引子
我在开发一个CVE相关的Agent的时候,碰到一个很有意思的Agent编排问题,Agent采用LangGraph框架开发的,具体Agent结构如下所示:
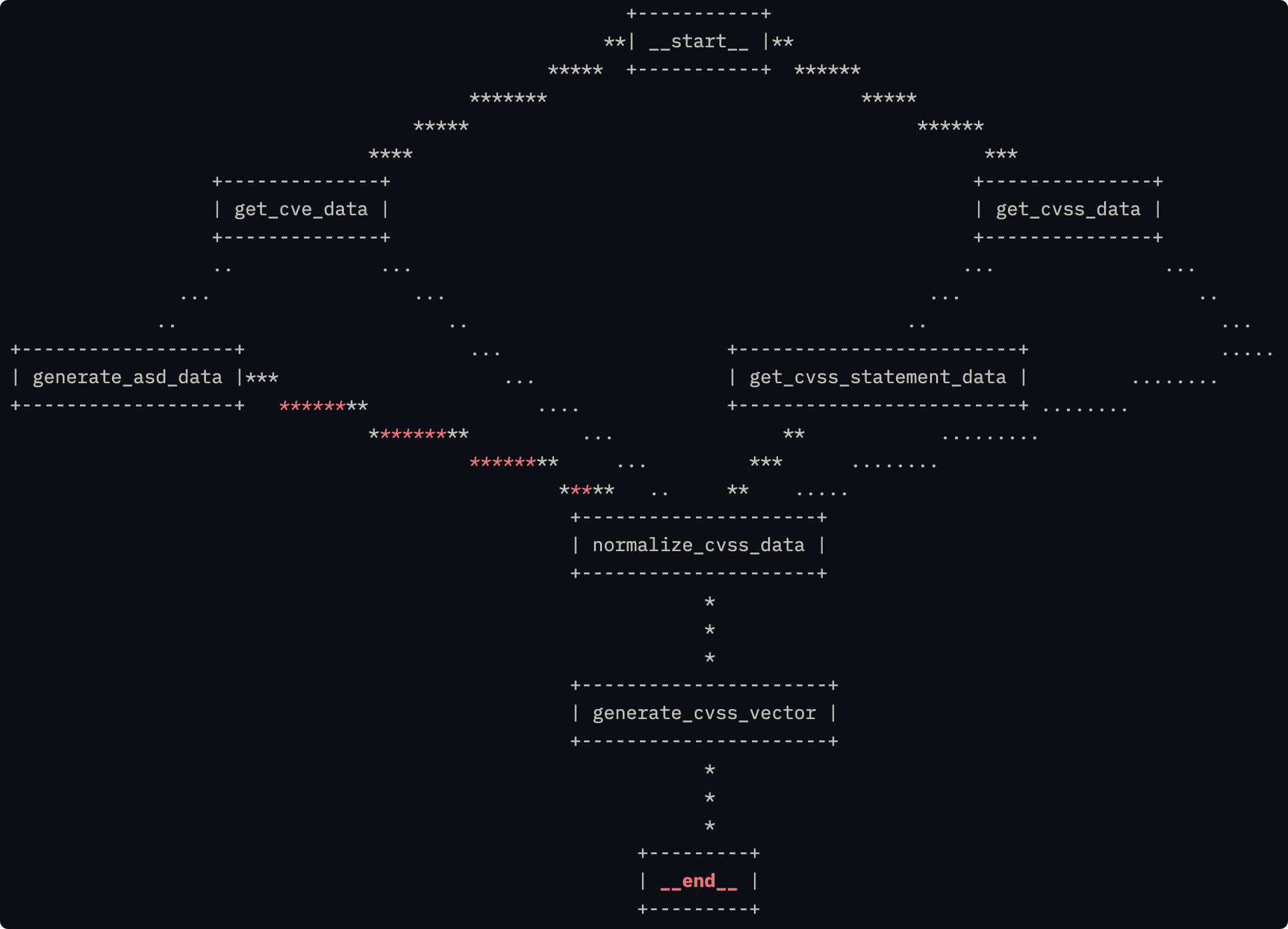
Agent运行的结果不稳定,一开始我以为是Agent常见的幻觉问题,但是基于Graph编排就是为了避免幻觉问题,这很奇怪。在排查tracing和调用日志之后,我发现了一个很奇怪的现象:_generate_cvss_vector 执行了两次,具体日志如下所示:
2025-12-24 12:07:16|x-sec|INFO|./core/agents/mimora/cvss_vector_agent.py:504|_generate_cvss_vector|开始完成CVE风险评估并生成CVSS向量
2025-12-24 12:07:16|x-sec|INFO|./core/agents/mimora/cvss_vector_agent.py:401|_normalize_cvss_data|开始归一化CVSS向量数据
2025-12-24 12:07:26|x-sec|INFO|./core/agents/mimora/cvss_vector_agent.py:527|_generate_cvss_vector|Generated CVSS Vector Response
2025-12-24 12:07:26|x-sec|DEBUG|./core/agents/mimora/cvss_vector_agent.py:528|_generate_cvss_vector|Response content: {
"cvss_vector": "CVSS:3.1/AV:L/AC:L
2025-12-24 12:07:26|x-sec|INFO|./core/agents/mimora/tools/tool_utils.py:19|wrapper|开始执行工具: _calculate_cvss_score, 参数: ('CVSS:3.1/AV:L/AC:L/PR:N/UI:R/S:U/C:H/I:H/A:H',), {}
2025-12-24 12:07:26|x-sec|INFO|./core/agents/mimora/tools/cvss_tool.py:107|_calculate_cvss_score|开始计算CVSS评分: version=3.0, vector=CVSS:3.1/AV:L/AC:L/PR:N/UI:R/S:U/C:H/I:H/A:H...
