简单介绍一下项目需求: 项目组需要对外发布文档,文档撰写使用的是Markdown,对外需要使用HTML。起初,使用的是Nginx+Jekyll的解决方案。随着文档的增加,文档系统对搜索功能有了强烈的需求。笔者在另外一篇文章中有所讨论,但是这几种方案,有的搜索效果不理想,有的需要依赖其他服务,显得有些重。于是,便有了本文的实施方案。
1. 工具介绍
- Whoosh是一个纯Python实现的全文搜索组件。Whoosh不但功能完善,而且速度很快。
- Haystack是一个第三方的Django app,提供全文检索功能。可以对Model里面的内容进行索引、搜索。同时,Django-haystack支持Whoosh、Solr、Xapian、Elasticsearc四种全文检索引擎后端,实质上是一种全文检索的框架,使用时可以自由选择搭配。
- Jieba是一个Python中文分词组件,其包含多种功能,本文使用了其中的ChineseAnalyzer中文分词功能。
2. 设计方案
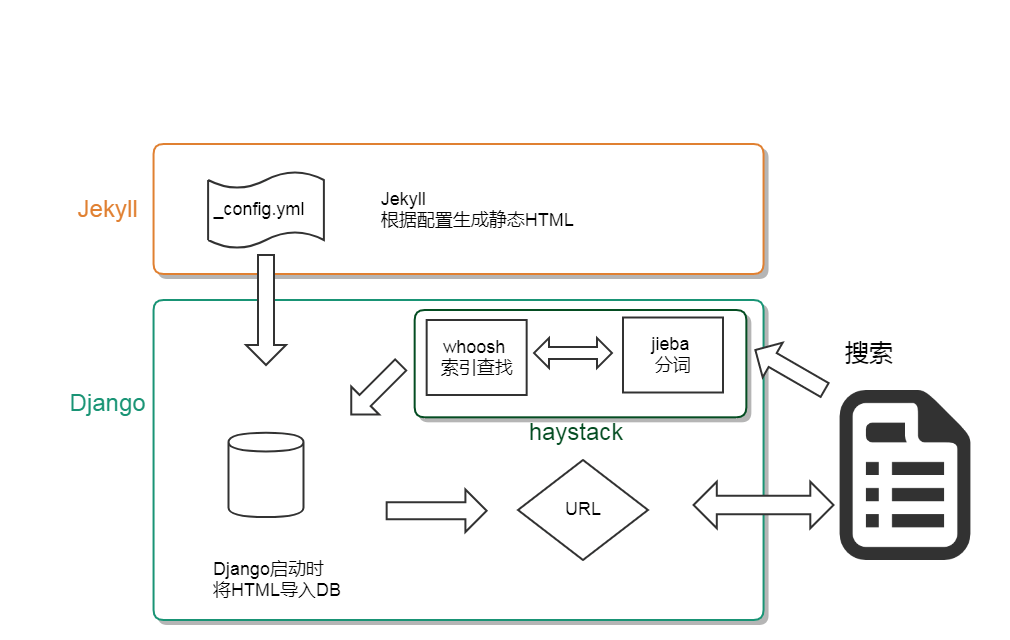
方案思路
- 1.将Jekyll作为Markdown转HTML的工具,最终得到本地所见即所得的HTML文档
- 2.使用Python爬虫工具BeautifulSoup,将静态的HTML解析后导入DB
- 3.通过Jieba分词,利用Whoosh建立查询索引
- 4.直接通过Django匹配.html的URL,从数据库中获取数据,对外提供文档服务,可以确保Nginx+Jekyll方案的链接依然有效。
3. 实施方案
3.1 创建文档 app
在项目目录,创建一个 Django app,命名:document。文档系统为两级目录结构,第一级为分类,第二级为文档。
例如:
- doc/type1/aaa.html
- doc/type2/bbb.html
document/models.py
| |
3.2 读取HTML
这里利用BeautifulSoup对HTML文件中的内容,进行了简单的筛选。是为了剔除导航部分的文本内容,增加搜索匹配的准确度。文档内容被markdown-body类包裹,标题被bk-title-style detail-title-right类包裹。
document/utils.py
| |
3.3 安装配置haystack
- 安装依赖包
| |
- 配置索引
document/search_indexes.py,文件名一定要为search_indexes.py
| |
- 配置搜索引擎
拷贝haystack/backends/whoosh_backend.py,重命名为document/whoosh_cn_backend。将分词器改为jieba,默认的分词器对中文支持不友好。
仅需要将原来的import StemmingAnalyzer,替换为jieba的ChineseAnalyzer即可。
| |
- settings.py配置
| |
- 生成索引
| |
执行命令后,settings.py同目录下,生成文件夹whoosh_index,包含索引信息。
- 变更时,自动更新索引
settings.py中配置
| |
4. Django中使用
4.1 使用haystack默认路由
- 配置urls.py
| |
- 在模板目录,新增查询相关字段配置、模板
template/search/search.html,模板文件
| |
template/search/indexes/document/document_text.txt,查询字段配置
注意这里的子目录indexes,文件夹名是约定的,必须按照这样的格式。第一个document为Django app名,第二个document为Model表名,后缀_text。文本中,配置建立索引的字段。
| |
4.2 自定义View API
haystack也提供了,查询函数用于获取匹配的Model对象。
| |
