Inside the Advisory Database and what happens when vulnerability volume breaks records
Madison Ficorilli·2026-06-30·via The latest on supply chain security - The GitHub Blog
In May 2026, the GitHub Advisory Database published 1,560 reviewed advisories—more than five times our typical monthly output and the highest in its history.
And it still wasn’t enough to keep up.
Over the past few months, the vulnerability ecosystem has shifted in a fundamental way. Input across private vulnerability reports, repository advisories, and CVE requests has increased simultaneously, pushing the entire system to a new operating scale.
This blog builds on an ongoing GitHub community discussion tracking the evolving nature of vulnerability reporting, as well as PVR and Advisory Database roadmap developments. A recurring theme in that thread is the downstream impact of platform changes on advisory curation and data quality. This aligns with GitHub’s broader shift toward emphasizing quality and shared responsibility in vulnerability reporting, which in turn directly shapes how advisory data must be curated and maintained.
TL;DR
Review times for new advisories are longer because vulnerability volume and complexity have increased significantly. Advisory quality has not changed: reviewed advisories are still human-validated, and existing alerts continue to function normally. If you want to help, focus on three things: submit complete vulnerability data, coordinate closely with maintainers and researchers, and request CVEs only when there is a clear intention to publish.
Record output and unprecedented input
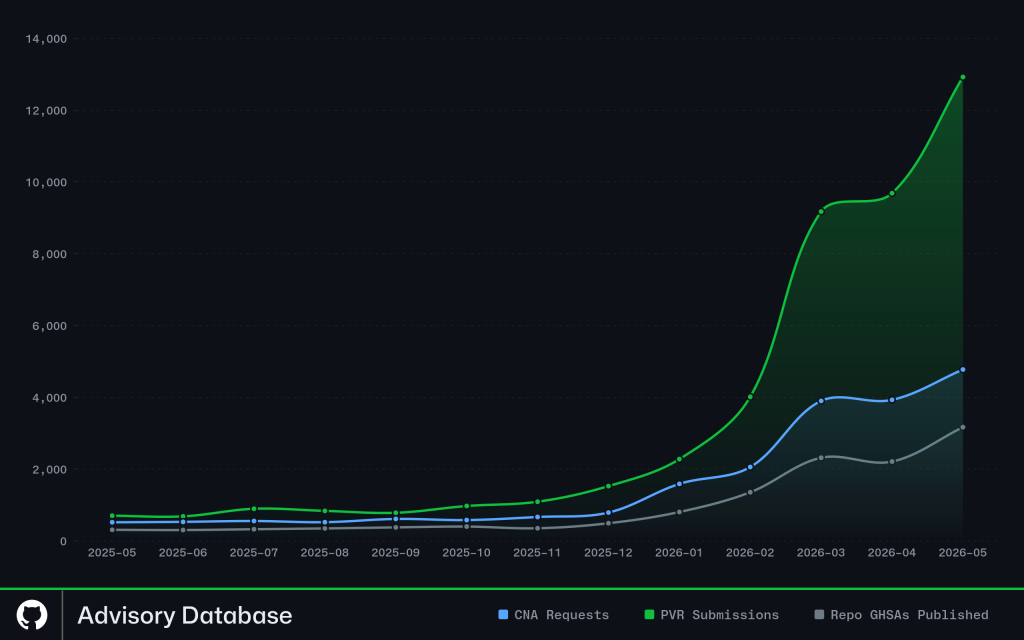
May was not a one-time spike. From March through May, we sustained more than 6,000 advisory decisions per month. This included updating existing advisories, publishing new advisories, and reviewing inbound advisories, and exceeded any prior three-month peak.
At the same time, inflow accelerated across every source:
Private vulnerability reports across the platform increased from ~550/week in January to more than 3,000/week for most of May.
Repository advisories scaled from ~650/week to more than 5,000/week.
GitHub CNA CVE requests reached almost 4,000 in May alone, nearly 10x year –over year.
The CVE program has already published 30,000+ CVEs in 2026.
More than 1.7 million total repositories have enabled private vulnerability reporting.
This is not a localized surge. It reflects structural change across the vulnerability disclosure ecosystem.
The impact
Since mid-April, due to this surge, we have not consistently met our internal goals for publication. Processing times extended first to about a week, then to multiple weeks for a meaningful share. Longer publication times can increase exposure windows. We take that seriously, and timeliness is a core part of the value this database provides.
