On the 25th of October Bear had its first major outage. Specifically, the reverse proxy which handles custom domains went down, causing custom domains to time out.
Unfortunately my monitoring tool failed to notify me, and it being a Saturday, I didn't notice the outage for longer than is reasonable. I apologise to everyone who was affected by it.
First, I want to dissect the root cause, exactly what went wrong, and then provide the steps I've taken to mitigate this in the future.
I wrote about The Great Scrape at the beginning of this year. The vast majority of web traffic is now bots, and it is becoming increasingly more hostile to have publicly available resources on the internet.
There are 3 major kinds of bots currently flooding the internet: AI scrapers, malicious scrapers, and unchecked automations/scrapers.
The first has been discussed at length. Data is worth something now that it is used as fodder to train LLMs, and there is a financial incentive to scrape, so scrape they will. They've depleted all human-created writing on the internet, and are becoming increasingly ravenous for new wells of content. I've seen this compared to the search for low-background-radiation steel, which is, itself, very interesting.
These scrapers, however, are the easiest to deal with since they tend to identify themselves as ChatGPT, Anthropic, XAI, et cetera. They also tend to specify whether they are from user-initiated searches (think all the sites that get scraped when you make a request with ChatGPT), or data mining (data used to train models). On Bear Blog I allow the first kinds, but block the second, since bloggers want discoverability, but usually don't want their writing used to train the next big model.
The next two kinds of scraper are more insidious. The malicious scrapers are bots that systematically scrape and re-scrape websites, sometimes every few minutes, looking for vulnerabilities such as misconfigured Wordpress instances, or .env and .aws files, among other things, accidentally left lying around.
It's more dangerous than ever to self-host, since simple mistakes in configurations will likely be found and exploited. In the last 24 hours I've blocked close to 2 million malicious requests across several hundred blogs.
What's wild is that these scrapers rotate through thousands of IP addresses during their scrapes, which leads me to suspect that the requests are being tunnelled through apps on mobile devices, since the ASNs tend to be cellular networks. I'm still speculating here, but I think app developers have found another way to monetise their apps by offering them for free, and selling tunnel access to scrapers.
Now, on to the unchecked automations. Vibe coding has made web-scraping easier than ever. Any script-kiddie can easily build a functional scraper in a single prompt and have it run all day from their home computer, and if the dramatic rise in scraping is anything to go by, many do. Tens of thousands of new scrapers have cropped up over the past few months, accidentally DDoSing website after website in their wake. The average consumer-grade computer is significantly more powerful than a VPS, so these machines can easily cause a lot of damage without noticing.
I've managed to keep all these scrapers at bay using a combination of web application firewall (WAF) rules and rate limiting provided by Cloudflare, as well as some custom code which finds and quarantines bad bots based on their activity.
I've played around with serving Zip Bombs, which was quite satisfying, but I stopped for fear of accidentally bombing a legitimate user. Another thing I've played around with is Proof of Work validation, making it expensive for bots to scrape, as well as serving endless junk data to keep the bots busy. Both of these are interesting, but ultimately are just as effective as simply blocking those requests, without the increased complexity.
With that context, here's exactly went wrong on Saturday.
Previously, the bottleneck for page requests was the web-server itself, since it does the heavy lifting. It automatically scales horizontally by up to a factor of 10, if necessary, but bot requests can scale by significantly more than that, so having strong bot detection and mitigation, as well as serving highly-requested endpoints via a CDN is necessary. This is a solved problem, as outlined in my Great Scrape post, but worth restating.
On Saturday morning a few hundred blogs were DDoSed, with tens of thousands of pages requested per minute (from the logs it's hard to say whether they were malicious, or just very aggressive scrapers). The above-mentioned mitigations worked as expected, however the reverse-proxy—which sits up-stream of most of these mitigations—became saturated with requests and decided it needed to take a little nap.
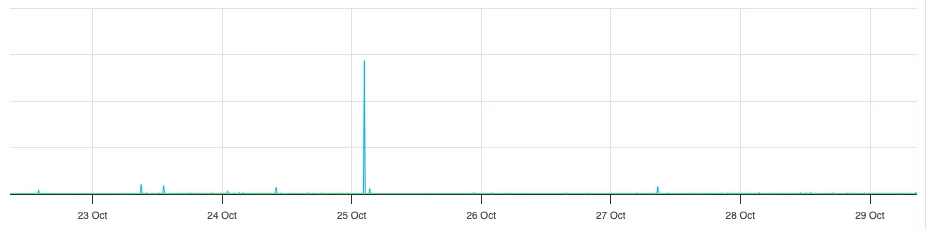
The big blue spike is what toppled the server. It's so big it makes the rest of the graph look flat.
This server had been running with zero downtime for 5 years up until this point.
Unfortunately my uptime monitor failed to alert me via the push notifications I'd set up, even though it's the only app I have that not only has notifications enabled (see my post on notifications), but even has critical alerts enabled, so it'll wake me up in the middle of the night if necessary. I still have no idea why this alert didn't come through, and I have ruled out misconfiguration through various tests.
This brings me to how I will prevent this from happening in the future.
This should be enough to keep everything healthy. If you have any suggestions, or need help with your own bot issues, send me an email.
The public internet is mostly bots, many of whom are bad netizens. It's the most hostile it's ever been, and it is because of this that I feel it's more important than ever to take good care of the spaces that make the internet worth visiting.
The arms race continues...
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。