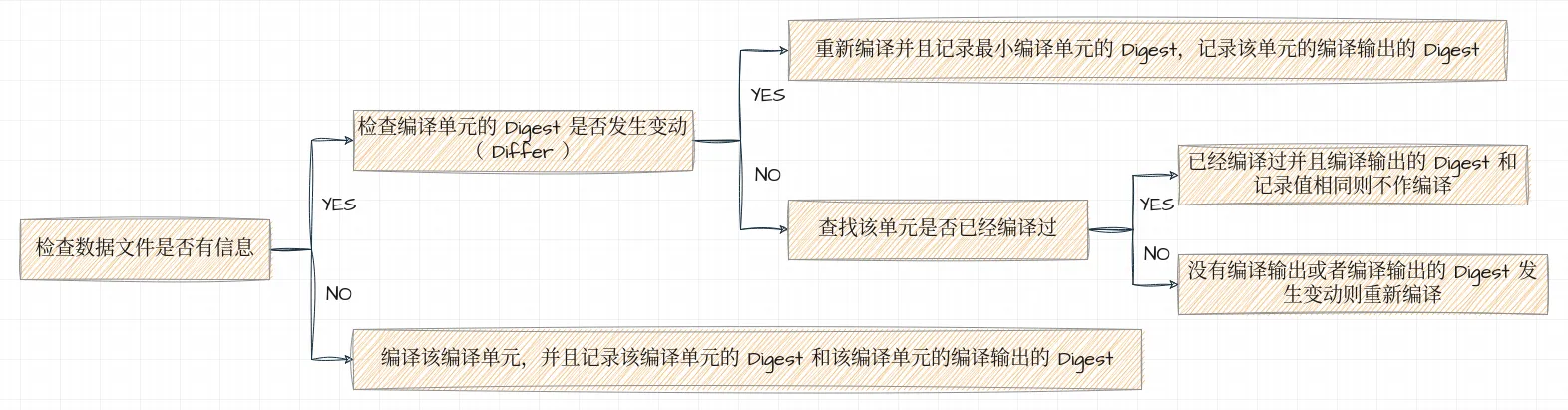
在编译文件时,先检查 compile.json 文件里是否有对应的信息:
- 如果有的话
- 检查编译单元的 Digest 是否发生变动( Differ )
- 已经变动:重新编译并且记录最小编译单元的 Digest,记录该单元的编译输出的 Digest
- 没有变动:查找该单元是否已经编译过
- 已经编译过并且编译输出的 Digest 和记录值相同则不作编译
- 没有编译输出或者编译输出的 Digest 发生变动则重新编译
- 检查编译单元的 Digest 是否发生变动( Differ )
- 如果没有的话
- 编译该编译单元,并且记录该编译单元的 Digest 和该编译单元的编译输出的 Digest
这样就是一个很简单的增量编译处理方式——输入没变就去找输出,输出变了就重新输出;输入变了那输出肯定和之前就不一样了。
这种处理方式有一个问题,那就是对于大项目来讲如果经历大重构会出现一大堆没办法被处理掉的之前的编译输出:因为这些编译输出已经是以前的文件的了,编译单元被重构后路径也发生了变化。
所以会有些文件不会被处理掉。
但我觉得问题不大,因为 cleanBuild
也是很必要的——而且各位的开发机也不缺这点储存。
用一个更直观的图来表达这个过程吧!