智能座舱正在经历一场从云端到本地的技术革命,如何在实现个性化服务的同时守护用户隐私,成为行业核心命题。本文将深度解析端侧优先架构的四大技术支撑,揭秘如何通过本地SLM、联邦学习与多模态融合,打造真正懂人却不越界的智能座舱体验。

智能座舱的下半场,大家都在谈“懂人”。
但有一个行业悖论始终绕不开:AI 要想懂你,就得窥探你。过去那种“把数据传到云端做匹配”的逻辑,本质上是把用户的隐私当成燃料。
但如果你的个性化是建立在“窃听”和“云端裸奔”的基础上,那不叫智能,叫冒犯。
要实现“真·定制”且守住隐私,产品架构必须完成从 Cloud-Native 到Edge-First(端侧优先)的转型。
在深入讨论逻辑前,我们需要理解支撑这一变革的四大硬核技术:

过去座舱所谓的“个性化”大多是基于静态标签:你是“都市白领”,所以给你推爵士乐。这种逻辑极其粗放,因为它忽略了驾驶是一个高频、高隐私、强实时的流动场景。
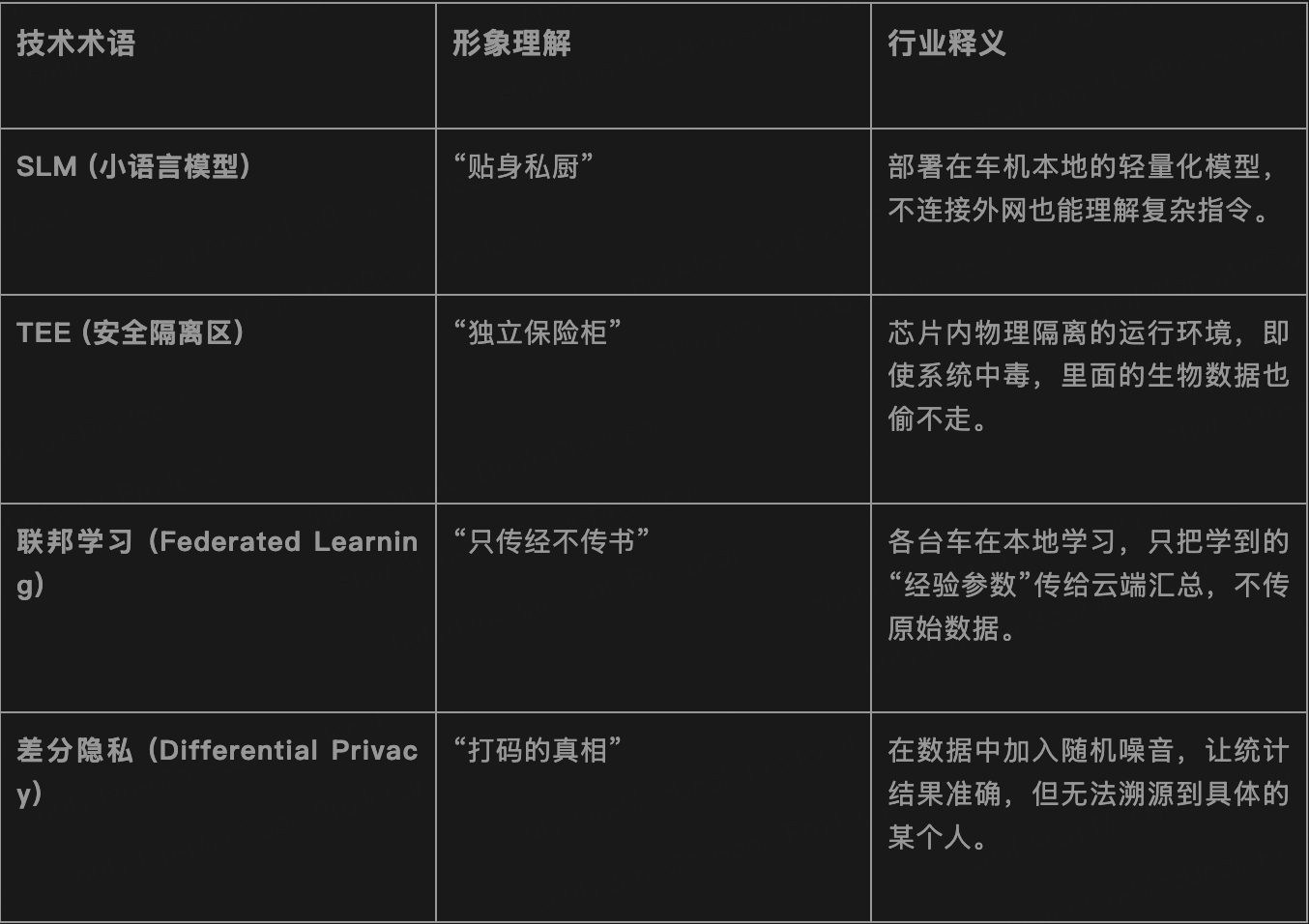
