Last Friday Anthropic released a new (production at least - has been in beta for a while) 1M context window variant of Opus 4.6 and Sonnet 4.6. This is actually a big breakthrough from my initial experiments.
If you struggle to visualise what a token is - a good rule of thumb I use is that a standard A4/letter-sized page tends to contain around 500-1000 tokens of English[1]. So, 1 million tokens is roughly 1,000-2,000 pages - or about 4-5 novels worth of text.
I think it's important to start by underlining just how many things are improving in the AI space. Across quality, cost, speed (the new Qwen 3.5 models unlock very interesting use cases at a low cost) and now context length, the pace is relentless.
GPT-3.5 had a 4,096 token context window - perhaps a few pages of text - back in late 2022. That steadily increased to around 200K over the intervening couple of years. Now we have a 1M context length on a very capable frontier model (I should add that GPT-5.x also had much longer context windows, but for the most part they were limited to only the APIs).
But wait you might ask - didn't Gemini have this a long time ago? Yes they did, but the results were pretty poor.
There's a concept in LLMs called context rot where as the session with the model grows in length, it tends to drop in quality. It can start 'forgetting' things in its context window you've already said, or worse, confusing concepts and hallucinating more. This has been (one of the many) reasons that most practitioners in the space recommend always starting new sessions as often as possible.
One way to measure this degradation is the 'needle' benchmark. This asks the LLM to recall a certain fact from its context window, and repeat it back (the name comes from the phrase "finding a needle in the haystack").
Like all benchmarks it does have weaknesses, but I thought this chart Anthropic published was very interesting:
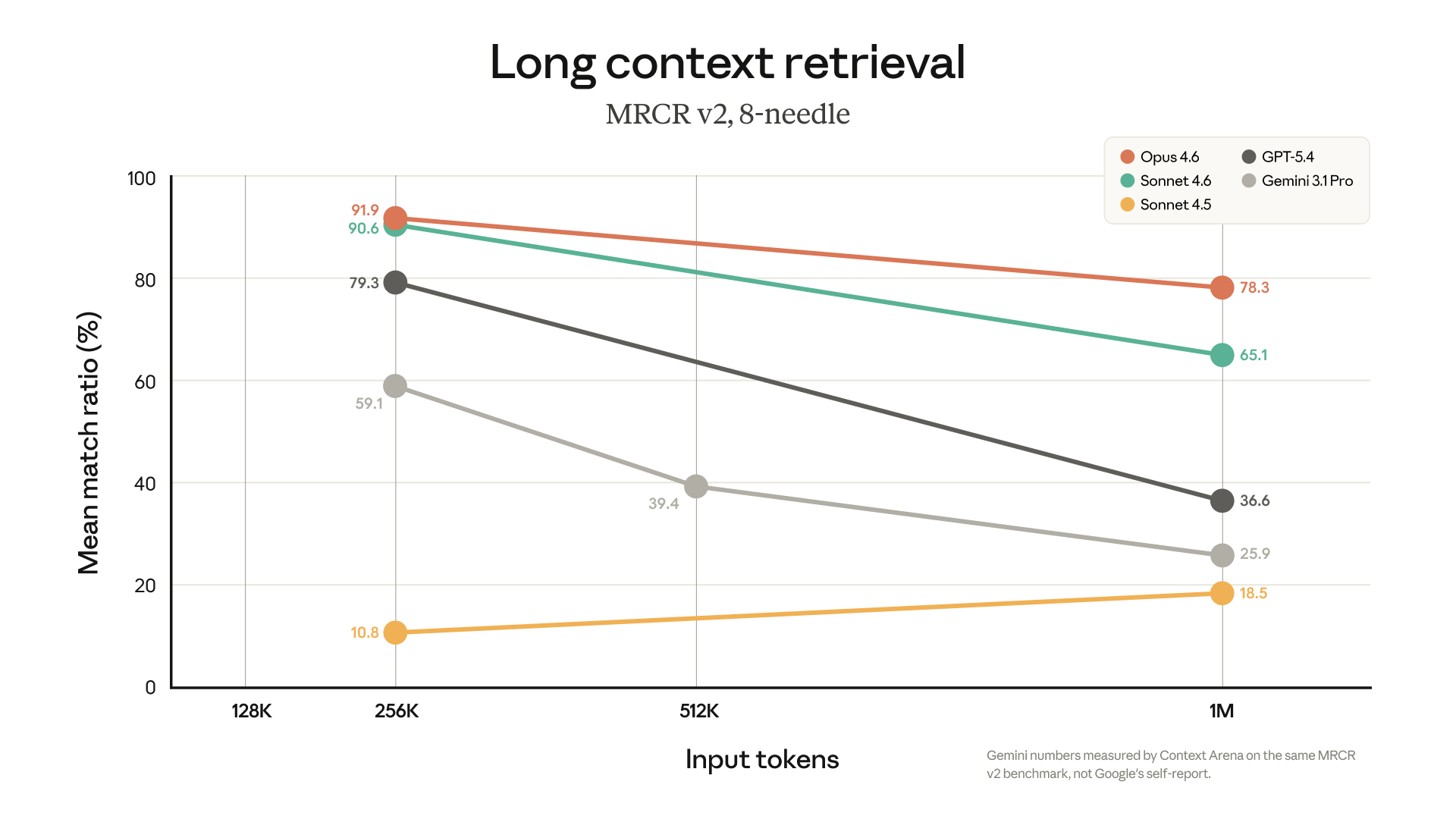
You can see here that while GPT-5.4 and Gemini 3.1 Pro both have 1M context lengths, they quickly degrade past 256K - struggling to get above 50% match ratio at 1M length. This is a real problem for long running agentic tasks.
