
大家好,欢迎收听老范讲故事的 YouTube 频道。
前两天,也就是 6 月 23 日,在德国汉堡,全球超算一年两度的“华山论剑”——TOP500 榜单更新了。榜首换人了,一台叫做灵晟的中国超算悄无声息地空降第一,把霸榜一年多的美国机器 El Capitan 挤到了第二。
这是自 2017 年神威太湖之光之后,时隔 8 年多,中国超算重回世界第一。大家第一个上来喊“遥遥领先”吧?这个事跟遥遥领先还是有点关系的。第二个,有人说这不就是 AI 算力吗?还真不太一样。还有人说,谷歌呢?微软呢?他们怎么不来?怎么让中国这样的一个公司就冲上来了?这个机器、这种超算,难道把它运到德国去跑吗?大家都知道这种超算都挺大的。如果不到德国跑,那它怎么算的分数呢?
咱们把这个事跟大家稍微掰扯掰扯:这到底是个什么比赛,考的什么题,这个题是算什么的,程序是谁写的,成绩是怎么去验证的,这个机器到底有多大、多费电,以及现在这个超算跟 AI 到底是不是一回事。谷歌、微软、xAI、美塔、Oracle 都在这拼命地建算力中心,那咋中国的机器就跑去夺冠了呢?怎么觉得不对呢?中国还有多少这种超算?平时这些机器都干嘛的呢?最后,咱们再讲讲 AI 跟这种超算之间到底是怎么结合的,英伟达能不能顺手把这活干了呢?

首先要说清楚,这到底是一个什么样的比赛,考的是什么题。这个比赛叫 TOP500,它实际上是一个民间榜,从 1993 年开始办,每年 6 月份和 11 月份各发一次,是超算界的高考成绩单。只考一道题,叫做 LINPACK。说人话,就是解一个超大规模的线性方程组,每秒能够做多少次浮点运算,就考这玩意。
这里头要牢记两个词。一个叫实测,英文叫 Rmax,不是厂家吹的理论峰值 Rpeak。Rmax 就是说你要跑这个题,而且要跑稳定,跑很长时间。灵晟实测是 2.198,峰值是 2.736,压榨出了八成的算力,这已经是非常非常强的了。
另外一个词是双精度,FP64。这个数咱们先记着,后边咱们再仔细讲它跟现在的 AI 算力到底有什么区别,就差在这数上了。

那么这道 FP64 的题到底算什么呢?咱们打个比方吧,一架飞机机翼周围应该有气流,我们要用计算机把空气切成几十亿个小方块,每一块的气压、风速、温度都由旁边几个方块来决定。你推我,我顶你,大概是这样的一个过程。
几十亿个方块就有几十亿个相互咬死的方程,必须同时解出来。走完了这一帧以后,你要再解一次下一步怎么样了,要反复算几万次、几十万次,这就是 LINPACK 这道题的真身。
为啥是 FP64 呢?就是它要求的是准,一定要准。因为 FP 后边这个数越高,说明小数点后边留的位数越多。我留得多了以后,最后就可以把误差算得相对比较小。