2025-12-24 12:07:26|x-sec|INFO|./core/agents/mimora/tools/cvss_tool.py:170|_calculate_cvss_score|成功计算CVSS评分: version=3.1, base_score=7.8, base_severity=High
2025-12-24 12:07:26|x-sec|INFO|./core/agents/mimora/tools/tool_utils.py:22|wrapper|工具 _calculate_cvss_score 执行成功,耗时: 0.00s
2025-12-24 12:07:26|x-sec|INFO|./core/agents/mimora/cvss_vector_agent.py:504|_generate_cvss_vector|开始完成CVE风险评估并生成CVSS向量
2025-12-24 12:07:26|x-sec|INFO|./core/agents/mimora/cvss_vector_agent.py:568|_generate_cvss_severity|开始生成CVSS严重性等级
2025-12-24 12:07:35|x-sec|INFO|./core/agents/mimora/cvss_vector_agent.py:527|_generate_cvss_vector|Generated CVSS Vector Response
2025-12-24 12:07:35|x-sec|DEBUG|./core/agents/mimora/cvss_vector_agent.py:528|_generate_cvss_vector|Response content: {
"cvss_vector": "CVSS:3.1/AV:L/AC:L
2025-12-24 12:07:35|x-sec|INFO|./core/agents/mimora/tools/tool_utils.py:19|wrapper|开始执行工具: _calculate_cvss_score, 参数: ('CVSS:3.1/AV:L/AC:L/PR:N/UI:R/S:U/C:H/I:H/A:H',), {}
2025-12-24 12:07:35|x-sec|INFO|./core/agents/mimora/tools/cvss_tool.py:107|_calculate_cvss_score|开始计算CVSS评分: version=3.0, vector=CVSS:3.1/AV:L/AC:L/PR:N/UI:R/S:U/C:H/I:H/A:H...
2025-12-24 12:07:35|x-sec|INFO|./core/agents/mimora/tools/cvss_tool.py:170|_calculate_cvss_score|成功计算CVSS评分: version=3.1, base_score=7.8, base_severity=High
2025-12-24 12:07:35|x-sec|INFO|./core/agents/mimora/tools/tool_utils.py:22|wrapper|工具 _calculate_cvss_score 执行成功,耗时: 0.00s
2025-12-24 12:07:42|x-sec|INFO|./core/agents/mimora/cvss_vector_agent.py:596|_generate_cvss_severity|Generated CVSS Severity Response这与Agent的Graph设计编排动作并不符合,定位过程这里不细说,但是这引起了我对Agent设计模式的好奇,这篇文章我就来探索一下这个问题。
0:00
/0:44

Agent编排有什么问题
在生成式人工智能(Generative AI)从单纯的文本生成向自主智能体(Autonomous Agents)演进的历史进程中,编排框架的架构设计成为了决定系统稳定性、可扩展性和复杂度的核心变量。早期的开发范式主要围绕“链式”(Chain)结构展开,这种线性的 Prompt 序列在处理单一、短程任务时表现出色。然而,随着需求转向能够自主决策、使用工具、自我反思并进行长期规划的“智能体”,线性有向无环图(DAG)的局限性暴露无遗。
Agent系统的本质不再是简单的输入-输出管道,而是一个包含了感知(Perception)、决策(Reasoning)、行动(Action)和观察(Observation)的无限循环。这种循环性(Cycles)打破了传统的 DAG 假设。更为关键的是,Agent系统往往不再是单打独斗,而是演变为多智体系统(Multi-Agent Systems),其中多个专注于不同领域的智能体(如规划者、执行者、审查者)需要并行工作并共享上下文 。
随着Agent系统的演进,在编排Agent系统的时候会碰到很多问题,例如需要解决多智体协作中的竞态条件(Race Conditions)、状态一致性(State Consistency)、循环推理(Cyclic Reasoning)以及容错恢复(Fault Tolerance)等,此时开发者不禁会思考能否有一个图灵完备的编排模型来解决这个问题呢?
面对这样的Agent编排的问题,LangGraph将已经在高性能计算(HPC)和大数据处理领域验证过的 BSP 模型引入到了 AI Agent 的编排中。
为什么是图计算模型
传统的软件工程倾向于将系统建模为服务(Services)或对象(Objects),而 AI Agent 的行为模式更接近于状态机(State Machine) 在图上的随机游走。
- 非线性与循环: Agent 的核心特征是循环(Looping)。例如,ReAct 模式(Reasoning + Acting)本质上是一个 Think -> Act -> Observe -> Think 的闭环。DAG(有向无环图)无法原生表达这种循环,通常需要通过递归调用或外部循环来实现,这会导致调用栈溢出或上下文管理混乱。BSP 模型天生支持循环——循环仅仅是无限的超步序列而已。
- 状态的中心地位: 在 Agent 系统中,Context(上下文/状态)是核心资产。所有的决策都基于当前的 State。BSP 模型强制要求显式的状态管理和版本控制,这与 Agent 对上下文依赖的需求不谋而合。
