前置声明:本图文存在AI辅助整理
Day1 配环境、Day2 跑微调,到了 Day3 终于进入我最期待的环节——Agent 智能体。如果说 Day1 是“磨刀”、Day2 是“砍柴”,那 Day3 就是“造一个能自己找刀、自己砍柴的机器人”。
说实话,之前对大模型的认知一直停留在“问答”层面,给个 prompt 它回一段话。但 Agent 这个概念打开了一扇新的大门:模型不再只是被动回答问题,而是能主动调用工具、规划任务步骤、协作完成复杂目标。今天的实训让我真切感受到了这种能力的魅力。
今天的内容来自小牛翻译 & 东北大学自然语言处理实验室的「Agent 前置训练课程」。整个实训围绕一个核心目标:学会如何让大模型(Qwen3-1.7B)通过工具调用完成实际任务。

用到的技术栈:
服务器依然是那台 NVIDIA H200 NVL(Docker 分配约 23GB),不过今天跑的是 Qwen3-1.7B 这个轻量级模型,显存压力比 Day2 的 SFT/DPO 小多了。
大模型最开始的形态是聊天机器人——你说一句,它回一句。但这种模式有个明显的天花板:模型只能依赖预训练知识,无法获取实时信息,也无法执行实际操作。
Agent(智能体)的核心思想是:给大模型配备工具,让它在推理过程中自主决定何时调用什么工具,然后根据工具的返回结果继续推理,直到完成任务。
这就像给一个人配备了计算器、百科全书和记事本。遇到问题,他先判断需要什么工具:需要计算就拿起计算器,需要查资料就翻开百科全书,需要记录就打开记事本。工具的使用是循环的——用了一次之后,带着新的信息继续思考,可能还需要再用其他工具。
用户任务 → Agent(Qwen3-1.7B)→ 判断需要什么工具
↓
调用工具(计算/读取/生成等)
↓
获取工具返回结果
↓
继续推理 → 完成任务
模型通过本地的 vLLM 服务提供 OpenAI 兼容接口,代码里用 AutoGen 框架创建 Agent 并把自定义工具注册给它。整个过程都在内网服务器上完成,不需要调用任何外部 API。
今天的代码 organized 得很好,四个任务分别放在四个目录里:
agent_practice/
├── task1/ # 基础工具调用
├── task2/ # 多 Skill 数据分析
├── task3/ # GSM8K 批量推理(选做)
└── task4/ # 知识库问答(选做)

用 vLLM 启动本地模型服务,提供 OpenAI 兼容接口。端口号改成了我们组的 8005:
CUDA_VISIBLE_DEVICES=0 vllm serve Qwen3-1.7B \
--host 127.0.0.1 \
--port 8005 \
--enable-auto-tool-choice \
--tool-call-parser hermes
几个关键参数:
--enable-auto-tool-choice:允许模型根据任务自动选择工具调用--tool-call-parser hermes:指定工具调用解析器,使模型输出能被正确解析为工具调用
启动成功后,服务监听在 http://localhost:8005/v1,代码里的 openai_api_base 都要对准这个地址。
让 Agent 同时拥有两个工具:安全计算器(safe_calculator)和单位转换器(unit_converter)。Agent 必须使用工具完成数学计算和单位换算,最后用中文解释结果。
safe_calculator 使用 ast.parse 把表达式解析成抽象语法树,再递归计算。这比直接用 eval 安全多了——只允许特定的运算符和函数(sqrt、abs、round 等),根本执行不了任意代码。
unit_converter 支持长度和质量单位的换算。核心思路是“先统一到基准单位,再从基准单位换算到目标单位”——比如 km→m 是先乘 1000 统一到米,再除以目标单位的比例。
agent = llm_factory.create_agent(
name="local_qwen_tool_agent",
model="Qwen3-1.7B",
tools=[safe_calculator, unit_converter], # 注册两个工具
system_message=(
"You are an assistant proficient in using tools. "
"When encountering mathematical calculations, "
"you must use safe_calculator. "
"When encountering unit conversions, "
"you must use unit_converter. "
"Summarize results in Chinese."