刚才咱们讲了,这个东西要算几十亿个小方块,里头要迭代几万次,一次模拟上万亿次的运算,一次模拟上万亿次的计算,误差会滚雪球,这个东西叫累计误差。低精度算到后边,模拟的飞机自己在电脑里就散架了,根本就飞不起来。它这个东西必须要特别准,到小数点后十几位的双精度,所以要用 64 位。记住这个“准”字。
那这台机器到底有多大呢?或者说这种机器分不分量级?咱们前面讲过张雪机车的故事,它这个机车比赛是分量级的。你去拳击比赛,也是分量级的,你不能找个大胖子跟人小瘦子去打。
这个 TOP500 分不分量级呢?要讲清楚,这个比赛是不分量级的,没有任何限制。所以这种比赛天然偏向于不差钱的国家队,你做的机器越大、越费电、越烧钱,你的得分就越高。基本上大家可以把它理解成不分重量级的拳击比赛。
当然它也有另外一个比赛,叫 Green500,叫绿色 500,它要计算能效比,就是我的 1 瓦到底能够算出多少次来。在这点上,中国这个机器灵晟比美国那机器就差好远了。

讲到这,机器肯定是巨了的个。这机器到底有多大呢?首先我们先说它的计算速度,是每秒 2.198 百亿亿次双精度。大家知道这数就完了,不需要细究这数到底有多大,反正现在这就是世界最快的了。
它使用的叫 LX2 处理器,一颗处理器上是 304 个核心,每两颗处理器是一个节点,2 万多个节点,4 万多颗 CPU,一共是 1,379 万个核心,装 92 个机柜,基本上可以摆满整个机房大厅。
这个东西肯定是耗电魔兽,这台机器满负荷是 42 兆瓦,跑一年 3.7 亿度电,电费 2 亿多,还得按中国的电费算,还得给它专门配变电站和整套的液冷系统。所以这个东西就是中国这套大力出奇迹的典范。

那你说这机器我能把它运到德国去吗?肯定都不会。你把这机器运到德国去,它连电我估计都烧不起。所以这种机器是在自家跑,提交成绩,然后官方来抽查,通过这样的一个方式去参加比赛的。1993 年起一直是自愿提交的一个状态。
那你说有没有人作弊?怎么能够保证提交的数据是准确的呢?有四道闸门。
而且耗电也是有标准的,因为后边还有 Green500 的这种分级。L1 测全机,还有一个就是 1/64 节点的外推,L2 是 1/8,L3 是整机连网络存储实测。所以超算比赛更像是交一份可复现、可抽查的实验报告。

再说第二名,美国这台 El Capitan 是一台什么样的机器呢?它是美国劳伦斯利弗莫尔国家实验室的机器,由惠普 Cray 制造,1,134 万核,大概是 29.7 兆瓦。它这个机器主要是干嘛的呢?主要是模拟核爆的。
刚才咱们讲,这个劳伦斯利弗莫尔国家实验室是美国能源部的实验室,就是做各种核实验的实验室。现在不让真的去做核试验了,那就只能在电脑里炸了。