Now we always need to take these benchmark comparisons from the labs with a pinch of salt - Anthropic has every incentive to pick benchmarks that flatter their own models, they all do. But my rough anecdotal experimentation with Opus 4.6 1M does seem to hold up. I've run a few ~500K token sessions with Claude Code after it was released, and the performance seems very good. It kept on task, and I didn't have to "repeat myself" any more than I'd normally do. It felt extremely natural, just like a normal (shorter context) session with Claude Code.
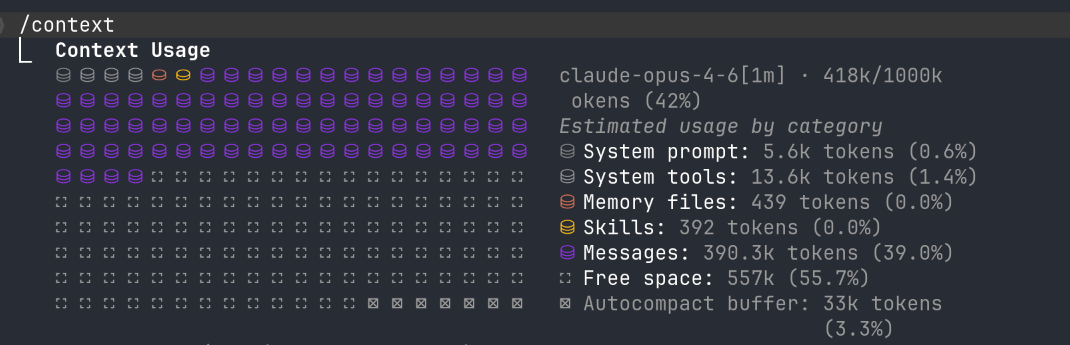
Halfway to a million tokens. No signs of amnesia yet.
I'm interested to see external and third party benchmarks over the coming days to see if there are any gotchas with it, but first impressions are very positive.
Now you may ask why this really matters - how often do you need to have the model remember thousands of pages of text day to day?
The answer is (of course) agentic workflows. If you've used coding agents for any length of time, you'll quickly reach a point where you hit the dreaded 'compaction' stage. Compaction is the process most agents use when they reach the limit of the context window. It condenses earlier parts of the conversation - preserving recent context and key artifacts but losing a lot of the detail from earlier in the session.
While this actually works to some degree, it has a lot of drawbacks.
Firstly, if you're working on a project with many files - which is very common - it often has to start by reminding itself of all these files as the summary isn't detailed enough. This can quickly end up with a bit of a catch 22, where it compacts, reads a tonne of files, then is running low on context to continue. As agents continue to improve in their abilities on very complicated tasks this becomes more and more of an issue.
Secondly, and the more obvious one, is that some agentic tasks do genuinely need to have far more documents in their context window. A classic one is legal tasks - if you are wanting the agent to cross reference hundreds of contracts, it's best for the agent to have the entire contract in its context window, not just summarised/excerpts which can result in poor interpretations. Same for many financial analyst tasks with investor reports.
Ironically software is far better suited to being "excerpted" than many other professional service tasks - programming languages by their nature are far more "modular" and structured than standard "human" documents, and therefore naturally can be searched through and snapshotted with far better results than many other types of documents.
Finally, and an often overlooked one, the models are very good at inferring a lot more from your instructions than is probably obvious. There has been an increasing amount of research on how LLMs can infer a lot about a user's emotional state from "unrelated" messages.
But beyond emotions, I think we end up encoding a lot more subtlety into our agent sessions than we realise. Using compaction - or any form of 'note taking' often loses a lot of this, much like how reading meeting minutes often doesn't capture the actual energy in a meeting.
The real reason this is a big deal is that Anthropic is not charging any more for it. Google and OpenAI both charge 2x input prices past 200-272K tokens - Gemini 3.1 Pro goes from $2 to $4/M, GPT-5.4 from $2.50 to $5/M. Anthropic used to do the same, but with the 4.6 release they've dropped the surcharge entirely.
They've also included it in the Max and Business subscriptions, which Codex (as of writing) doesn't. The competition is relentless in this space.
I had very much expected this to stay behind some "extra usage" flag and at Anthropic's API pricing, ruinously expensive for all but the most valuable agentic workflows.
This also enables enormous token consumption. You can have one agent with 1M context manage and orchestrate many subagents - each with their own 1M context window. The issue with the 128-200K token lengths before was even if your subagent tasks could fit in that, your 'main' orchestration agent would run out of context.
We'll see how this plays out as third party benchmarks come in and more people push it to its limits. But if first impressions hold, this quietly might be one of the most impactful releases of the year.
This is a gross simplification. Different data types (for example programming languages or structured data like JSON or CSV) can use a lot more tokens for the same amount of 'characters' on a document. If you're interested in learning more about this, I'd recommend this article ↩︎
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。