- 并发与协作: 现代 Agent 系统往往是多角色的(Map-Reduce pattern, Supervisor pattern)。多个 Agent 需要并行工作并汇聚结果。BSP 的栅栏机制天然解决了并行任务的同步与汇聚问题,无需开发者手动编写复杂的 asyncio.gather 或锁机制 。
Google Pregel&BSP模型
Google Pregel框架
Pregel 的核心可以用三个图来概括:
- 怎么算: “顶点状态机” —— 决定节点是工作还是休息。
- 怎么跑: “BSP模型” —— 决定整个集群如何同步。
- 怎么传: “最大值传播示例” —— 演示一个具体算法在图上的流动。
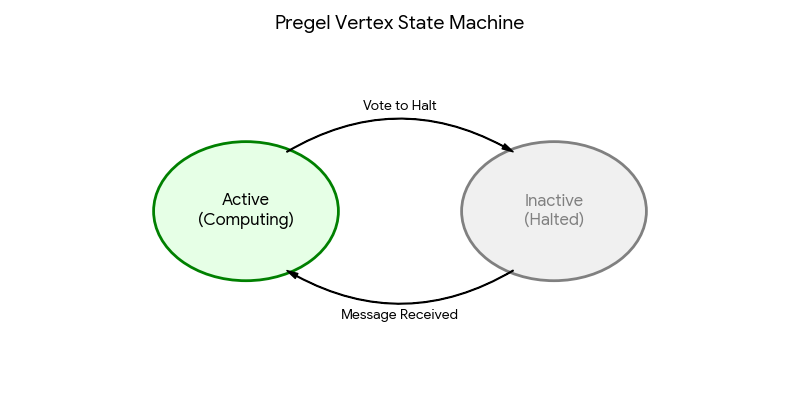
如上图所示,这是 Pregel "Think Like a Vertex"(像顶点一样思考) 的核心。 每个顶点只有两种状态:活跃 (Active) 和 不活跃 (Inactive/Halted)。
- Active (活跃): 顶点正在计算。它可以处理收到的消息,更新自己的值,并向邻居发送新消息。
- Inactive (不活跃): 顶点“睡着了”。如果它觉得自己没活干了(比如计算结果收敛了),就投票休眠(Vote to Halt)。
- 被唤醒: 哪怕顶点睡着了,只要它收到了新消息,系统会立刻把它强制唤醒(切换回 Active),让它处理消息。
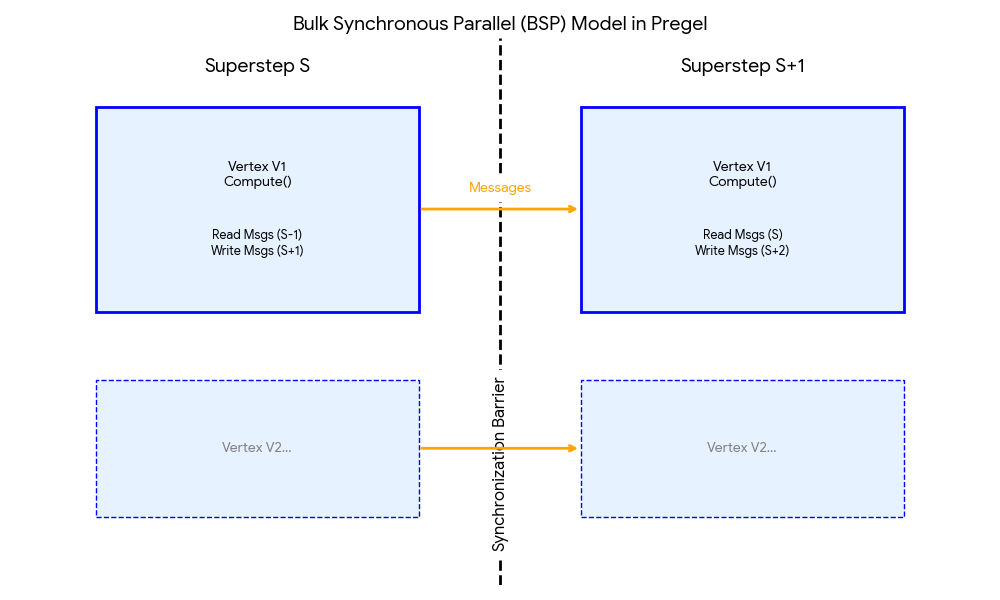
如上图所示,这是 Pregel 在分布式集群上的宏观运行方式。 计算被切分成一个个 Superstep(超步),所有机器必须“齐步走”。
- 计算 (Compute): 所有顶点并行处理自己的逻辑(读上一轮消息 -> 算 -> 发下一轮消息)。
- 通信 (Messages): 这一轮发出的消息,会在网络中飞一会儿。
- 路障 (Barrier): 这是关键。 所有顶点必须都跑完 Superstep S,且消息都传到了,才能一起进入 Superstep S+1。不允许有的跑得快,有的跑得慢。
这种“走一步、停一步、等一等”的模式,解决了分布式系统中极其复杂的死锁和竞态条件问题。
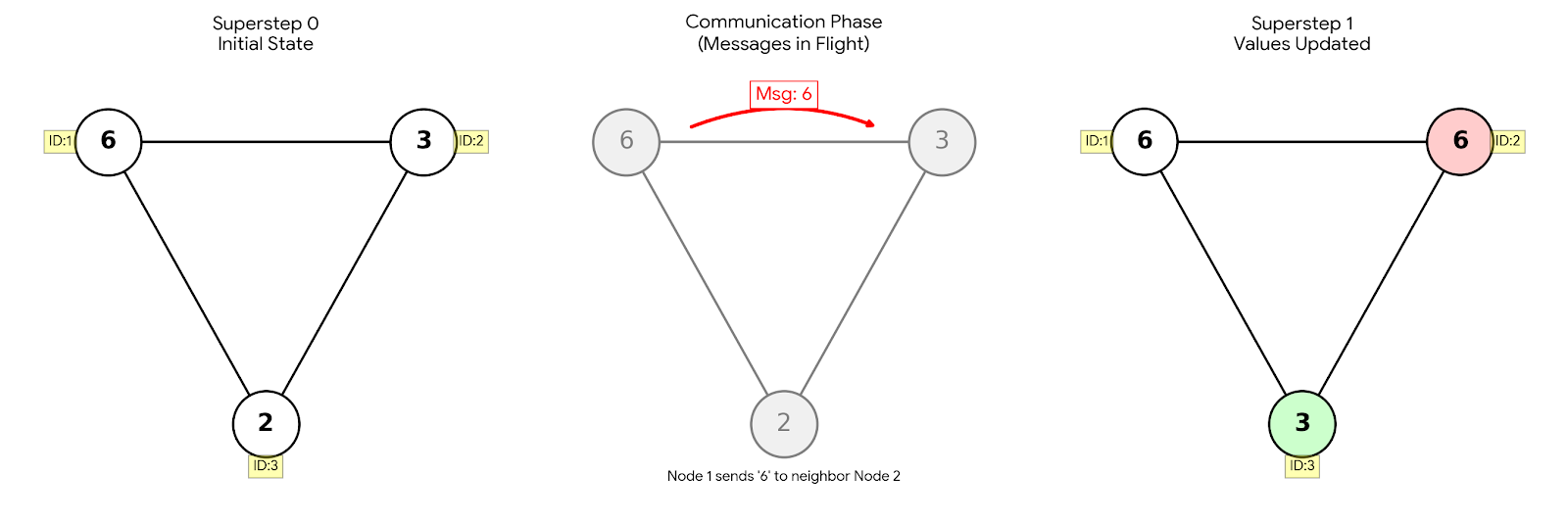
如上图所示,假设我们要在一个图里找到最大的数字(在这个例子中是 6)并传给所有人。
- Superstep 0: 大家都有初始值。节点 1 拿着最大值 6。
- 消息传递: 节点 1 发现自己值是 6,告诉邻居节点 2:“嘿,我有 6”。
- Superstep 1: 节点 2 收到了“6”,对比自己原来的“3”,发现 6 更大,于是更新自己为 6,并在下一轮继续传播。
- 结果: 就像病毒扩散一样,最大值会在几次 Superstep 后覆盖全图。
BSP模型
Bulk Synchronous Parallel (BSP) 模型是一种整体同步并行计算模型,由计算机科学家 Leslie Valiant 提出。它将并行计算划分为一系列 超级步(Superstep) 顺序执行。在每个超级步内,所有处理单元都执行以下三个阶段:
- 本地计算阶段:每个处理单元(例如处理器或节点)使用当前可用的数据执行计算。各处理单元彼此独立、并行地进行局部运算。
- 消息传递阶段:处理单元将本超级步产生的输出发送为消息给其他处理单元。这些消息在本超级步内不会被目标立即处理,而是累积起来供下一个超级步使用。
- 全局同步屏障阶段:所有处理单元在此同步点等待,直到每个单元都完成了本超级步的前两阶段。同步屏障确保没有单元抢先进入下一超级步。
以上三个阶段严格串行发生:只有当所有处理单元完成本地计算后,才进行统一的通信,然后才能执行同步。同步屏障标志着一个超步的结束和下一个超步的开始。整个 BSP 程序由若干连续的超步构成,重复“计算->通信->同步”的流程,直到满足终止条件。由于通信中的消息仅在同步后才可见,这保证了每个超步各处理单元看到的是上一超步结束时的全局一致状态。BSP 模型具有易于编程、性能可预测且不易出现死锁等特点。从程序员视角来看,BSP 提供了一种简洁的并行语义:把并发逻辑写成在同步栅栏之间交替进行的计算和通信步骤,从而降低了思维复杂度。
0:00
/0:51

LangGraph运行时框架解析
这一节主要是研究清楚LangGraph是如何实现BSP模型的(langgraph == 0.3.27),LangGraph运行时框架的核心引擎是 PregelLoop 类 。
状态图(StateGraph)与消息传递
在 LangGraph 中,一切皆始于状态(State)。开发者首先定义一个 StateSchema(通常是 TypedDict 或 Pydantic Model),它规定了图中流动的数据结构。
from typing import TypedDict, Annotated
import operator
class AgentState(TypedDict):
messages: Annotated[list[str], operator.add]
summary: str
这里的 Annotated[list[str], operator.add] 是理解 LangGraph BSP 实现的关键。它定义了一个通道(Channel)及其归约器(Reducer)。
通道(Channels):解耦读与写
在 BSP 模型中,节点不直接写入内存位置。相反,它们向“通道”发送更新。通道是管理状态变更的中间层。LangGraph 提供了多种类型的通道 :
- LastValue Channel(默认): 存储最后一次接收到的值。如果在一个超步中有多个节点向此通道发送数据,通常只有最后一个(或随机一个,取决于具体实现细节)会被保留。这适用于那些全量替换的状态字段。
- BinaryOperatorAggregate Channel: 这是 BSP 并行能力的基石。它允许定义一个二元操作符(如 operator.add)。在栅栏同步阶段,系统会将该超步内所有发往此通道的更新值,以及当前通道的旧值,通过这个操作符进行聚合。多个 Agent 可以并行生成消息,系统会自动将它们追加(Append)到历史记录中,而不会发生覆盖。
- Topic Channel: 类似于消息队列的主题,用于传递瞬时的事件流,不保留历史状态。
PregelLoop:Superstep的生命周期
