You may have heard the Guardian has a new cooking app called Feast. With thousands of searchable recipes, cook mode, and lots of other lovely features, it’s been well received on both iOS and Android. You should definitely get it.
No article on its own could possibly do justice to the work that’s gone into making Feast a reality (a big book might be able to pull it off) but this is a look at a vital piece of the app – its data. There’s no recipe app without recipe data. At least, not one with any functionality worth writing home about.
Over the course of Feast’s development we went from zero structured recipes to more than 4,000 and counting. Assembling it was a truly cross-department, collaborative effort, and so far it seems to have come out pretty well.
This is how we did it.
Chicken and egg
What does ‘structured recipes’ actually mean? The Guardian has published recipes for centuries. (Fun fact: the first edition in 1821 promoted a vegetarian cookbook.) These recipes have titles, images, steps. Aren’t they structured? As content, yes. As data, no.
When we talk about structured data, we’re talking about breaking it down a bit like this:
{
"title": "Ratatouille",
"author": "Remy",
"description": "A classic dish guaranteed to evoke tender childhood memories of even the most cynical food critic.",
"ingredients": [
{
"name": "aubergine",
"quantity": "3"
},
{
"name": "courgettes",
"quantity": "4"
}
],
"instructions": [
"Chop vegetables into two-centimetre cubes",
"Defer to prodigious rat controlling you by pulling your hair"
]
}
// Etc.The above is overly simplistic – structured data often has to be more granular – but that’s the gist: recipes in a consistent format of fields and values.
For years recipe data at the Guardian was stuck in a catch-22. Structured data for recipes didn’t exist, so the benefits of having it weren’t felt, meaning structuring recipes wasn’t prioritised, so structured data for recipes didn’t exist. Feast broke that cycle.
To power the app we needed to structure thousands of existing recipes, and update internal tooling to make it realistic (or better yet, easy) for food journalists and editors to sign off on structured versions of new ones.
The recipe for a good model
To have recipe data you need a recipe data model – a consistent shape that captures the nuances of thousands of dishes. This is easier said than done. The data’s form would impact multiple departments for years to come, from editorial to tooling to design.
Settling on a recipe data model had to be a collaborative effort. Nothing else would have worked. Journalists, editors, tooling engineers, data scientists, designers, product researchers … all these groups and more had their say, multiple times.
It is a rare occasion where you really do want lots of cooks in the kitchen. Refining the model was an iterative process. When everyone involved was more or less happy, there was then the small matter of actually creating the data.
Through the Hatch
Structuring recipe data can’t be fully automated. AI is clever, but it has well documented limitations and is worryingly prone to hallucinations. At the same time, asking people to fill in dozens of form boxes for every recipe would have bordered on inhumane.
We needed a solution that combined automation with expert journalistic oversight and curation. This was the approach we settled on:
-
Structure old recipes with a machine-learning model trained in-house by the thoroughly brilliant data science team.
-
Drop the resulting data into a temporary recipe curation tool inside which food journalists could use their expertise to refine and approve recipes.
-
Put the curated data in a database.
-
In parallel the same functionality could be added to the Guardian’s bespoke content management system, Composer. When it was ready to assume recipe curation responsibilities, we could switch over.
In the proud tradition of cutesy names for internal tools, we named our temporary tool Hatch. (Like a kitchen hatch through which food is passed. The recipes are the food, and the hatch … anyway.) With help from the Source design system it looked somewhat professional fairly quickly, and even integrated with other Guardian services like Grid and Pinboard.
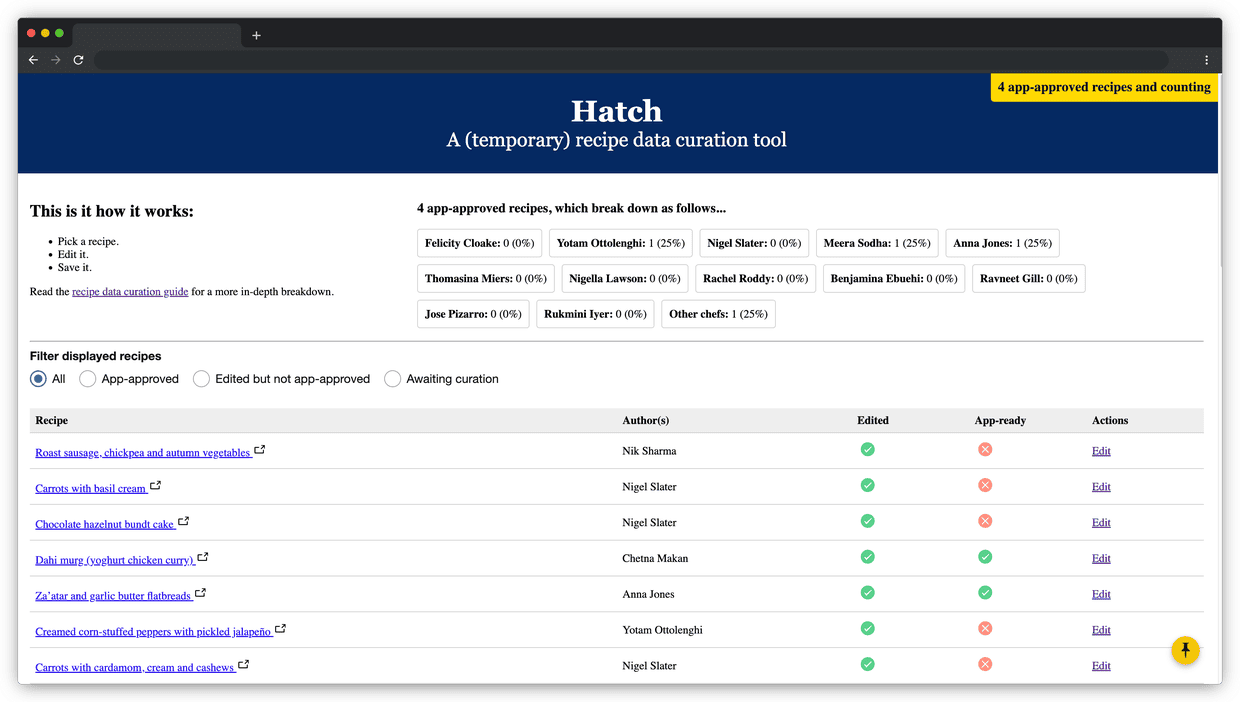
With Feast’s deputy editor Anna Berrill taking the lead on food curation, we were able to hit 1,000 curated recipes by the time Composer was ready to succeed Hatch. Feedback from Anna allowed Chloe Kirton and other members of the Content Production team to massively refine the curation process.
Hatch was duly closed and recipe structured data was fully absorbed into the existing tooling. As anyone who has worked with large tech estates will tell you, there is a unique satisfaction to decommissioning a tool. As I write there are 4,300 structured Guardian recipes, with more added each day.
Piping hot
The end result of this process is a rich and growing recipes dataset that can be used in all sorts of useful and lovely ways. Feast was obviously the catalyst and for now the main benefactor, but a cooking app is just one form the data can take.
Having a structured archive has allowed the Guardian to join the likes of BBC Good Food and NYT Cooking in having recipe schema for recipes published on the web, which has already led to an uptick in organic search traffic to the site.
Feast’s development in many ways showcased the best of the Guardian. For such an extensive recipe structured data archive to come together as quickly and (relatively) painlessly as it did is a testament to the collaborative nature of the project, and to the hard work of dozens of people across multiple departments.
From war reporting to food journalism, the high-water marks come when editorial, engineering, product, and design work together. When it comes off the results really are quite delicious.