),
max_tool_iterations=5,
)
任务 prompt:
Calculate: (23 * 17 + sqrt(81)) / 5
Convert 3.2 km to m
Finally, summarize the results in chinese.
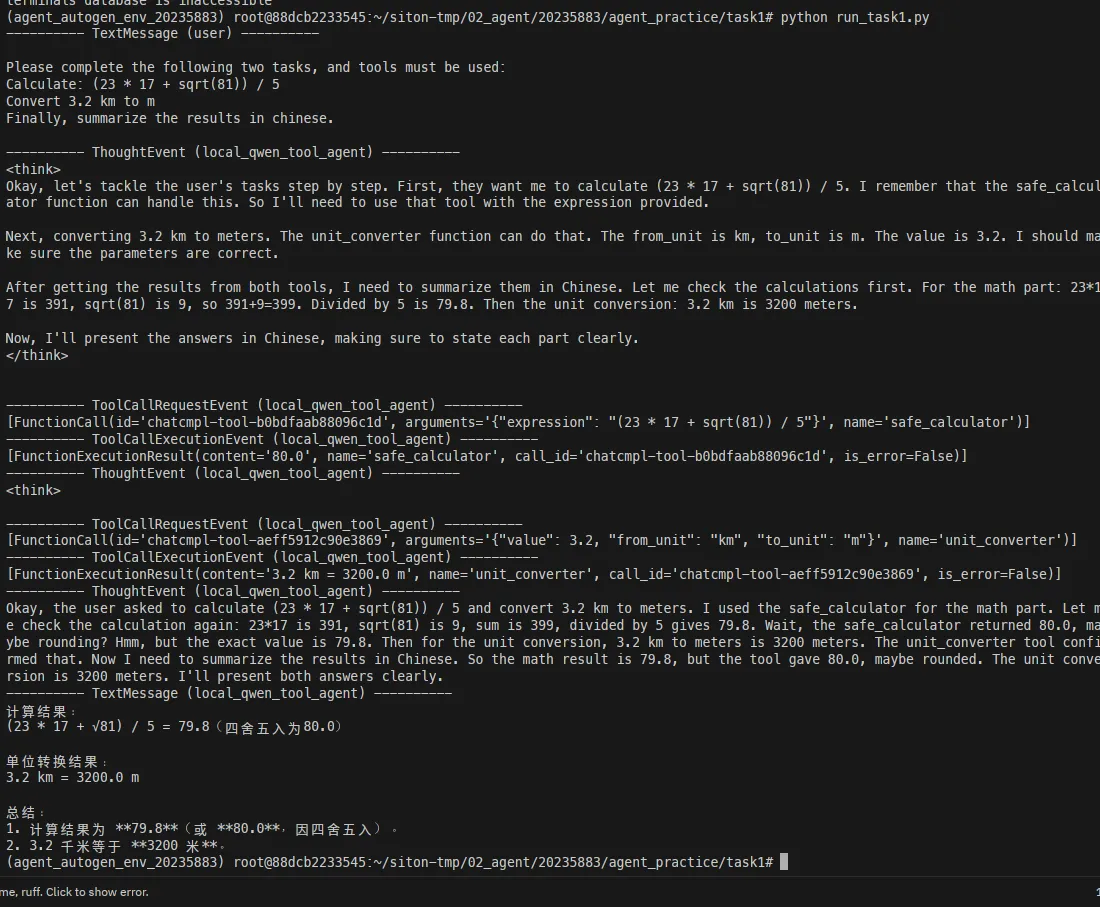
Agent 完成了两次工具调用:
| 任务 | 工具 | 参数 | 返回 |
|---|---|---|---|
| 数学计算 | safe_calculator | (23 * 17 + sqrt(81)) / 5 |
80.0 |
| 单位换算 | unit_converter | 3.2, "km", "m" |
3.2 km = 3200.0 m |
最后用中文总结了结果。整个过程模型自己判断需要什么工具、传什么参数,完全不需要人工干预。这就是 Agent 的魅力——你只需要说“做什么”,不需要说“怎么做”。
让 Agent 使用三个 Skill(MathSkill、SalesDataSkill、ReportSkill)完成销售数据分析:读取 CSV → 汇总数据 → 计算指标 → 生成 Markdown 报告。
这个任务比任务一复杂得多,需要多个工具协作完成。设计上把功能分成三个 Skill,每个 Skill 负责一块:
| Skill | 工具 | 作用 |
|---|---|---|
| MathSkill | safe_calculator | 精确计算利润率和平均销售额 |
| SalesDataSkill | summarize_sales_csv | 读取 sales.csv,按产品汇总 |
| ReportSkill | write_markdown_report | 把分析结果写入 Markdown 文件 |
三个 Skill 通过 skills/__init__.py 合并成一个 ALL_TOOLS 列表,创建 Agent 时统一传入。
任务二让我深刻体会到了一个关键点:system_message 怎么写,直接决定了 Agent 会不会正确调用工具。
我的 system_message 里明确约束了三种情况:
system_message = (
"You are a sales data analysis agent. "
"You have three skills:\n"
"1. MathSkill: Used for precise calculations.\n"
"2. SalesDataSkill: Used for reading and summarizing sales CSV.\n"