PregelLoop.tick 方法是 LangGraph 运行时的心跳,每一次 tick 代表一个超步的执行。我们可以将其逻辑分解为以下几个微观阶段 :
阶段一:计划(Plan)
当一个新的超步开始时,运行时首先检查当前的通道版本(Channel Versions)。
- LangGraph 维护着每个通道的数据版本号(通常是递增的整数)。
- 每个节点都订阅了一个或多个输入通道。
- 触发逻辑(Triggering): 如果一个节点订阅的通道在上一轮超步中发生了版本更新(即接收到了新数据),该节点就会被标记为“待执行”。
- 条件边解析: 如果上一轮结束于一个条件边,系统会执行路由函数(Routing Function),确定下一轮应该激活哪些节点。
这一阶段对应于 BSP 模型的“调度”逻辑。重要的是,这种触发是数据驱动的(Data-driven),而非传统的控制流驱动。
阶段二:执行(Execute)—— 局部计算
一旦确定了本轮需要运行的节点集合(例如 Node A 和 Node B),LangGraph 会并行启动它们的执行。
- 读隔离: 每个节点在执行时,读取的是本超步开始时的状态快照(Snapshot)。即使 Node A 在执行过程中“修改”了状态,并行运行的 Node B 看到的仍然是旧状态。这保证了并行任务之间的隔离性。
- 写缓冲: 节点执行完毕后,返回一个字典(如
{"messages": ["Hello"]})。这个返回值不会立即应用到全局 State 中。它被放入一个临时的“写入缓冲区”(Write Buffer)。
这对应于 BSP 模型的“并发计算”阶段。在这一阶段,系统中不存在共享内存的竞争,因为所有的读操作都是基于快照的,所有的写操作都是缓冲的 。
阶段三:更新与栅栏(Update & Barrier)
当本超步内的所有节点都完成执行后,系统进入栅栏同步阶段。这是 LangGraph 发挥魔法的地方:
- 收集写入: 运行时从缓冲区中取出所有节点产生的更新。
- 执行归约(Reduce): 对于每一个通道,运行时应用预定义的 Reducer 函数。例如,如果 Node A 返回 msg1,Node B 返回 msg2,且通道配置为 add,则新状态计算为 State + msg1 + msg2。
- 版本递增: 更新后的通道版本号加 1。
- 持久化: 如果配置了 Checkpointer,此时系统会将更新后的完整 State 序列化并存储到数据库中。
只有在这一系列原子操作完成后,系统才会解除栅栏,准备进入下一个超步。
LangGraph 源码解析
State && Channel
LangGraph 的 State 在底层被编译为一组 Channel 对象,所以 State 的运行逻辑可以通过 channel 的源码来理解。
| 通道类型 (Class) | 对应 State 标注 | 更新逻辑 (update method) | 获取逻辑 (get method) | 典型应用场景 |
|---|---|---|---|---|
| LastValue | int, str (无注解) | value = new_value (覆盖) | 返回当前存储的值 | 状态机流转标志、最新查询词、单一结果 |
| BinaryOperatorAggregate | Annotated | value = reducer(value, new_value) (归约) | 返回归约后的累积值 | 聊天历史 (add_messages)、并行分析结果汇总 |
| EphemeralValue | (内部使用或特殊配置) | 接受更新 | 读取一次后即清空 (Reset after read) | 信号传递、触发器、无需持久化的中间数据 |
| Topic | Topic (显式配置) | 追加到队列 | 返回本轮新增的消息列表 | Pub/Sub 模式、日志流、事件广播 |
# channel 基类抽象
class BaseChannel(ABC):
@abstractmethod
def update(self, values: Sequence[Any]) -> bool:
"""接收更新值,修改内部状态。返回 True 表示状态已变更。"""
pass
@abstractmethod
def get(self) -> Any:
"""获取当前值 (供 Node 读取)。"""
pass
@abstractmethod
def checkpoint(self) -> Any:
"""序列化当前状态。"""
pass
# channel 实现逻辑
# 1. LastValue(默认channel类型)
class LastValue(BaseChannel):
def update(self, values):
if not values:
return False
# 直接覆盖:如果有多个 Node 同时写入,保留列表中的最后一个
# (通常由并行执行完成的顺序决定,或由图拓扑顺序决定)
self.value = values[-1]
return True
# 2. BinaryOperatorAggregate(Reducer channel类型)
class BinaryOperatorAggregate(BaseChannel):
def __init__(self, operator, initial_value):
self.operator = operator # 例如: operator.add 或 add_messages
self.value = initial_value
def update(self, values):
if not values:
return False
# 遍历所有待应用的更新
for new_val in values:
# 支持特殊指令:Overwrite
if isinstance(new_val, Overwrite):
self.value = new_val.value
else:
# 应用 Reducer: old + new -> new_old
# 例如: list + list -> extended list
self.value = self.operator(self.value, new_val)
return True
# 3. Topic(PubSub channel类型)
class Topic(BaseChannel, Value | list[Value], list[Value]]):