它跟咱们的机器最主要的差别在哪呢?咱们这台灵晟是全 CPU 的机器,里头是没有 GPU 的。而惠普造的这个 El Capitan 是一半的 CPU、一半的 GPU,它实际上是 AMD 的算力核心,所以有 CPU 加上 GPU 二合一的这种加速芯片,里边用的是 MI300A APU 的这种芯片。这个芯片对中国也是禁运的,它靠 GPU 加速运算,所以差距就差距在这了。
灵晟是纯 CPU,1,379 万核,42 兆瓦,2.198,它是第一名。而 El Capitan 是 CPU 加 GPU,1,134 万核,29.7 兆瓦,1.809,它是第二。但是耗电我们也比它耗得多,灵晟多耗 4 成电,换来 2 成的性能提升。赢,在绝对值上肯定赢了,但是从能效上来说,稍微差那么点意思。
但是灵晟有一个比较强的地方是什么?全国产,CPU 也是国产的,操作系统也是国产的,就是费点电吧。
既然这个机器是全国产的,那我们就关心它这个 CPU 到底是一个什么样的情况。首先要说,这个 CPU 不是 X86 架构,也不是 RISC-V 架构,这个 CPU 是 ARM 架构,Armv9 架构的。大家注意,Armv9 的所有专利,华为都已经得到授权了,它在没有 ARM 新授权的情况下,可以继续使用 Armv9 架构去设计新的芯片出来。所以这事跟遥遥领先还是有关系的。
这颗芯片是华为参与设计,与鲲鹏系列芯片是一脉相承的。每颗 304 核,由两颗小芯片拼起来,32GB 片上 HBM 加上最多 256GB 的 DDR5 内存,把这玩意放在一起来使用。现在中国你说能有 HBM 吗?也有,就是稍微低一些。咱们现在长鑫存储也是可以做出这东西来的。
那为啥不要 GPU 呢?为啥全要 CPU 呢?它这个核里边内嵌了 ARM 的向量和矩阵单元,所以 CPU 里头干一部分 GPU 的活也是可以干的。在 GPU 的运算上,它叫够用,但是不能算碾压吧。
至于说这个芯片是谁代工、谁做出来的,官方并没有公开。但是华为参与设计,大概率不能在台积电去代工了,因为台积电现在不给咱们做了。所以它大概率还是在中芯国际做的 7 纳米芯片,也怪不得耗这么多电嘛。
那你说我能不能买一个 LX2 的 CPU 来使呢?这个东西是买不到的,因为这个 CPU 是专门给超算来设计的。但是你说我现在想用华为 ARM,也就是鲲鹏的架构,去做自己的服务器,行不行?这个也是可以的,这个芯片是有卖的。所以这个 LX2 算是特种定制款,但是它这套体系,就是鲲鹏这套体系,大家是可以买得到的。
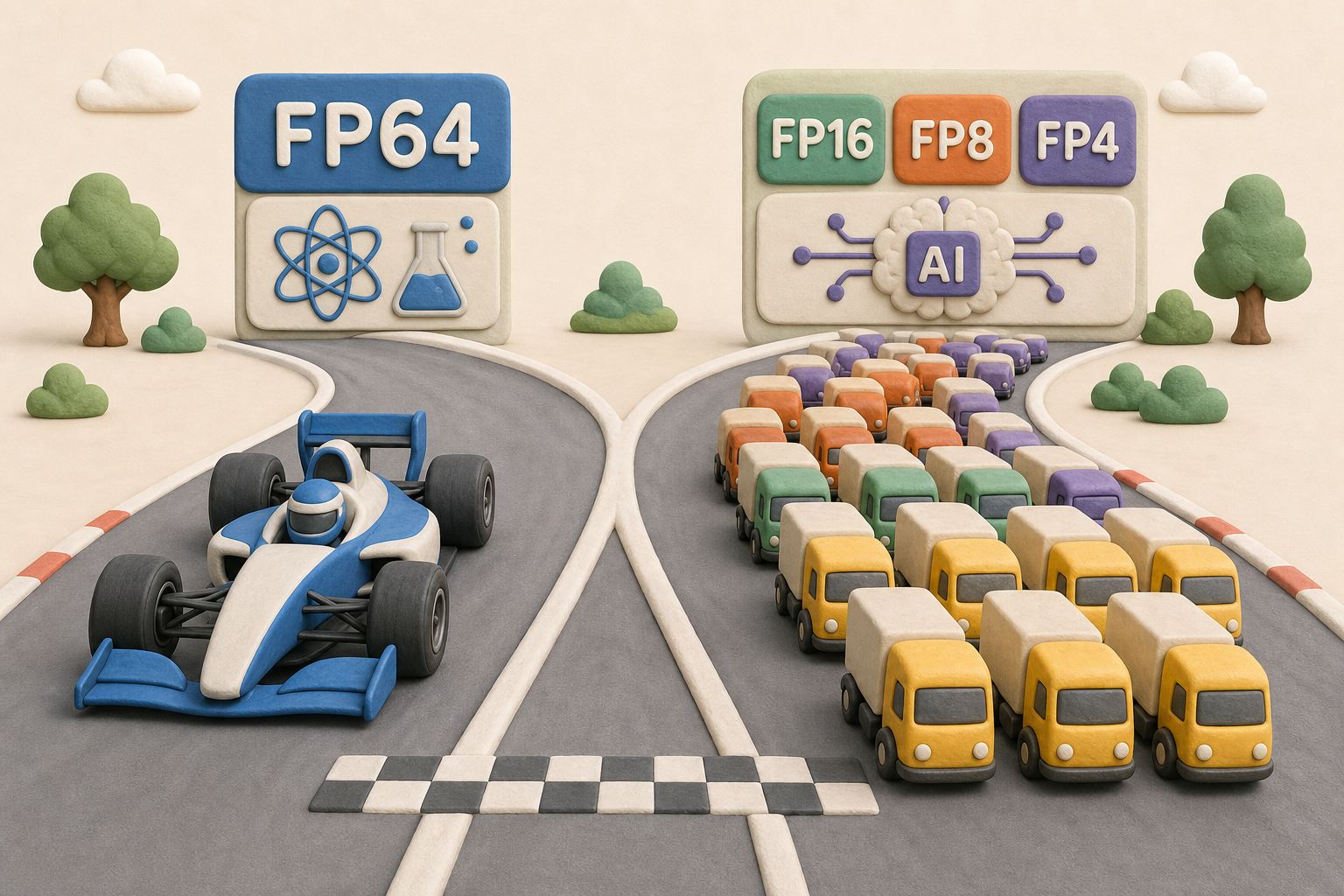
下一件事,你说大家现在拼的都是 AI,都是英伟达,你做了一个这样的东西到底为啥?这跟 AI 有什么关系没有?或者微软、谷歌他们都哪去了?它参加这比赛,不是把中国队碾压了吗?
