6 minute read
The team is busy preparing for COMMA_CON 2025, but we managed to squeeze out a solid release before then! If you want an IRL version of these blog posts, consider coming to COMMA_CON.
In this release, the North Nevada Model 🏜️ (#36276) comes with several improvements in driving performance, stemming from better World Modeling.
Reports for this Driving Model can be found here.
In 0.10.0 we replaced the MPC with a World Model that has knowledge of past and future states. The states were defined by images (encoded by a Compressor) and global 6-DOF ego localization.
Using both images and localization made the inputs over-constrained, i.e., a good enough World Model should be able to infer the localization from the images alone. More importantly, this made the inputs potentially incompatible when enqueuing images produced by the World Model that do not precisely respect the localization requests, which we plan to do in upcoming releases.
In this release we removed the global localization inputs, leaving it up to the World Model to internally infer them and produce a suitable trajectory.
This removal required multiple rounds of improvements to the Compressor and the World Model.
Reports for the new World Model can be found here.
The World Model and the AE Compressor are trained separately. The AE’s objective is to compress the driving images into a compact latent representation, and the World Model’s objective is to predict the future latents given a context. These objectives can be misaligned, leading to a rate-distortion-modelability trade-off.
We improve the AE Compressor by adding image modeling to its objective, better aligning both models. At train time, the AE compresses partially masked images and tries to reconstruct full images [1].
left: partially masked image, right: reconstructed image
We further simplify the architecture by:
Reports for the new Compressor can be found here
To make the World Model more accurate at inferring the ego localization without explicitly providing it as an input, we increased the number of parameters from 500M to 1B.
- n_layer = 24,
- n_head = 16,
- n_embd = 1024,
+ n_layer = 34,
+ n_head = 20,
+ n_embd = 1280,
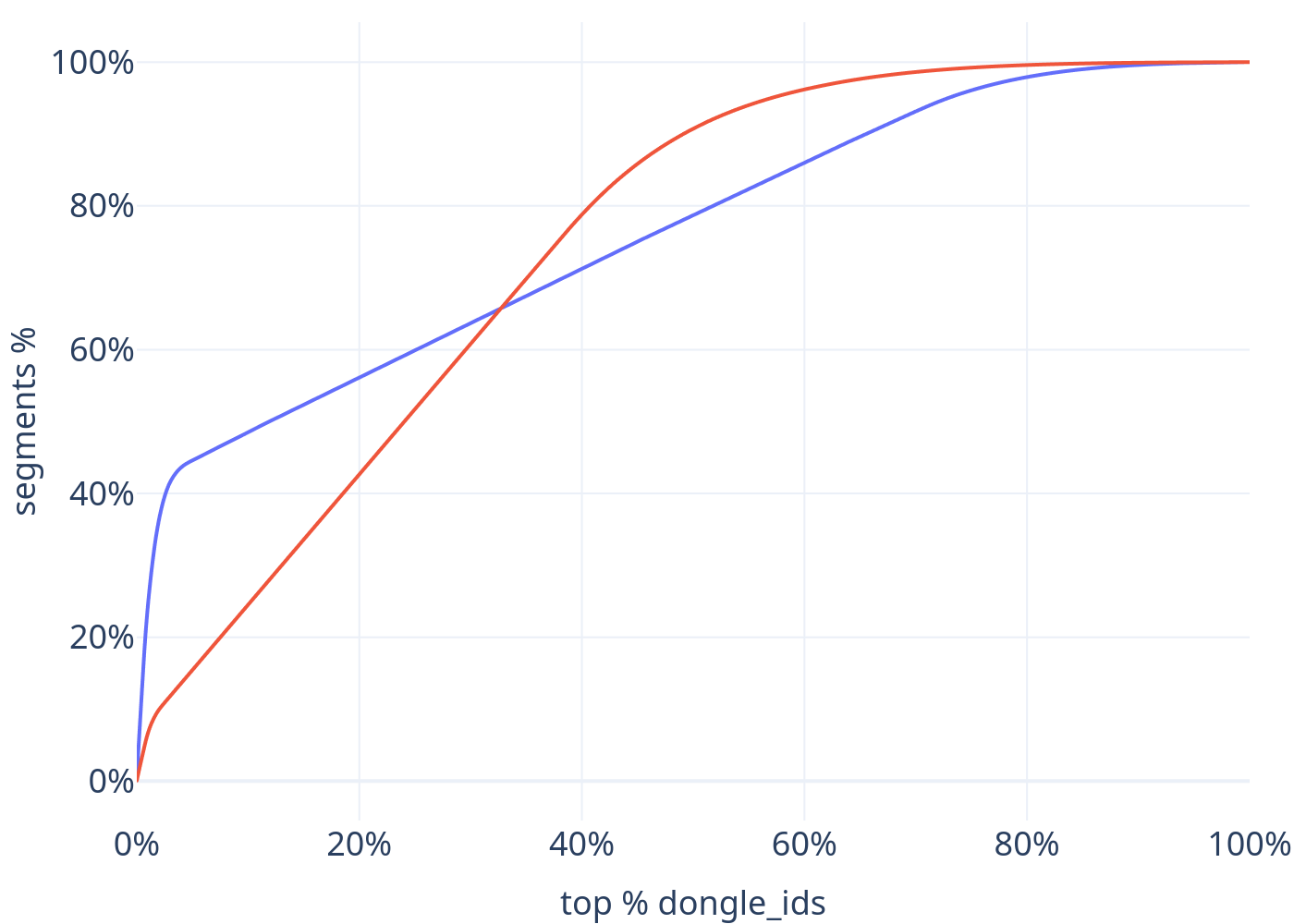
We also train the World Model, Compressor, and Vision Model on a new and bigger training data list. This improves performance of all models, especially the World Model, which is the largest in terms of parameter count. The new list uses Firehose 🔥 data and is overall more diverse than the previous training list.
This chart is wide — scroll horizontally ⟷
■ new training list ■ old training list