"""
一个可配置的 PubSub Topic 通道。
"""
def __init__(self, typ: type[Value], accumulate: bool = False):
self.typ = typ
self.accumulate = accumulate
self.unique = False # 注意:标准实现中通常没有显式的 unique 参数,需通过逻辑推导
#... 初始化内部存储结构
def update(self, writes: Sequence[Value]) -> bool:
# 如果不累积,直接用新值覆盖旧值
if not self.accumulate:
self.values = list(writes) # 替换旧状态
# 如果累积,将新值追加到旧状态
if self.accumulate:
self.values.extend(writes)
return True
Pregel Loop && Superstep
我们可以通过一个简化的伪代码模型来理解 LangGraph 的 _step(单步执行)逻辑。这部分逻辑主要位于 langgraph/pregel/__init__.py 和 langgraph/pregel/loop.py 中(GitHub源码地址)。
# 简化的 LangGraph 运行时逻辑模型 (伪代码)
# 具体实现在 class Pregel(PregelProtocol) --> stream()/astream()
class PregelLoop:
def execute(self, initial_state):
# 1. 初始化通道 (Channels)
# 将输入状态写入对应的通道 (如 'messages', 'count' 等)
self.channels = self.initialize_channels(initial_state)
# 2. 超步循环 (Super-step Loop)
# 只要有待处理的任务,就继续循环
while not self.is_terminated():
# --- 阶段 A: 计划 (Plan) / 触发器逻辑 ---
# 检查哪些节点订阅的通道在上一轮发生了更新
tasks =
for node_name, node in self.nodes.items():
# Trigger: 如果节点的输入通道有新数据,则激活该节点
if self.check_trigger(node, self.channels):
# 准备任务:读取当前状态快照 (不可变)
input_snapshot = self.read_channels(node.inputs)
tasks.append((node_name, node.func, input_snapshot))
if not tasks:
break # 没有任务,图执行结束
# --- 阶段 B: 执行 (Execute) / 并行计算 ---
# 并行运行所有激活节点的函数
# 注意:节点内部无法看到其他节点本轮产生的更新
results = await parallel_execute(tasks)
# --- 阶段 C: 更新 (Update) / 栅栏同步 ---
# 这是 BSP 的核心:统一应用所有更新
checkpoint_writes =
for node_name, result in results:
# 解析节点返回值,确定要更新哪些通道
writes = self.parse_writes(node_name, result)
# 将更新应用到通道 (应用 Reducer)
for channel_name, value in writes:
# 例如: channels['messages'].update(new_msg)
# 如果是 add_messages reducer,这里会执行 list append
self.channels[channel_name].update(value)
# --- 阶段 D: 持久化 (Checkpoint) ---
# 保存当前所有通道的状态到数据库 (支持时间旅行)
self.checkpointer.put(self.channels.snapshot())
# 增加步数,准备下一轮
self.step += 1
在每一轮 Superstep 开始时,运行时需要决定哪些 Node 应该被激活。
- 源码逻辑:系统检查所有 Channel 的 version(版本号)。
- 每个 Node 都有一个订阅列表(Input Channels)。
- 逻辑判断:
if max(channel.version for channel in node.inputs) > node.last_seen_version: - 如果条件满足,说明该 Node 的输入数据发生了变化,Node 被加入 tasks 队列。
- 特殊处理:对于 START 节点或被 Send API 动态调用的节点,它们会被无条件或基于特定规则加入队列。
Checkpointer
中断机制的基石是状态的持久化。没有检查点,图就是无状态的,中断后无法恢复。
检查点的数据结构
一个检查点不仅仅是用户定义的 State 字典。它包含:
- Config (Thread ID): 类似于会话 ID。
- Channel Values: 所有通道的当前值。
- Version Information: 逻辑时钟,用于冲突检测。
- Pending Sends: 尚未处理的消息。
- Next Tasks: 下一步计划执行的任务列表(如果是中断状态)。
# checkpoint 数据结构
# channel_versions 和 versions_seen 是增量计算的核心,
# LangGraph 依靠比对这两个字典来决定下一轮激活哪些节点,而不是全量扫描。
checkpoint = {
"v": 1, # 协议版本
"id": "uuid-...", # Checkpoint ID
"ts": "2023-10-27...", # 时间戳
"channel_values": { # 用户状态
"messages": [...],
"count": 5
},
"channel_versions": { # 逻辑时钟 (关键!)
