DeepSeek团队在推特上发布了一篇新的论文,是解决模型在处理长上下文窗口的能力。马斯克的Grok3模型也在前几天发布了;这篇文章,我们就来看看作者对论文的分析,以及对几个产品的分析与见解。

最近(2025 年 2 月)DeepSeek团队在推特上发布了一篇新的论文,这个论文解决的是模型在处理长上下文窗口的能力。曾经谷歌发布过一个论文叫做 《Attention is all you need 》这个Attention 叫做注意力机制,在大模型的处理中,是一个非常关键的技术,就像你读一本书,你需要全都读下来,每个字都要看一遍,之前的注意力机制叫做 full attention 就是你需要关注到每个字和每个字之间的相互关系。但是这次deepseek 的NSA 原生稀疏注意力机制,它会想一些办法去略读,它不需要关注这篇文章所有词之间的相关关系,而是只要把其中重要的一些,把它看到就好了。
下面让我们仔细来看看这篇论文
论文提出了一种原生稀疏注意力机制(NSA),它将算法创新与硬件对齐优化相结合,以实现高效的长上下文模型。
1、NSA 采用动态分层稀疏策略,结合粗粒度标记压缩和细粒度标记选择,以保持全局上下文意识和局部精度。这样既有对全局的理解也能减少冗余的计算。
2、对 GPU 的 Tensor Core 特性设计高效的计算内核,让NSA 在 64k 长度序列的解码、正向传播和反向传播方面相对于全注意力( full attention)实现了显著的加速,验证了其在整个模型生命周期中的效率。
3、实现了端到端训练,在不牺牲模型性能的情况下减少了预训练的计算。实验表明,使用 NSA 预训练的模型在通用理解、长上下文任务和基于指令的推理方面保持了或超过了全注意力( full attention)模型。同时,大幅降低算力成本。
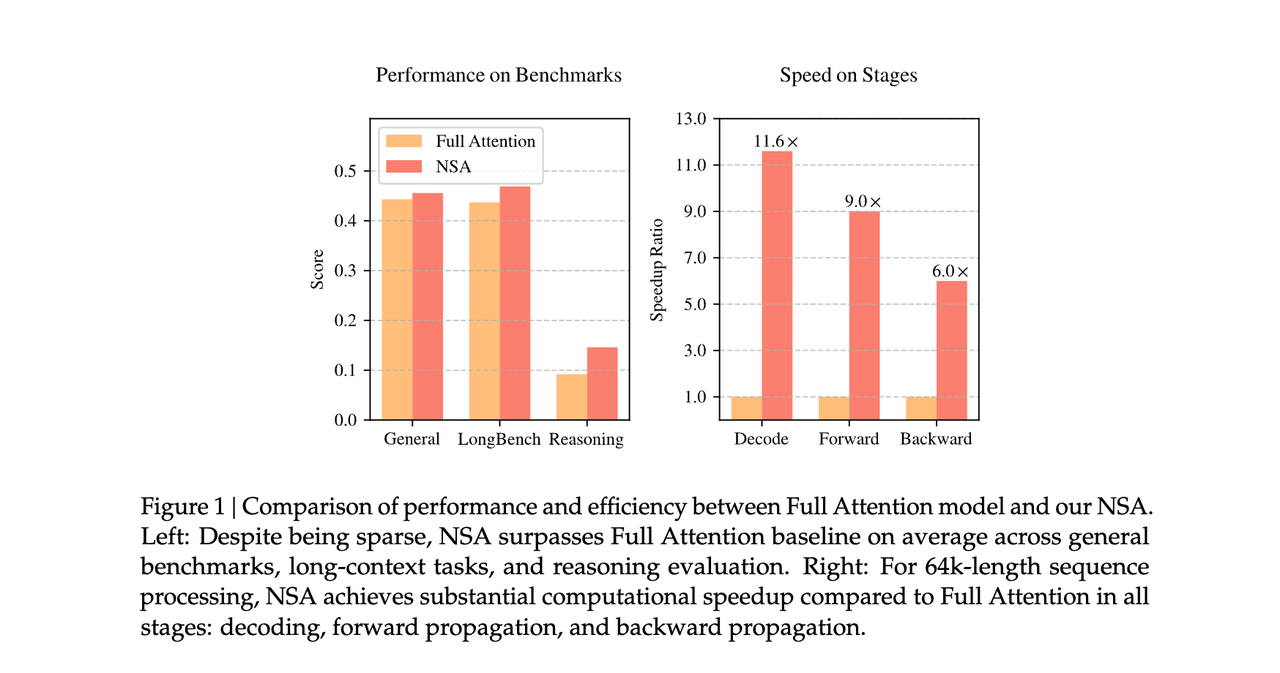
NSA 的核心在于其动态层次化的稀疏策略,具体包括以下几个方面:
1、令牌压缩(Token Compression):通过将连续的键(key)或值(value)序列聚合为块级表示,减少计算负担。压缩后的键和值能够捕获整个块的信息,从而实现粗粒度的语义信息捕获。(简单来说就是:它把所有的token都切成块,每块提炼出一些关键信息,相当于做了一个摘要)
2、令牌选择(Token Selection):在压缩的基础上,选择性地保留一些关键的键和值,以保留重要的细粒度信息。这一过程通过块级选择策略实现,即对键和值序列进行空间连续的块划分,并根据块的重要性分数选择最重要的块。(简单来说就是:选择这些块里面,这些关键信息里,一些重要的词的意思。就像这些块里面的内容,我并不是都需要,所以我会选择一些关键词,或者是跳过一些不太重要的词)
