for (i = 0; i < sz; i += PGSIZE) { if ((pte = walk(old, i, 0)) == 0) { panic("uvmcopy: pte should exist"); } if ((*pte & PTE_V) == 0) { panic("uvmcopy: page not present"); }
pa = PTE2PA(*pte); if (*pte & PTE_W) { *pte &= ~PTE_W; *pte |= PTE_COW; } cowcount(pa, 1); flags = PTE_FLAGS(*pte); if (mappages(new, i, PGSIZE, (uint64)pa, flags) != 0) { kfree((void *)pa); goto err; } } return0;
err: uvmunmap(new, 0, i / PGSIZE, 1); return-1; }
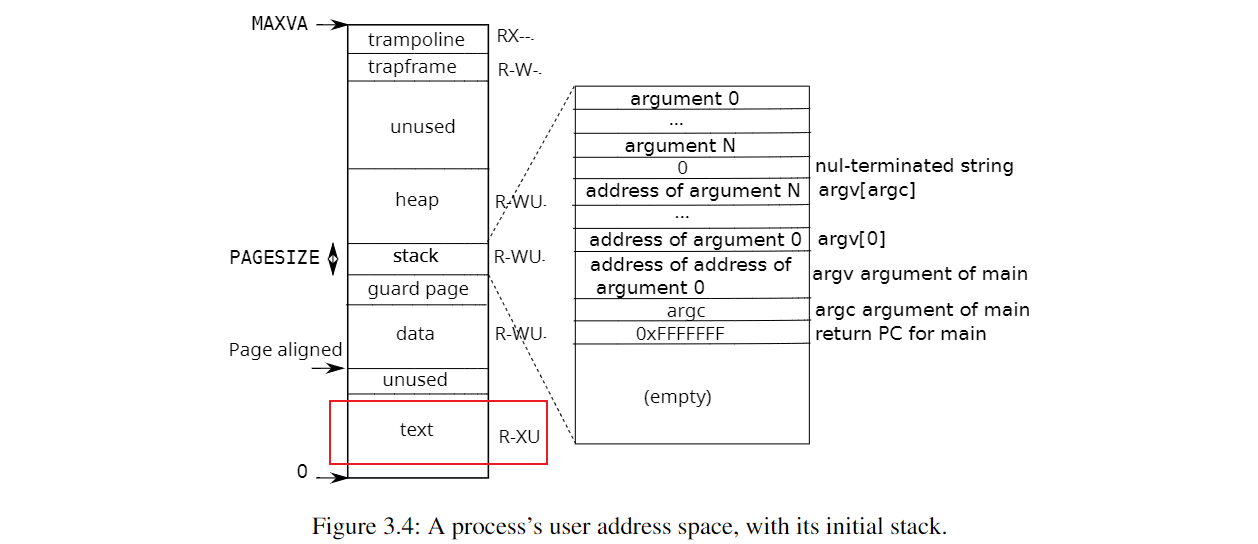
值得注意的是,Lab 的单元测试中会涉及到对 text segment 的修改。而参考 xv6 的进程内存模型,可以看到 text segment 属于只读,如果对它加上 PTE_COW 标志,则在单元测试中会报错,所以只修改可写页,为其加上 PTE_COW 标志。
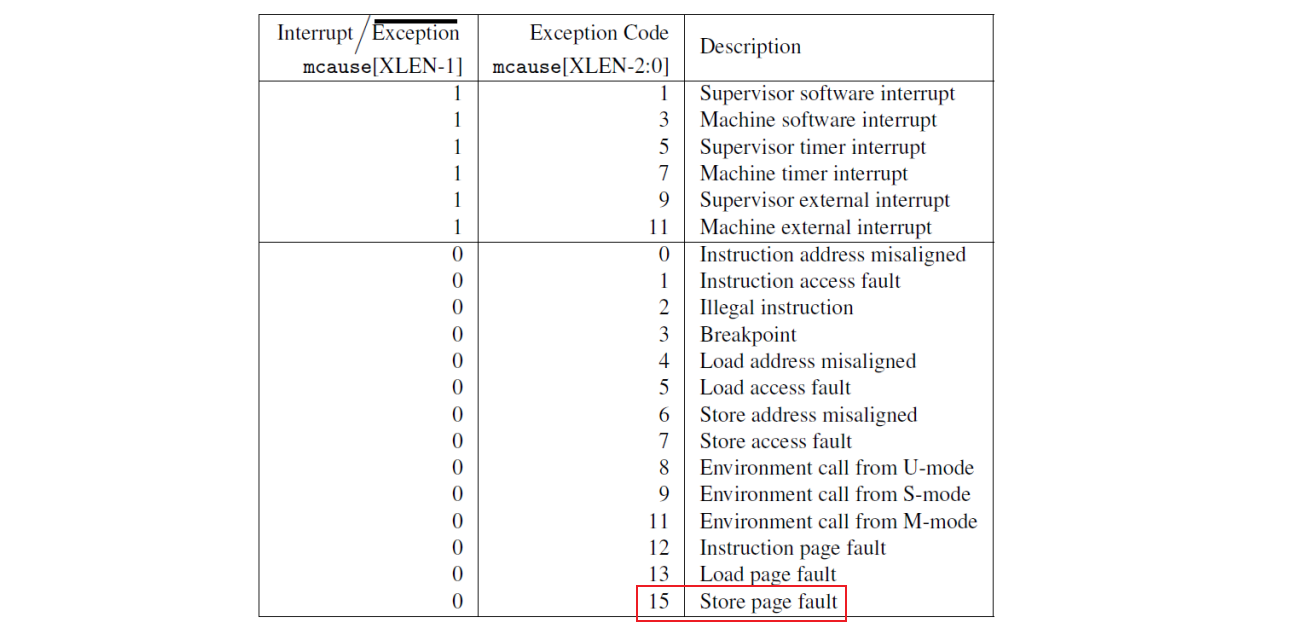
首先需要在 usertrap() 中捕获 Store page fault,通过 r_scause() 读取 scause 寄存器,获取状态码,15 表示 Store page fault,其他状态码如图所示。并通过 r_stval() 获取发生 Store page fault 错误的虚拟地址。然后会调用 writecowpage() 来处理 COW 页,如果返回值为 -1 时,将当前进程杀死。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
voidusertrap(void) { if (r_scause() == 8) { } elseif (r_scause() == 15) { uint64 va = r_stval();