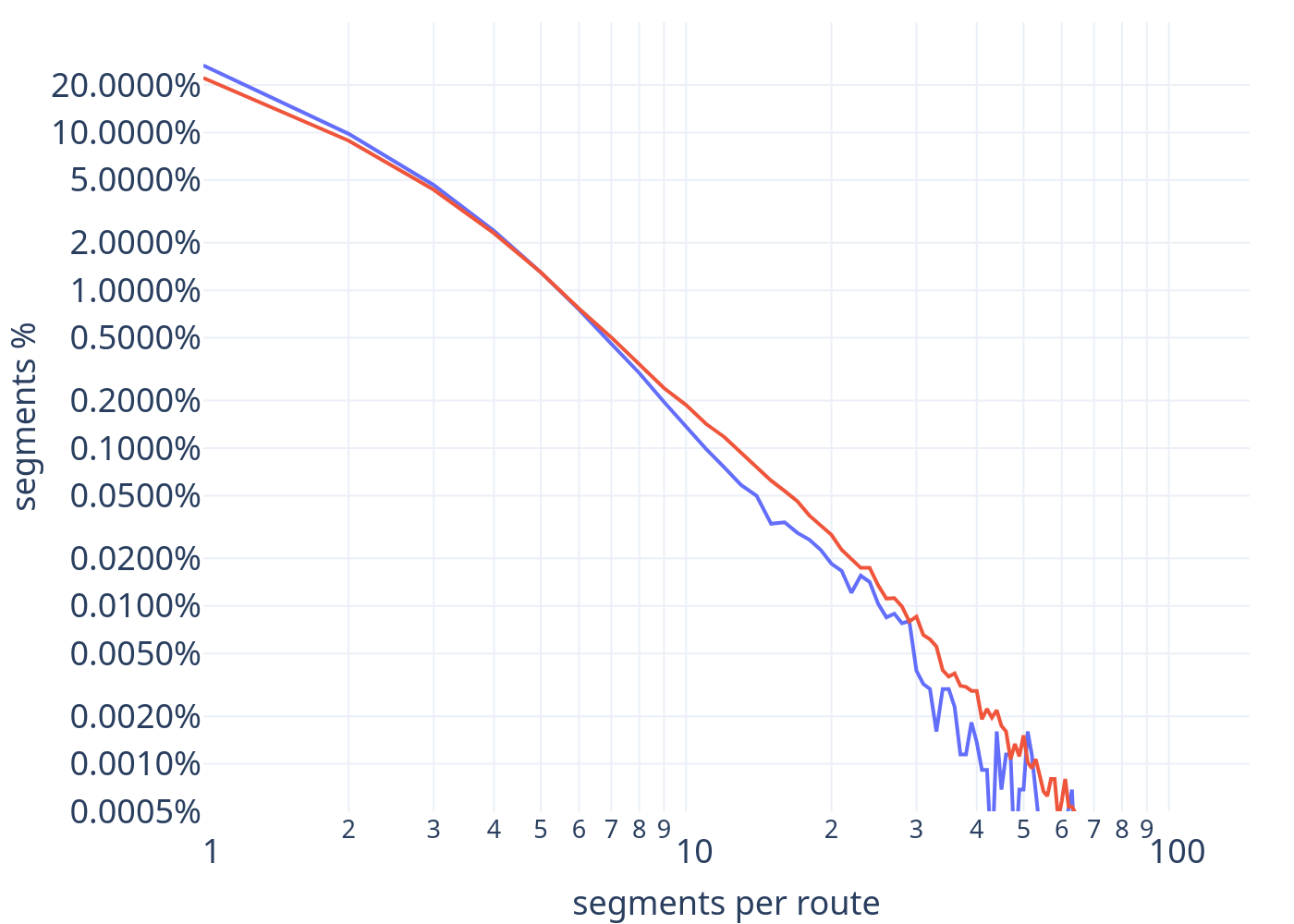
This chart is wide — scroll horizontally ⟷
■ new training list ■ old training list

