前言
论文进行到了深度学习的相关部分,尤其是当下火热的 CV(计算机视觉)的部分,写到如此我的论文部分也就是开始的地方了,这部分并不会涉及 Pytorch 框架的安装以及基础的 Python 问题,关于这个问题可以参考 【sklearn】机器学习环境搭建,Python 的部分可以参考 Python 。
深度学习框架
深度学习框架可以理解为一种工具,就像是现实中的锤子一样,它可以帮助我们更快速方便的捶打一些东西,当然你也可以选择使用别的什么东西来捶打,而这个使用的工具就是不同的深度学习框架,你甚至可以不使用深度学习的框架,完全自己弄的话也是可以的,只不过这个效率上来说会慢很多。
深度学习框架帮助我们封装了很多方法,屏蔽了很多我们不需要关注的细节,例如,求偏导,反向传播等。也许你看到这里并不是很明白这些词是什么意思,并不要紧,慢慢来做下去就会明白了。
全世界最为流行的深度学习框架有PaddlePaddle、Tensorflow、Caffe、Theano、MXNet、Torch和PyTorch。
斜体内容来源:百度百科
在现在来说,主流的只有两大框架:Tensorflow 和 PyTorch 。在工业界 Tensorflow 使用会比较多,而 PyTorch 使用在学术界的相对会多一些。如果你是研究生的生活中,可以先学习 PyTorch 然后再学习 Tensorflow,两个框架各有优势和缺点,
TensorFlow 的优势:
- 丰富的生态系统:其全面的库和工具将 TensorFlow 定位为机器学习任务的整体解决方案。
- 多功能性:它的兼容性扩展到各种语言,包括 C++、JavaScript 和 Python。
- TensorBoard:一个直观的工具,提供可视化,简化了神经网络的检查和调试。
PyTorch 的优势:
- 以用户为中心:其以 Python 为中心的特性确保了与Python 代码的无缝集成,使其对数据科学家极具吸引力。
- 动态计算图:PyTorch 对动态计算图的支持允许对模型进行实时调整。
- 轻松的多 GPU 支持:使用 PyTorch,数据并行和计算任务的分配变得简单。
接下来将使用一元线性回归来举例,介绍和说明一些深度学习的基础思想和概念说明;
一元线性回归
阅读这部分内容默认你已经有了高等数学基础和Python基础。
首先,如果你一时间想不起来什么是一元线性回归,如下图所示,你会发现这是你经常接触且熟悉的例子:
图片来源:百度百科-解释变量
好的,现在你应该大概理解了什么是一元线性回归,简单来说,使用一条直线来描述一些数据的趋势。现在我们来假设拟合后的直线为:$\Large z(x_1) = w \cdot x_1 + b$ 。现在我们要使得,$\Large Z(x_1) \cong y_1$ 。
其中,$Z(x_1)$ 表示预测值,$x_1$ 表示已知数据,$y_1$ 表示已知数据的实际值。
在一元线性回归的情况下,我们需要通过大量的已知数据,即 $(x_1,y_1)$ 来学习得到 $w$ 和 $b$ 并最终得到预测值 $Z(x_1)$ 。
损失函数
在开始学习之前,我们需要一个函数来衡量我们是否逼近了我们期望的预测值,否则我们并不知道我们有没有达到我们期望的结果,这个函数在深度学习中称为:损失函数(Loss Function:是定义在单个样本上的,是指一个样本的误差,度量模型一次预测的好坏)。损失函数的类型有很多种,例如:
- 绝对值损失函数:$\large L(y,f(x))=|y-f(x)|$