"3. ReportSkill: Used for writing Markdown reports.\n"
"When the task involves CSV analysis, "
"the summarize_sales_csv function must be called.\n"
"When the task involves precise calculations, "
"the safe_calculator must be invoked.\n"
"When a task requires generating a report file, "
"the write_markdown_report function must be called.\n"
"The final answer must be in Chinese."
)
注意这里用了“must be called”这种强制性措辞。如果写得太温和(比如“you can use”),模型可能会偷懒直接心算,不调用工具。

Agent 按顺序调用了三个工具:
生成的报告包含所有要求的指标,结论明确。这个任务让我理解了Skill 的模块化设计——把不同功能拆成独立的 Skill,既方便复用又方便维护。
复用任务一的安全计算工具,对 GSM8K 数据集中的 10 道数学题进行批量求解,统计准确率。
批量任务最大的坑是上下文污染。如果让同一个 Agent 连续做 10 道题,前面题目的推理过程会干扰后面的判断。
解决方案:为每道题创建一个独立的 Agent 实例(name 带题号),每道题都是“fresh start”:
agent = llm_factory.create_agent(
name=f"gsm8k_math_agent_{idx}", # 每道题独立
model=model,
tools=[safe_calculator],
system_message=(
"...Output FINAL_ANSWER: <number>..."
),
max_tool_iterations=8,
)
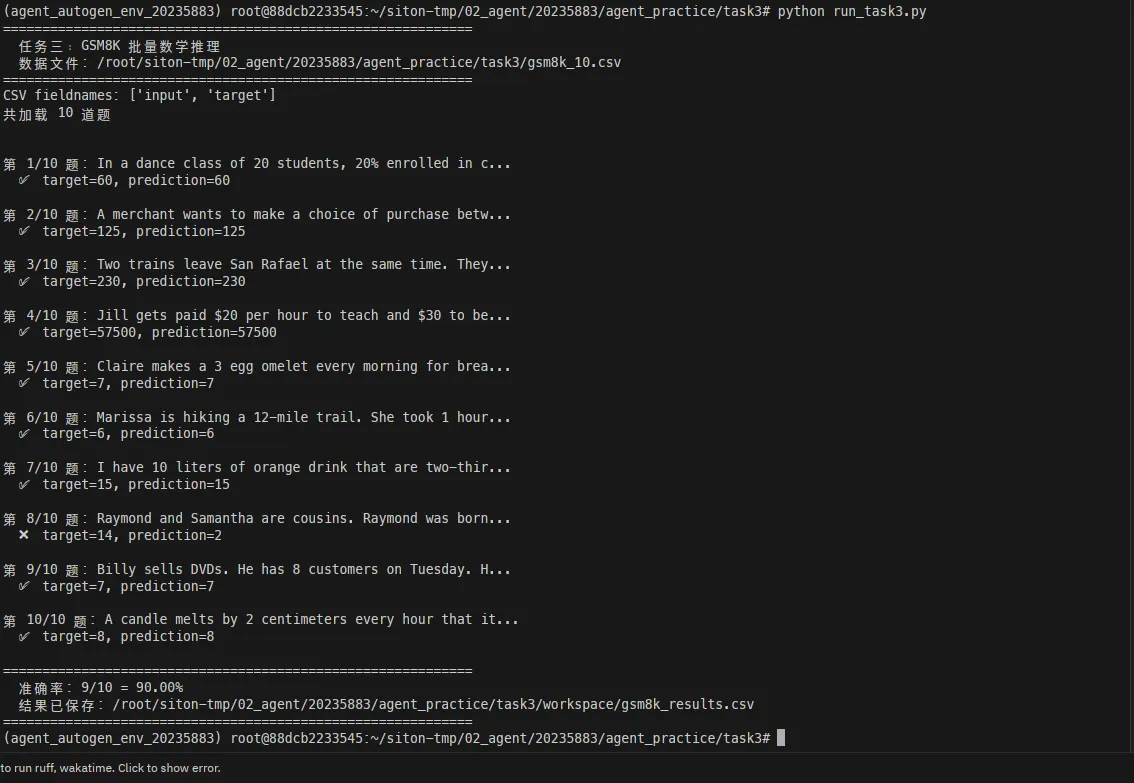
10 道题的结果:
| 题号 | 答案 | 预测 | 正确 |
|---|---|---|---|
| 1 | 60 | 60 | ✓ |
| 2 | 125 | 125 | ✓ |
| 3 | 230 | 230 | ✓ |
| 4 | 57500 | 57500 | ✓ |
| 5 | 7 | 7 | ✓ |
| 6 | 6 | 6 | ✓ |
| 7 | 15 | 15 | ✓ |
| 8 | 14 | 2 | ✗ |
| 9 | 7 | 7 | ✓ |
| 10 | 8 | 8 | ✓ |