■ new training list
■ old training list
■ new training list
■ old training list
Functionally there is nothing new in the DM model in this release, but rather it is a result of some substantial (and overdue) cleanups for its training stack. Notably we no longer cache data batches, but dynamically decode and stream data while training, similar to that of the driving model. Training code CI, in-the-loop metrics, and reports help make sure this is equivalent to the previous shipped model despite hundreds of lines in git red diff.
The new training infrastructure allows more flexible dataset tuning and faster model train time. Expect more frequent DM updates.

Less code, faster training, same result
Reports for the new Driver Monitoring Model can be found here
As the world moves towards Rust, openpilot continues to become more Pythonic! Our UI rewrite includes two big changes: moving from Qt to raylib and deleting Weston.
We haven’t fully realized all the benefits yet, but immediately we’re getting:

UI uses less GPU, so more time for the driving model!
This new UI stack makes changes from a redesign to a new SOC port dramatically easier.
Qt is a serious product with a 700+ person company and complex licensing.
Raylib is “a programming library to enjoy videogames programming” written by one guy.
libraylib.a is 2.7M statically linked, and you can’t check Qt’s size with a single du -hs.
Qt is a nice library. But raylib is more “openpilot sized,” and when you pick something that better satisfies your constraints, the rest tends to fall into place, as seen in all the benefits above.
Our Weston is a fork of Qualcomm’s fork of Weston 1.9.0 from 2016. We were likely the first real Qualcomm on Linux users, and while getting the comma three brought up, we were happy to just be off of Android!

The first comma three with a working screen
While we could port over a modern Weston, the best part is no part, so
we replaced Weston with a simple DRM-backend (raylib#16) we call magic.
This special Weston, along with Qt, accounted for roughly a quarter of the hacky bits in AGNOS’s build (agnos-builder#502). The linked PR doesn’t even include our private Qualcomm Weston fork that we couldn’t open source, which we now get to archive.
openpilot is built by comma together with the openpilot community. Get involved in the community to push the driving experience forward.
#driving-feedback on DiscordWant to build the next release with us? We’re hiring.
[1] Chen, H., Han, Y., Chen, F., Li, X., Wang, Y., Wang, J., Wang, Z., Liu, Z., Zou, D. and Raj, B., 2025, January. Masked autoencoders are effective tokenizers for diffusion models. In Forty-second International Conference on Machine Learning.
[2] Goodfellow, I., Bengio, Y., Courville, A. and Bengio, Y., 2016. Deep learning (Vol. 1, No. 2). Cambridge: MIT press. Chapter 14: “Autoencoders."
[3] Mescheder, L., Geiger, A. and Nowozin, S., 2018, July. Which training methods for GANs do actually converge?. In Thirty-fifth International Conference on Machine Learning.
[4] HaCohen, Y., Chiprut, N., Brazowski, B., Shalem, D., Moshe, D., Richardson, E., Levin, E., Shiran, G., Zabari, N., Gordon, O. and Panet, P., 2024. LTX-Video: Realtime video latent diffusion. arXiv preprint arXiv:2501.00103.
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。