"messages": 12,
"count": 5
},
"versions_seen": { # 每个节点上次看到的版本
"agent_node": {"messages": 11, "count": 5}
}
}
存储后端与序列化
LangGraph 支持多种 Checkpointer 实现:
- InMemorySaver: 仅用于测试,进程重启即丢失。
- PostgresSaver / AsyncSqliteSaver: 生产环境标准。
默认情况下,检查点使用 pickle 进行序列化。这支持了复杂的 Python 对象(如自定义类),但也带来了安全性和兼容性问题。如果代码更新导致类定义改变,旧的检查点可能无法加载。生产环境建议尽量使用 JSON 兼容的基础数据类型,或实现自定义的序列化协议。
class BaseCheckpointSaver:
def put(self, config, checkpoint, metadata, new_versions):
# 1. 序列化
serialized_checkpoint = self.serde.dumps(checkpoint)
# 2. 写入数据库 (伪 SQL)
# INSERT INTO checkpoints (thread_id, checkpoint_id, data)
# VALUES (?,?,?)
# ON CONFLICT DO NOTHING;
# 3. 更新最新指针
# UPDATE threads SET latest_checkpoint_id =? WHERE thread_id =?
线程级隔离
Thread ID 是实现多用户并发的关键。每个 Thread ID 对应一条独立的状态演进链。中断和恢复必须严格匹配同一个 Thread ID。源代码中,checkpointer.get(config) 方法利用这个 ID 来检索最新的状态快照。
故障恢复与重放 (Replay)
当用户调用 graph.invoke(..., config={"thread_id": "1"}) 时:
checkpointer.get(config)从数据库查出最新的Checkpoint。- PregelLoop 将
checkpoint["channel_values"]恢复到内存中的self.channels。 - PregelLoop 将
checkpoint["versions_seen"]恢复到Node状态。 - 无缝继续: 循环继续运行,仿佛从未停止过。因为所有上下文(包括逻辑时钟)都已完美复原。
Interrupt
# langgraph.types.interrupt 伪代码
def interrupt(value):
# 1. 检查当前是否在 Pregel 循环中
if not _is_in_pregel_loop():
raise RuntimeError("interrupt can only be called inside a node")
# 2. 抛出特殊异常,携带 Payload
# 这会立即中止当前 Node 函数的执行
raise GraphInterrupt(value)
# interrupt 运行时捕获
# PregelLoop.run_task 内部逻辑
try:
result = node.func(input)
except GraphInterrupt as e:
# 捕获中断请求
# 1. 将任务标记为 "interrupted"
# 2. 保存中断产生的值 (e.value) 到 Checkpoint
self.save_checkpoint(...)
# 3. 停止整个 Superstep,不进行 Update
return CreateInterrupt(e.value)
# 恢复 (Resume) 与值注入
# interrupt 恢复有两种方式:
# 1. Command(resume="approved")
# 2. graph.update_state(thread_config, {"input": "hi"})
def interrupt(value):
# 检查是否有 resume 值注入
if _has_resume_value():
# 直接返回注入的值,不再抛出异常!
return _get_resume_value()
#... (抛出异常逻辑)
LangGraph vs. 其他框架
智能体编排范式对比

| 维度 | LangGraph (BSP) | 原生 Asyncio (事件驱动) | 核心差异分析 |
|---|---|---|---|
| 执行流 | 分步式 (Step-wise): 严格的 Read -> Process -> Write -> Sync 循环。 | 连续流 (Continuous): 回调链、Promise 链,任务一旦完成立即触发下一个。 | BSP 提供了更清晰的逻辑结构,易于理解和预测;Asyncio 理论延迟更低,但逻辑难以追踪。 |
| 状态一致性 | 强一致性: 归约器在栅栏处解决冲突,所有节点在下一轮看到的都是一致的合并状态。 | 最终一致性: 容易出现竞态条件,需要复杂的锁机制。 | BSP 避免了复杂的并发锁,降低了开发风险。 |
| 调试体验 | 时光倒流: 支持从任意历史超步恢复及重放。 | 日志追踪: 依赖散落在各处的日志,难以还原全局状态。 | BSP 的“快照”特性是调试神技。 |
| 死锁处理 | 显式检测: 框架可以检测到循环超步限制(Recursion Limit)。 | 隐式死锁: await 可能无限挂起,难以检测。 | BSP 强制设置最大超步数,防止无限循环。 |
框架对比
我对几个使用过的Agent框架进行对比:
- CrewAI 采用了更高级的抽象,通常基于角色的顺序执行或简单的并行。它更像是一个基于“团队”隐喻的封装层。相比之下,LangGraph 更底层 。CrewAI 往往难以处理精细的状态回滚和复杂的条件跳转,而 LangGraph 的 BSP 模型允许开发者控制每一个超步的细节。
- AutoGen 采用了基于“对话”的多 Agent 模式。Agent 之间的交互通过消息流驱动。虽然也具备并发能力,但其状态管理通常分散在各个 Agent 的内部历史中,缺乏一个全局的、版本控制的 State 对象。这使得在 AutoGen 中实现全局一致的“撤销”或“状态修改”比 LangGraph 困难。
高阶Agent设计模式
BSP 架构不仅仅是为了LangGraph解决基础问题,它还解锁了一系列高级设计模式,使得构建能够处理现实世界复杂度的 Agent 成为可能。
Map-Reduce 与动态任务分发(Send API)
在处理文档批量分析等任务时,我们通常不知道文档的确切数量。传统的静态图结构难以应对这种动态性。利用 BSP 的批处理特性,结合 Send API,优雅地实现了 Map-Reduce 模式。
场景: 用户上传了一个包含未知数量文件的文件夹,要求“总结每个文件,然后生成总报告”。
- Map 阶段(超步 1):
Dispatcher节点运行。它读取输入列表,针对列表中的每一项,生成一个Send("process_file", {"file": item})对象。在 BSP 视角下,这相当于在当前超步结束时,动态向图中注入了 $N$ 个并发任务。 - Process 阶段(超步 2): 系统检测到
process_file节点收到了 $N$ 个独立的消息包。于是,系统并行启动 $N$ 个process_file节点实例。由于 BSP 的隔离性,这 $N$ 个实例互不干扰。每个实例处理完后,返回{"summaries": [summary]}。 - Reduce 阶段(超步 3):
Summarizer节点订阅了summaries通道(配置为append归约器)。在超步 2 结束的栅栏处,所有 $N$ 个摘要被自动聚合成一个大列表。Summarizer 在超步 3 被触发一次,接收到完整的列表,生成总报告。
--- config: theme: 'base' themeVariables: primaryColor: '#BB2528' primaryTextColor: '#fff' primaryBorderColor: '#7C0000' lineColor: '#F8B229' secondaryColor: '#006100' tertiaryColor: '#fff' background: '#f4f4f4' --- graph LR A[Planner Node] -->|Generate| B(Send Packet 1) A -->|Generate| C(Send Packet 2) A -->|Generate| D(Send Packet 3) B -.->|Dynamic Spawn| W1 C -.->|Dynamic Spawn| W2 D -.->|Dynamic Spawn| W3 W1 -->|Write to| R W2 -->|Write to| R W3 -->|Write to| R R -->|Trigger| S