What’s still working
Our data pipelines and publishing infrastructure have continued to operate through this period. Imports are running, data integrity is intact, and published advisories are accurate. Advisories that reach reviewed status today meet the same quality standard as before.
CVE assignment quality has remained strong. Our assignment rate has held between 91–94% through the entire surge, consistent with or better than historical norms and showing that there hasn’t been a clear degradation in the requests we receive.
The issue is throughput. The system that validates, enriches, and publishes advisory data is functioning; it is now operating beyond the volume and complexity it was designed to handle.
The work isn’t uniform
Not every security advisory requires the same level of effort. Some arrive well formatted: the advisory details clearly name the affected package and its relevant ecosystem, the version range is documented, and the fix is tagged. A curator can validate and publish these in under a few minutes.
But a growing share of incoming advisories require more investigation:
Package disambiguation. The advisory details say “foo”, but is that foo on npm, python-foo on PyPI, or the unrelated foo on Maven? When upstream data doesn’t specify an ecosystem, our curators figure it out.
Version range reconstruction. Many security advisories arrive with no affected version range, or with ranges that don’t match actual release history. Curators trace commits, changelogs, and tags to determine what’s actually affected.
Multi-ecosystem advisories. Some projects ship packages to multiple registries, like a library with both a .NET implementation (NuGet) and a JavaScript implementation (npm) of the same functionality, where a vulnerability in the shared logic affects both. This requires independent verification across multiple data sources.
Conflicting upstream data. When the CVE record, the maintainer’s advisory, and the commit history disagree about what’s affected, someone has to determine the truth.
Historically more straightforward advisories dominated, and the harder ones could be absorbed. When volume surges, the queue fills with both, and the complex ones take disproportionately longer, creating a compounding effect. The mix now matters much more. This isn’t just more work; it’s significantly more complex.
What “reviewed” actually means
A reviewed advisory is not simply a republished record; it’s the result of verification.
Curators:
Map vulnerabilities to the correct ecosystem package
Validate affected and fixed versions against release history
Confirm upstream accuracy
Check for duplication and consistency
Validate classification and scoring
This is what allows downstream tools to rely on the data without additional validation.
Publishing faster by skipping verification would increase false positives at scale, which can create more risk than delay.
A broader ecosystem shift
This trend extends beyond GitHub.
The volume of reported and published vulnerabilities continues to grow rapidly, and organizations across the ecosystem are adapting to that change.
The system is working as designed. More vulnerabilities are being reported, disclosed, and tracked than ever before. That creates pressure downstream, including during advisory curation.
What we’re doing now
Improving community contribution quality and throughput. Community contributions are an important part of how we improve the Advisory Database, and each is reviewed against the same validation standard as any other advisory. We’ve strengthened triage and prioritization, so high-quality submissions are identified earlier, reviewed more consistently, and moved through the queue faster. This helps us respond to current volume while reinforcing our primary goal of maintaining a high-quality, trusted dataset.
Scaling the systems behind curation. We’ve increased aspects of the capacity of our backend curation systems to handle higher sustained throughput and we’re continuing to modernize the data infrastructure that supports analytics and queue management.
Building AI-assisted research tools. We’ve developed and deployed tooling that gives our curators AI-powered assistance during the research phase of advisory review. Curators still make every decision, but routine research can be completed faster for higher quality advisories.
Expanding automation where it helps the most. We’ve improved automation for extracting more data from upstream CVE information and for handling how community contributions interact with already-reviewed advisories. That work reduces time per decision without lowering the quality bar.
Investing in documentation and training. We’ve significantly expanded our operational documentation. This enables us to bring new team members up to speed faster and improves consistency across the team.
What we’re building next
To support this new scale, we are investing in:
Reducing time-per-advisory for the most common cases. A significant portion of incoming advisories require research that follows predictable patterns, such as identifying the correct package, confirming the version range, and checking for a fix. We’re investing in tooling that accelerates these patterns, so curators can spend their time on genuinely ambiguous cases that require human judgment.
Making risk-based review prioritization smarter. We’re exploring additional risk signals for prioritization, such as package usage, evidence of active exploitation, and ecosystem impact to ensure the advisories that matter most reach users first.
Improving the feedback loop with upstream data sources. A significant share of curation time is spent correcting incomplete or inaccurate upstream data. We’re investing in tighter integration with the sources we ingest from, especially through increased repository GitHub Security Advisory and Private Vulnerability Reporting data validation, so that data quality issues get resolved closer to the origin rather than in our review queue.
Continuing to be transparent. We’ll share updates on our progress as we make it. If things improve, we’ll tell you. If we hit new challenges, we’ll share that too.