这要讲清楚。首先微软来了,微软是在微软云里的一台机器去参加了比赛,得了第 32 名吧,反正名次很靠后。谷歌确实没来参加,因为这事跟它没关系。但是要注意,AI 算力跟我们现在讲这超算,是完全两个不同的概念,算的题不一样。
刚才还记得咱们强调那数吗?FP64,它要求的是准,不能有误差,或者误差尽可能要缩小。而 AI 玩的是什么?玩的是快和多。AI 上来了以后就是 FP16,只有 16 位的浮点数,甚至还有 FP8。咱们最新的,比如像 DeepSeek V4,包括现在新的英伟达 GB300 以及华为的昇腾 950 这些芯片,人家玩的是 FP4。我只在 4 位的浮点数上去算,这样就可以同时算更多的数。我不需要你给我算这么准,这么小的误差,差不太多,我只要把这么多的向量算在一起,我就可以得到结果了。所以这完全是算两个不一样的东西的。
让它们这个比赛也会进行这种混合精度计算。混合精度的时候,美国那台 El Capitan 里头塞满了 GPU,它就可以得冠军。但是你说我不算这个低精度的,我就算 FP64 的,那咱们就比它强。
所以超算有点像 F1 赛车,单点登顶,就追求极致的精准。AI 中心有点像万人货运大队,几万张 GPU,求的是吞吐量。但是这个细致的活,你就别找我了。
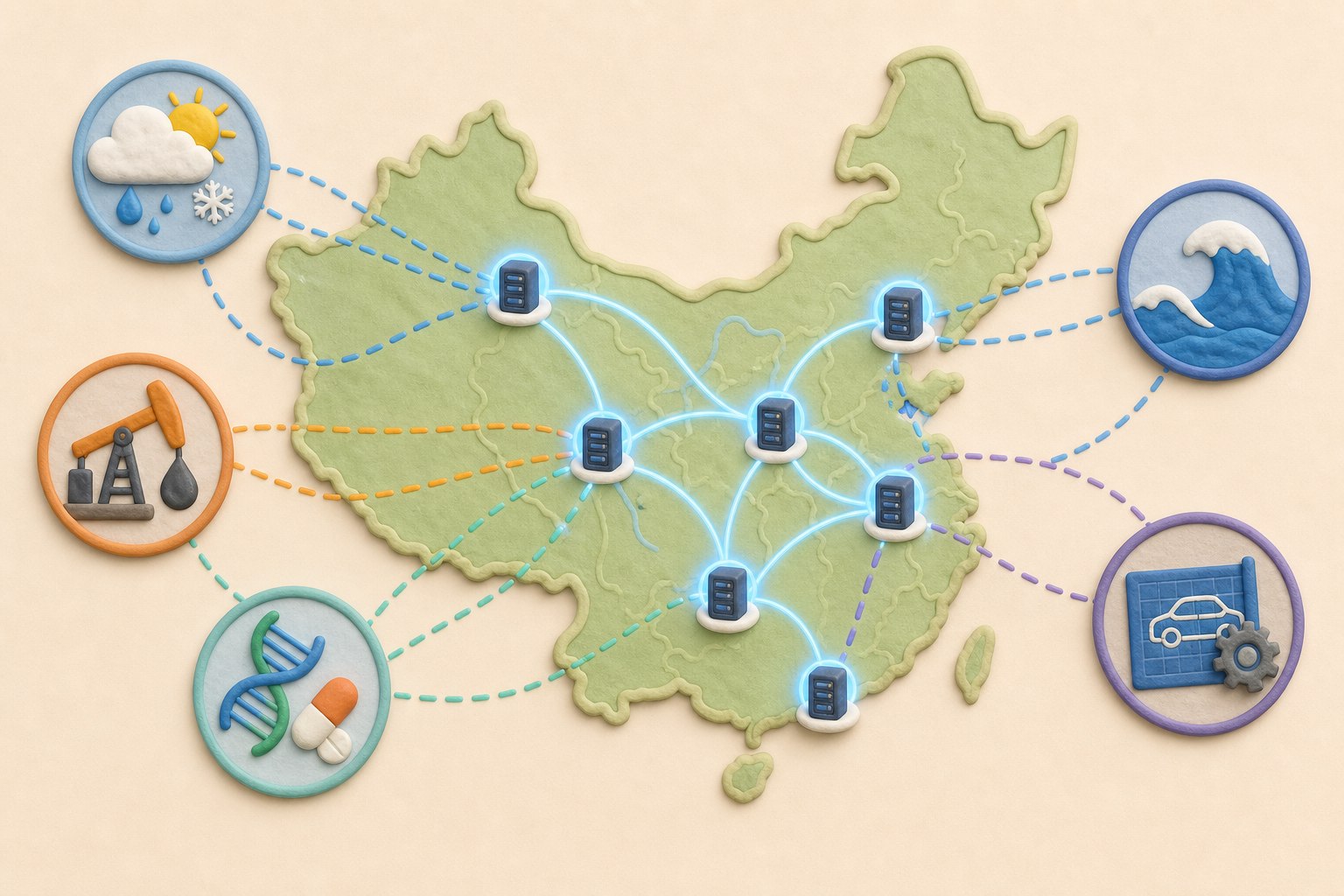
那咱们这台机器干嘛使的呢?刚才咱们讲了,美国那台机器是玩核爆的,咱们这台机器来自于深圳超算中心。深圳超算中心其实主要是算天气的,天气预报,各种天气的长期模拟和仿真,主要干这个使的。
中国还有很多的这种超算中心:
所以中国是有一套网络,骨子里边是给产业、科研当水电煤来使用的。美国是把最强的机器供起来做绝密国防的,这个是两个不同的模式吧。