代码示例:
import operator
from typing import Annotated, TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.types import Send
# 1. 定义状态
class OverallState(TypedDict):
topic: str
sub_results: Annotated[list[str], operator.add] # 聚合所有 Worker 的结果
class WorkerState(TypedDict):
section: str
# 2. 定义节点
def planner(state: OverallState):
# 动态生成 3 个子任务
sections =
# 返回 Send 对象列表。这不会立即运行,而是安排在下一超步并行运行。
return
def worker(state: WorkerState):
# 并行执行的逻辑
return {"sub_results": [f"Finished section: {state['section']}"]}
def reducer(state: OverallState):
# 当所有 Worker 完成后,本节点被触发
# 由于 sub_results 是 operator.add,这里能看到完整的列表
return {"final_summary": "\n".join(state["sub_results"])}
# 3. 构建图
graph = StateGraph(OverallState)
graph.add_node("planner", planner)
graph.add_node("worker_node", worker)
graph.add_node("reducer", reducer)
# 动态扇出:使用 add_conditional_edges
graph.add_conditional_edges("planner", lambda x: x) # 直接返回 Send 列表
graph.add_edge("worker_node", "reducer") # Fan-in: 所有 worker 写完后触发 reducer
graph.add_edge("planner", END) # 只是为了图完整性,实际流向由 Send 控制
graph.set_entry_point("planner")
app = graph.compile()
这种模式的精妙之处在于隐式同步。开发者不需要编写任何“等待所有 Worker 完成”的代码(如 Promise.all),BSP 的栅栏机制保证了 Summarizer 只有在所有并行的 Map 任务都完成后(即所有消息都已处理并归约)才会被调度。
子图(Subgraphs)
分形的 BSP随着系统复杂度增加,单层图变得难以管理。LangGraph 支持将一个图封装为另一个图的节点,称为子图。在 BSP 模型下,子图的执行表现为嵌套的超步循环。
- 当父图执行到子图节点时,父图的超步时钟“挂起”。
- 子图启动自己的 PregelLoop,拥有独立的 State、独立的超步计数器。
- 子图在内部运行多个超步,直到完成。
- 子图的最终结果作为父图当前超步的输出,父图恢复,进入下一个超步。
--- config: theme: 'base' themeVariables: primaryColor: '#BB2528' primaryTextColor: '#fff' primaryBorderColor: '#7C0000' lineColor: '#F8B229' secondaryColor: '#006100' tertiaryColor: '#fff' background: '#f4f4f4' --- graph LR subgraph Parent Graph Start --> Router Router -->|Complexity High| SubGraphNode Router -->|Complexity Low| SimpleNode SubGraphNode --> End SimpleNode --> End end subgraph SubGraphNode [Child Graph execution] direction LR S_Start((Start)) --> Agent1 Agent1 --> Critiques Critiques -->|Reject| Agent1 Critiques -->|Approve| S_End((End)) end
代码示例:
# 定义子图 (Child Graph)
child_builder = StateGraph(MessagesState)
child_builder.add_node("child_agent", call_model)
child_builder.add_edge(START, "child_agent")
child_builder.add_edge("child_agent", END)
child_graph = child_builder.compile()
# 定义父图 (Parent Graph)
parent_builder = StateGraph(ParentState)
parent_builder.add_node("router", router_node)
#!!! 关键点:将编译后的子图作为节点加入父图!!!
# 在 BSP 运行时看来,这只是一个耗时较长的普通节点
parent_builder.add_node("nested_workflow", child_graph)
parent_builder.add_edge(START, "router")
parent_builder.add_conditional_edges(
"router",
route_logic,
{"complex": "nested_workflow", "simple": "simple_node"}
)
这种设计保证了模块化隔离。子图内部的中间状态(Intermediate State)不会污染父图的全局状态,除非显式地作为结果返回。这使得团队可以并行开发不同的 Agent 模块,最后像搭积木一样组装起来,而不用担心状态命名冲突或版本混乱。
中断与人工介入(Human-in-the-Loop)
这是 BSP 模型相对于连续流模型最“杀手级”的应用场景。在涉及敏感操作(如转账、发送合同)时,Agent 必须暂停并寻求人类确认。在异步函数执行过程中(例如 await llm.invoke(...) 正在等待网络响应时),要“暂停”程序并把状态序列化到磁盘是非常困难的。程序的状态分散在堆栈帧、闭包变量和 Event Loop 的句柄中。
而在 BSP 模型中,每个超步之间的栅栏是天然的、完美的暂停点。
- LangGraph 允许在节点定义中指定
interrupt_before=["approve_node"]。 - 当图执行即将进入
approve_node超步时,运行时检测到中断信号。 - 系统在栅栏处“冻结”:保存当前所有通道的状态,停止调度,释放内存和计算资源。
- 人类介入: 管理员通过 API 查询当前状态,发现 Agent 拟定的合同金额有误。管理员发送一个 update_state 请求,修改了内存中的金额字段。
- 恢复(Resume): 管理员发送“继续”指令。系统加载被修改后的状态,就像什么都没发生一样,进入 approve_node 超步。这种 “冻结-修改-继续” 的能力,完全依赖于 BSP 模型将状态(Data)与执行(Control)解耦的特性。
HITL Agent举例:
# Demo 说明:
# Agent负责处理敏感的转账请求:
# - 输入分析: 提取金额和收款人。
# - 风险评估: 如果金额 > 1000,需要人工审批。
# - 执行转账: 调用银行 API。
# Demo 代码示意实现:
## 定义状态
class State(TypedDict):
amount: int
recipient: str
status: str
## 节点 1: 风险检查
def risk_check(state: State):
if state["amount"] > 1000:
# 触发中断
decision = interrupt(f"Approve transfer of {state['amount']}?")