3、滑动窗口(Sliding Window):为了处理局部上下文信息,NSA 引入了滑动窗口机制,专门处理局部模式,使模型能够更有效地学习全局和局部特征。(简单来说就是:刚才切的这些块之间可能还会有一些关联)

大概就是通过这样一个算法,让大模型产生一个稀疏注意力,这样的话,它不需要关注全局所有词之间的相关关系,而是只要把其中重要的一些找到就好了。
deepseek团队用这样的方法去做了测评,甚至评测出的结果甚至比全注意力( full attention)还要好,而且它的计算的能耗压缩是非常显著的,在这个全流程的过程当中,节省的成本不只是一点半点
同时他们不但在算法上有优化,还在硬件上也有优化,硬件也能让效能有所提升。当然硬件也不是说在英伟达的卡上面做优化。
NSA 通过其层次化的稀疏注意力设计,在保持全注意力模型性能的同时,实现了显著的计算效率提升。具体来说:
Grok3是由埃隆·马斯克旗下的xAI公司开发的第三代大语言模型,于2025年2月17日正式发布。Grok3 目前有最大的算力集群,它是用20万块H100来训练出来的大模型,它的进展速度是非常快的,在非常的时间内,就提升到了鼻尖 OpenAI 01 03等等这些模型的水平,甚至在这个数学,编程能力方面是有超越的。
但是 Grok3 在算力的消耗方面、成本方面都是是非常巨大的,是deepseek v1的 263倍。所以巨大的算力是Grok3的一个典型的特征,在发布会中,也提到了多模态的能力,也结合了应用作了一些优化,目前Grok3最大的这个模型还在训练中。接下来还会有更多的测评出来。
以下是其主要特点和功能:
1、训练与硬件
2、核心功能
3、性能表现
Grok3以其强大的推理能力、多模态处理能力和卓越的性能表现,展现了在人工智能领域的巨大潜力和创新。
DeepSeek和Grok3在多个方面存在显著差异。
此外,DeepSeek在中文语义理解准确率上超过Grok3,而Grok3则在多模态处理方面更具优势,支持图像、视频和3D建模分析。
两个对比过后,Grok3靠大算力产生更好的智能,而deepseek 仍然在开源这条路上探索,所以究竟哪个更好,我想每个人心中都会有自己的答案吧。
本文由 @贝琳_belin 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。