What this means for you
Dependabot users: Existing alerts are unaffected. New advisories may take longer to trigger, with critical issues prioritized.
API and feed consumers: Reviewed data remains accurate; unreviewed advisories are visible but not yet validated.
Maintainers: Repository advisories continue to flow into the global database; prioritization is based on several factors, including project impact and severity.
How you can help
Include complete data in vulnerability reports. Providing affected version ranges, root cause, and clear reproduction steps makes a direct difference in how quickly and accurately advisories can be reviewed. When this data is complete, curation can take minutes. When it isn’t, curators must reconstruct missing details from source code, release history, and conflicting upstream signals. At this scale, those gaps compound quickly. High-quality upstream data is one of the most effective ways to improve both speed and accuracy across the ecosystem.
Use the package name as it appears in the registry. Advisory package names must match the registry, not the repository or project name. Downstream systems rely on registry identifiers to match advisories to affected dependencies. If the name is incorrect or missing, alerts cannot be reliably generated, and affected users may never be notified. Using the registry name ensures the advisory can be correctly linked, indexed, and distributed.
List all affected packages. Some vulnerabilities impact multiple packages within a project. Each affected package should be listed separately with its own ecosystem, package name, and version range. Advisories are consumed at the package level, so missing a package means missing the users who depend on it. Including all known affected packages improves coverage and ensures alerts reach the full set of impacted users.
Provide a complete CVSS vector string. The GitHub Advisory Database supports CVSS 3.1 and 4.0. A severity label such as “High” is a quick summary, but a complete CVSS vector string includes a richer set of attributes, such as attack complexity, required privileges, and user interaction, which describe the vulnerability in greater detail. This structured information allows severity to be validated, interpreted consistently, and used by downstream tools for prioritization and automation. Without it, scoring is less precise and harder to compare across advisories. If you include a score, use the official calculators and include the full vector.
Include relevant CWE classification. A CWE identifies the underlying weakness behind a vulnerability, such as cross-site scripting, SQL injection, or deserialization of untrusted data. Unlike a narrative description, a CWE gives downstream tools and security teams a standardized way to understand what kind of issue they are dealing with. That matters because CWE data can be used to categorize, filter, prioritize, and compare vulnerabilities across large datasets. It helps organizations group related issues, apply policy or reporting rules, and understand patterns in the vulnerabilities affecting their software. The more specific the CWE, the more useful the advisory becomes for downstream consumers.
Be intentional when requesting CVEs. Requesting a CVE ID signals that a vulnerability will be disclosed and tracked publicly. When requests are made without plans to publish, it can divert time and attention from advisories that are actively moving toward release. Aligning CVE requests with clear publication intent helps ensure that effort is focused on where it has the most immediate impact and keeps the system responsive for everyone.
Coordinate closely with maintainers and other researchers. High-quality advisory data depends on shared context. Aligning affected packages, version ranges, and fixes helps reduce ambiguity and conflicting information across sources. At this scale, small gaps in coordination can become large inconsistencies downstream.
Improve advisory quality by contributing pull requests to the Advisory Database. Every correction to version ranges, package mappings, or fixes improves the accuracy that developers rely on.
Recognize the scale of this ecosystem shift and take part in it. The increase in vulnerability reporting reflects real progress. More issues are being found, fixed, and disclosed than ever before. Maintaining quality at this scale depends on researchers, maintainers, and data consumers and producers working together toward the same goal.
The bigger picture
Two years ago, the database published ~270 advisories per month.
In May 2026, it published over 1,500 while processing thousands of additional decisions across the system.
This reflects a broader shift:
More repositories are enabling responsible disclosure.
More researchers are reporting vulnerabilities.
More maintainers are publishing fixes and advisories.
The vulnerability ecosystem is scaling toward greater transparency.
That growth creates pressure on systems like ours. But it also represents meaningful progress.
Every advisory improves visibility. Every alert reduces risk.
We are scaling to meet that reality, and we will continue to share progress as we do.
Madison Ficorilli is a vulnerability transparency advocate and staff security manager at GitHub, leading the advisory database curation team. She is passionate about vulnerability reporting, response, and disclosure, and co-chairs the relevant Open Source Security Foundation (OpenSSF) working group and serves on the CVE Program Board. Her views are enriched by her prior experience as a product incident response analyst at GitHub and as a vulnerability coordinator at the CERT Coordination Center at the Software Engineering Institute at Carnegie Mellon University.