if decision!= "approve":
return {"status": "rejected"}
return {"status": "approved"}
## 节点 2: 执行
def execute_transfer(state: State):
if state["status"] == "approved":
print(f"Transferring to {state['recipient']}")
return {}
## 构建图
workflow = StateGraph(State)
workflow.add_node("risk_check", risk_check)
workflow.add_node("execute_transfer", execute_transfer)
workflow.add_edge(START, "risk_check")
workflow.add_edge("risk_check", "execute_transfer")
workflow.add_edge("execute_transfer", END)
app = workflow.compile(checkpointer=MemorySaver())
一些Agent设计模式
Agent执行加速
class CVSSVectorAgent:
"""CVSS Vector Agent"""
def __init__(self):
self.data_agent = CVEDataAgent()
self.asd_agent = MitreASDAgent()
self.llm = ChatTongyi(name="cvss-vector-agent-llm", model="qwen3-max")
self.prompt_manager = CVSSVectorPrompts()
self.memory = MemorySaver()
self.agent = self._build_graph()
self.logger = get_logger()
def _build_graph(self):
...
# 添加边
# get_cve_data, get_cvss_data, generate_asd_data 是并行节点用于加速agent执行
builder.add_edge(START, "get_cve_data")
builder.add_edge(START, "get_cvss_data")
Agent Context隔离
# 添加节点
# 通过子图的方式添加数据sub-agent:CVEDataAgent
# CVSSVectorAgent与CVEDataAgent执行的context相互隔离,通过input/output数据耦合
builder.add_node("get_cve_data", self._get_cve_data)
builder.add_node("get_cvss_data", self._get_cvss_data)
# 风险建模Sub-Agent:MitreASDAgent,采用同样的思路进行context隔离
# ASD Agent大约占用8000token的context,非常容易触发token limit
builder.add_node("generate_asd_data", self._generate_asd_data)
builder.add_node("generate_cvss_vector", self._generate_cvss_vector)
builder.add_node("generate_cvss_severity", self._generate_cvss_severity)
Agent并发管理
# 空操作节点,只是用来同步所有路径
def sync_barrier(state: CVSSVectorState):
"""同步屏障节点 - 等待所有前驱完成后再继续"""
return {} # 不做任何操作,只是等待
builder.add_node("sync_barrier", sync_barrier)
# 并行启动
builder.add_edge(START, "get_cve_data")
builder.add_edge(START, "get_cvss_data")
# get_cve_data 的条件边 - 始终经过中间节点
builder.add_conditional_edges(
"get_cve_data",
self._is_cve_data_empty,
{
"generate_asd_data": "generate_asd_data",
"skip_asd": "sync_barrier", # 条件不满足时也走 barrier
}
)
# get_cvss_data 的条件边 - 始终经过中间节点
builder.add_conditional_edges(
"get_cvss_data",
self._cvss_data_check,
{
"get_cvss_statement_data": "get_cvss_statement_data",
"skip_statement": "sync_barrier", # 条件不满足时也走 barrier
}
)
# 中间节点都指向 sync_barrier
builder.add_edge("generate_asd_data", "sync_barrier")
builder.add_edge("get_cvss_statement_data", "sync_barrier")
# sync_barrier 之后才是 normalize_cvss_data
builder.add_edge("sync_barrier", "normalize_cvss_data")
引子问题定位分析(vibe coding版)
引子中提到的这个问题其实是一个Agent编排设计的时候并发问题,大致的问题产生过程如下所示:
0:00
/0:34

有了这个问题之后就很好解决了,我直接指导Cursor来完成问题分析与修复的,与Cursor的交互记录参考下面的附件文件:
References
- Pregel: a system for large-scale graph processing
- Graph API overview - Docs by LangChain
- Pregel | LangGraph.js API Reference - GitHub Pages
- LangGraph runtime - Docs by LangChain
- Building AI Agents Using LangGraph: Part 8 — Understanding Reducers and State Updates | by HARSHA J S
- LangGraph overview - Docs by LangChain
- Use the graph API - Docs by LangChain
- Application structure - Docs by LangChain
- CompiledStateGraph | LangGraph.js API Reference - GitHub Pages
- StateGraph | LangGraph.js API Reference - GitHub Pages
- LangGraph 101: Let's Build A Deep Research Agent | Towards Data Science
- Building Event-Driven Multi-Agent Workflows with Triggers in LangGraph - Medium
- Channels | LangChain Reference
- if there are two nodes(one node has a prenode) go to same one 4th node , then that 4th node will run twice · Issue #5979 · langchain-ai/langgraph - GitHub
- Duplicate node execution when using conditionals - LangGraph - LangChain Forum
- Graph execution goes back to a previous node - LangGraph - LangChain Forum
- Graph execution goes back to a previous node - #3 by ignacio - LangChain Forum
- The Evolution of Graph Processing: From Pregel to LangGraph | by ...
- LangGraph: Multi-Agent Workflows - LangChain Blog
- How Build.inc used LangGraph to launch a Multi-Agent Architecture for automating critical CRE workflows for Data Center Development. - LangChain Blog
- Building LangGraph: Designing an Agent Runtime from first principles - LangChain Blog
- Pregel | LangChain Reference - LangChain Docs
- LangGraph Execution Semantics. | by Christoph Bussler - Medium
- 基于LangGraph开发复杂智能体一则 - 博客园
- Sink node issue, if multiple subgraphs are used in parallel · Issue #1964 · langchain-ai/langgraph - GitHub
- Mastering LangGraph State Management in 2025 - Sparkco
- LangGraph Multi-Agent Orchestration: Complete Framework Guide + Architecture Analysis 2025 - Latenode
- Functional API overview - Docs by LangChain
- My experience using Langgraph for deterministic workflow : r/LangChain - Reddit
- Building Smarter Agents with LangGraph: Tools, Memory & Workflows - GoPenAI
- Comparing AI agent frameworks: CrewAI, LangGraph, and BeeAI - IBM Developer
- LangGraph vs CrewAI: Let's Learn About the Differences - ZenML Blog
- Leveraging LangGraph's Send API for Dynamic and Parallel Workflow Execution
- LangGraph's Execution Model is Trickier Than You Might Think - Atomic Spin
- How does state work in LangGraph subgraphs? - LangChain Forum