很多人就说,这 AI 跟这种超算到底是什么关系呢?我在这上跑大模型行不行?肯定不行,这上跑大模型会跑得慢死的,因为里头没有 GPU,全是 CPU。
那你说我什么时候用超算,什么时候用 AI 呢?其实在这种配合上有两步。
什么意思呢?就是超算可以仿真地震、天气、核爆,做一大堆的仿真数据以后,直接把这些数据塞给 AI 大模型,让它把这个数据吞进去,训练了以后,你下次问这个 AI 大模型说,来,给我仿真一下核爆了以后会怎么样,它会快速地给你得出一个结果,而且这个结果相对来说还比较准确。
这个有点像什么呢?就是你上超算计算出一大堆的结果来,然后总结规律,变成这个九九乘法表。然后你让旁边的一个一年级小朋友说,来,把九九乘法表给我背下来。背完了以后说,给我算一下这个几乘几,啪就给你算出来了。它是这样的一个工作方式,这就是 AI 跟超算之间相互结合的玩法。
那有人说,上英伟达是不是可以碾压国内这台灵晟呢?还不行。英伟达现在为了能够进行更高效的 AI 运算,也就是低精度的高并发运算,它故意阉割了自己 FP64 的能力。现在英伟达的 GB300,它在 FP64 上的能力比它早期的这些芯片还要次,还要再差一些,这个就是不同的进化方向。
最后咱们总结一下。
所以灵晟能够在时隔 8 年之后夺冠,确实是我们做出了巨大的努力,这是值得肯定的。但是也不要上来就喊遥遥领先,我们什么都强,我们还是要理性地来看待这件事情。
好,今天这个故事就讲到这里。感谢大家收听,请帮忙点赞,点小铃铛,参加 Discord 讨论群,也欢迎有兴趣、有能力的朋友加入我们的付费频道。再见。

此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。