设wordLength为单词长度,wordCount为单词数量。
看到了这题的标签滑动窗口,就想到了最朴素的方法。设windowSize = wordCount * wordLength,从头至尾移动窗口,检查窗口内的子串是否符合要求。

检查窗口内子串是否符合要求的做法是,使用Hash表,以单词为key,出现次数为value。例如第2个窗口“ordgoodgoodgoodb”,包含的单词为“ordg oodg oodg oodb”,对应表为“ordg:1, oodg:2, oodb:1”。同理把给定的words转换为Hash表,对比这两个表是否一致,一致则说明符合要求。代码如下:
C#
public class Solution
{
public IList<int> FindSubstring(string s, string[] words)
{
int wordLength = words[0].Length;
int wordCount = words.Length;
int windowSize = wordCount * wordLength;
if (s.Length < windowSize)
{
return [];
}
Dictionary<string, int> map = new();
foreach (string word in words)
{
if (!map.TryAdd(word, 1))
{
map[word] += 1;
}
}
List<int> result = [];
for (int i = 0; i < s.Length - windowSize + 1; i++)
{
bool isValid = true;
Dictionary<string, int> tempMap = new(map);
for (int j = 0; j < wordCount; j++)
{
string fragment = s[(i + j * wordLength)..(i + j * wordLength + wordLength)];
if (!tempMap.ContainsKey(fragment) || tempMap[fragment] == 0)
{
isValid = false;
break;
}
tempMap[fragment] -= 1;
}
if (isValid)
{
result.Add(i);
}
}
return result;
}
}但是时间复杂度太高了,虽然能过,但执行时间还是太长:

看了好多题解,都不是很明白,后来结合着想了想,优化了一下思路。上述解法是把滑动窗口瞄准了原始字符串,每次滑动只移动一个字符,但其实我们要判断的一个个的单词,移动一次窗口前后两个窗口之间并没有什么关联性,因此很难优化。若我们能每次窗口移动的是一个单词就好了,这样每次窗口移出去的是一个单词,新加入的也是一个单词,前后之间有重叠的部分,这样我们就可以进行优化了。
但是要怎么样确保移入移出的是一个单词呢?这里每个单词长度都是固定的,所以若考虑第1到wordLength个字符为一个单词、第wordLength+1到2*wordLength个字符为一个单词,依次类推,以上为一组划分;第2到wordLength+1个字符为一个单词、第wordLength+2到3*wordLength个字符为一个单词,依次类推,以上为一组划分……依次类推,一共可以分出wordLength组,如下图所示,每一行为一组划分:
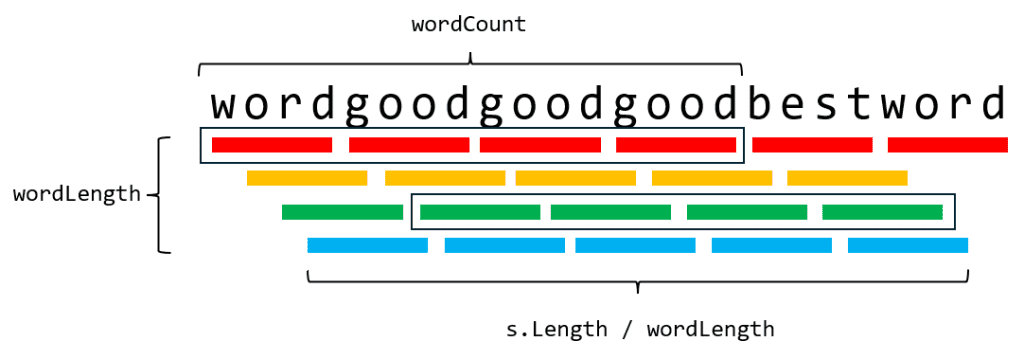
这样一来,我们对每一组内的单词做滑动窗口,此时windowSize即为wordCount,接着逐一判断每个窗口是否符合要求即可。而此时,就不需要每个窗口重新创建一个新的Hash表了,只需要沿用上一个窗口的表,将已经移除出去的单词从统计表里减一、新加入的单词加入统计表里即可。代码如下:
C#
public class Solution
{
public IList<int> FindSubstring(string s, string[] words)
{
int wordLength = words[0].Length;
int wordCount = words.Length;
if (s.Length < wordCount * wordLength)
{
return [];
}
Dictionary<string, int> map = new();
foreach (string word in words)
{
if (!map.TryAdd(word, 1))
{
map[word] += 1;
}
}
List<int> result = [];
for (int i = 0; i < wordLength; i++)
{
int k = 0;
Dictionary<string, int> tempMap = new(wordCount);
for (int j = 0; j < s.Length / wordLength; j++)
{
if (i + j * wordLength + wordLength > s.Length)
{
continue;
}
string fragment = s.Substring(i + j * wordLength, wordLength);
if (!tempMap.TryAdd(fragment, 1))
{
tempMap[fragment]++;
}
k++;
if (k == wordCount + 1)
{
k--;
string head = s.Substring(i + j * wordLength - k * wordLength, wordLength);
tempMap[head]--;
if (tempMap[head] == 0)
{
tempMap.Remove(head);
}
}
if (k == wordCount)
{
bool isValid = true;
foreach (string key in map.Keys)
{
if (!tempMap.ContainsKey(key) || map[key] != tempMap[key])
{
isValid = false;
break;
}
}
if (isValid)
{
result.Add(i + (j - k + 1) * wordLength);
}
}
}
}
return result;
}
}执行用时大大减少:

此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。