真正的个性化不应产生于云端数据库的匹配,而应产生于座舱内多模态感知流(Perception Stream)的本地实时推理。
借助高算力 NPU,我们将 7B 或更小参数规模的 SLM 部署在车机本地。
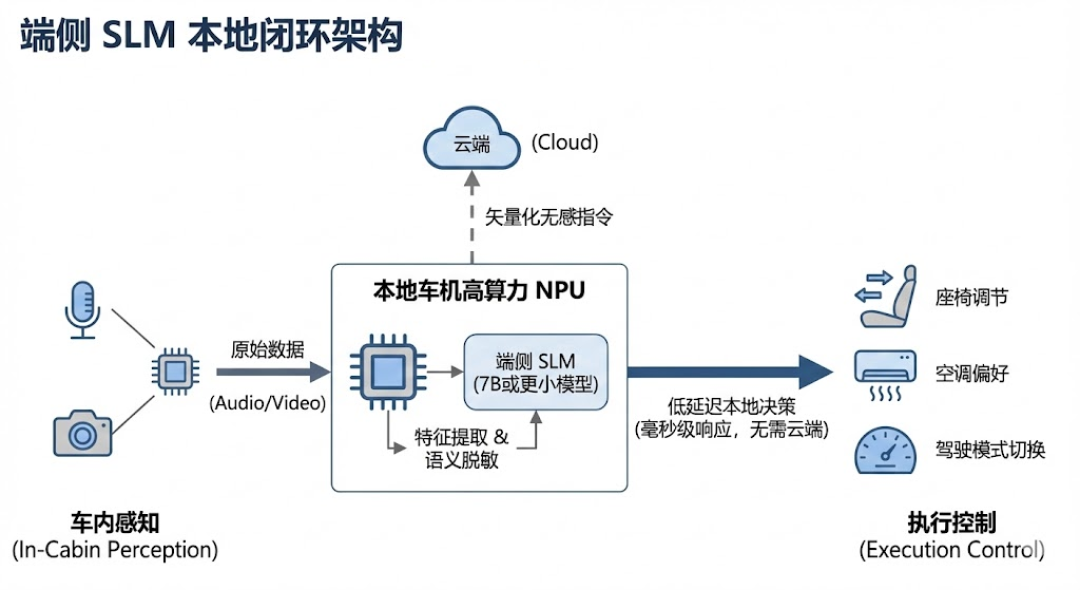
这是解决“个人偏好”与“群体进化”矛盾的关键。
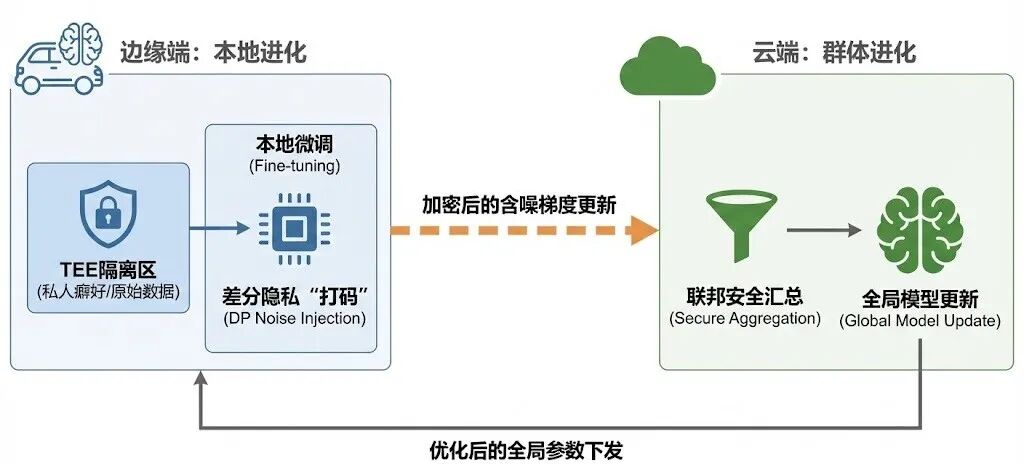
当端侧模型具备了多模态处理能力,个性化将进入“情境感知”阶段:
作为一线实践者,我们必须警惕“过度智能化”。在算力分配上,我坚持以下优先级:

“千人千面”不是靠云端喂数据喂出来的,而是靠端侧算力磨出来的。隐私不是功能的对立面,而是高级智能的标配。当我们把推理权还给车辆本地,个性化才真正从“营销噱头”转变为“私人管家”。
本文由 @OpenAIer 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。