if (va > p->sz) { printf("Error: The virtual address greater then this process's size\n"); p->killed = 1; } elseif (writecowpage(p->pagetable, va) != 0) { printf("Error: This page is not a cow-page or xv6 don't have enouth page, so not allow to write\n"); p->killed = 1; } } }
intwritecowpage(pagetable_t pagetable, uint64 va) { va = PGROUNDDOWN(va); pte_t *pte = walk(pagetable, va, 0); if (pte == 0) { panic("COW: fail to get pte"); }
uint flags = PTE_FLAGS(*pte); if (!(flags & PTE_COW)) { printf("COW: This page from %p is not a cow page\n", va); return-1; }
uint64 pa = PTE2PA(*pte); if (cowcount(pa, 0) > 1) { char *mem = 0; flags |= PTE_W; flags &= ~PTE_COW;
if ((mem = kalloc()) == 0) { printf("COW: fail to kalloc, kill current process\n"); return-1; }
memmove(mem, (char *)pa, PGSIZE); uvmunmap(pagetable, va, 1, 1); if (mappages(pagetable, va, PGSIZE, (uint64)mem, flags) != 0) { printf("COW: fail to mappages\n"); kfree(mem); return-1; } } else { *pte |= PTE_W; *pte &= ~PTE_COW; }