- 对数损失函数,又称为交叉熵损失函数:$\large loss = -[y \log_a + (1-y) \log_{1-a}]$
- 均方差损失函数:$\large loss = (a-y)^2$
当然,还有很多其他的损失函数不再一一列举,在一元线性回归中我们使用均方差函数(使用常规的数学方法最小二乘法):$\Large J= \sum_{i=1}^{m} (z(x_1) - y_1)^2 = \sum_{i=1}^{m} (y_i - wx_i -b)^2$ 。该损失函数,尝试找到一条直线使得直线上下的数据到直线的残差平方和最小。
梯度下降
现在我们来采用机器学习的思想来计算这个最优的值,在机器学习的思想下也是有均方差函数,但是会稍微有些不同:$\large loss(w,b) = \frac{1}{2} (z_i - y_i)^2$ 。或许你会好奇为什么要加个 $\large \frac{1}{2}$ ,答案上来说是因为在我们求导的时候将会把平方项导数的系数 2 给消去,是为了方便我们计算。
现在你或许会好奇为什么要求导,我们来梳理一下整个过程的思路,我们有了能够衡量预测值是否符合我们预期的损失函数,我们有大量的 $(x,y)$ ,现在我们要求参数 $(w,b)$,这个时候其实换一个思想来说,其实 $(w,b)$ 就是我们的变量,而 $(x,y)$ 是我们的参数,我们希望能够将损失函数降低最低,我们需要求损失函数的最小值,而这个最小值是和参数 $(w,b)$ 相关的,也就是求损失函数关于参数 $(w,b)$ 的偏导,来获得损失函数的极值。
现在我们来求损失函数关于 $Z$ 的偏导,也就是求 $Z$ 的梯度:$\Large \frac{\partial{loss}}{\partial{z_{i}}} = z_i - y_i$ 。
现在我们来求损失函数关于 $(w,b)$ 的偏导,来查看 $(w,b)$ 对于损失函数 $loss$ 的影响。
通过求导的链式法则,可以得到 $w$ 的梯度为:$\Large \frac{\partial loos}{\partial w} = \frac{\partial loss}{\partial z_i} \frac{\partial z_i}{\partial w} = (z_i - y_i)x_i$ 。
计算得到 $b$ 的梯度为:$\Large \frac{\partial loos}{\partial b} = \frac{\partial loss}{\partial z_i} \frac{\partial z_i}{\partial b} = z_i - y_i$ 。
反向传播
现在来看剩下的代码片段就可以理解整个过程:
1 | //学习率,或者说梯度下降的每次步长 |
现在你应该可以理解整个公式过程,通过很多次的迭代来逼近最优解,即损失函数的最小值。
使用 Pytorch 实现
在使用这部分示例代码之前,请确保已经成功安装好了 Pytorch 框架和 CUDA 环境。
1 | import numpy as np |
代码来源:0302-利用pytorch解决线性回归问题,做了小部分修改,修复了一个报错问题
运行结果:
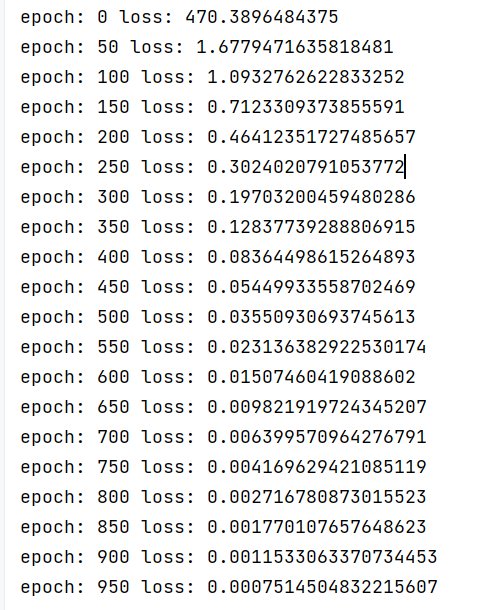
End
这部分内容会让你对深度学习的基本概念和 Pytroch 的使用有一些基本的了解,你或许看不懂相关代码,但是这并不重要,重要的是理解和适应 Pytorch 以及深度学习。
最重要的是要时刻动手去做,才能更深刻的理解。