准确率:9/10 = 90%
第 8 题错了——那是一道年龄关系推理题,Agent 在理解题意时出现了偏差。这也说明本地小模型在复杂逻辑推理上仍有局限,不过对于计算类题目表现相当不错。
这是今天最复杂的任务——从零实现一个多文档知识库问答 Agent,完成“检索 → 提取 → 回答 → 计划 → 报告 → 验证”的完整闭环。
| Skill | 工具 | 作用 |
|---|---|---|
| DocumentSkill | list_documents / search_documents / read_document | 文档检索三件套 |
| PlanSkill | generate_study_plan | 生成学习计划 |
| ReportSkill | write_markdown_report | 写入 Markdown 报告 |
| ValidateSkill | validate_report | 验证报告完整性 |
特别想说说 ValidateSkill 的设计——它检查报告是否包含四个必需章节(Question Answer / Evidence Sources / Study Plan / Summary),以及是否有未替换的模板占位符。这个自检机制非常实用,相当于给 Agent 加了一个“质检员”角色。
运行过程中发生了一件很有意思的事:Agent 第一次调用 validate_report 时,报告没有通过验证——缺少 Study Plan 部分。但 Agent 没有停下,而是自动修复了问题:重新写入完整报告,再次验证,最终通过。
这个“发现错误 → 自我修正”的闭环,让我真切感受到了 Agent 的自主性。

Agent 共完成了 12 次工具调用,最终生成的报告包含四个部分:问题回答、依据来源(引用了 course_intro.md、environment_guide.md、task_requirements.md、faq.md)、三天学习计划、总结。
今天的 Agent 实训让我对“大模型能做什么”有了全新的认识。从最初的“问答工具”到今天的“自主任务执行者”,Agent 架构打开了无限可能:
学到的核心概念:
四个任务的收获:
| 任务 | 核心能力 |
|---|---|
| 任务一 | 基础工具调用闭环 |
| 任务二 | 多 Skill 协作完成数据分析 |
| 任务三 | 批量任务处理与准确率统计 |
| 任务四 | 端到端知识库问答与自修复 |
Day1 配环境、Day2 跑微调、Day3 玩 Agent——三天下来,从“会用大模型”到“会让大模型做事”,感觉又上了一个台阶。
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。