本番環境で vision model を選ぶとき、「画像に対応しているか」だけでは不十分です。実際の開発者が必要としているのは、ユーザーの画像アップロード、スクリーンショット、UI デバッグ、ロゴ検出、文書プレビュー、サポートチケット、そして OpenAI-compatible API 経由で視覚情報を扱う agent workflow で安定して動くルートです。
この記事では qwen3-vl-flash と gpt-4.1-mini を Crazyrouter OpenAI-compatible Base URL 経由で比較します。
リクエスト形式は chat/completions で、messages[].content[] にテキストと image_url を入れています。各モデルは Python logo と GitHub logo の 2 つの安定した公開画像でテストし、各画像につき 3 回実行しました。
テスト時刻:
2026-06-21T13:36:32Z。これは model card の転載ではなく、実際の API 測定結果です。

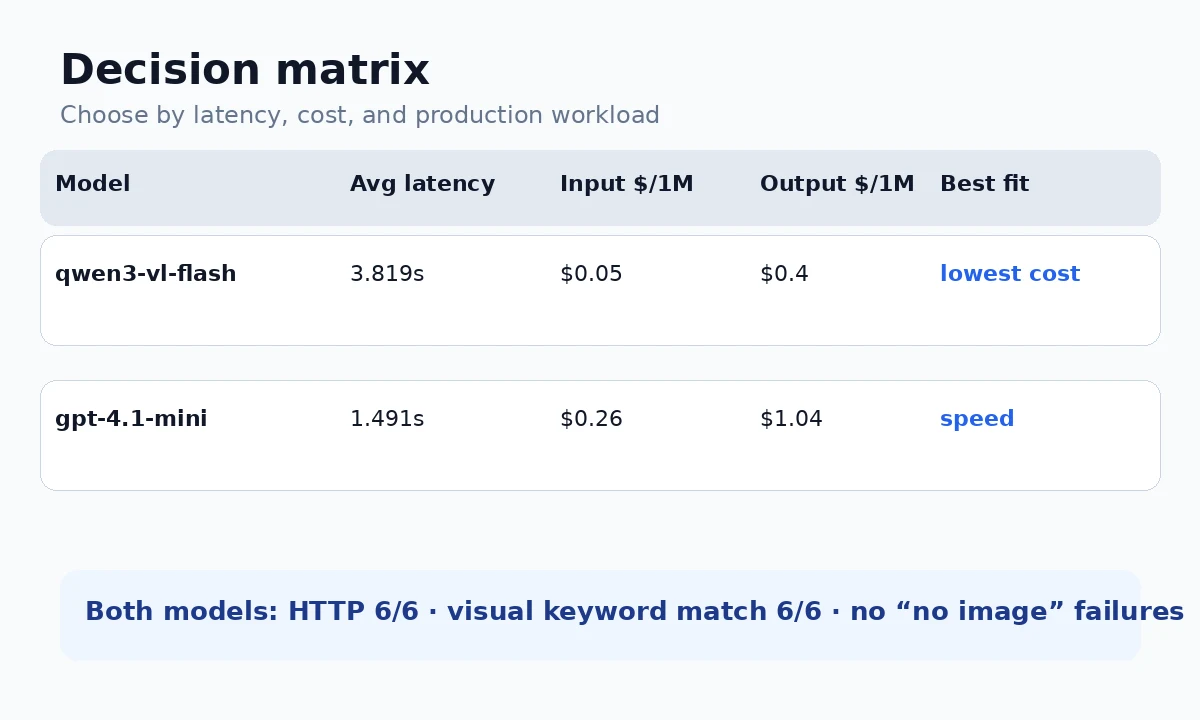
gpt-4.1-mini を優先候補にできます。qwen3-vl-flash が有利です。| 判断軸 | qwen3-vl-flash | gpt-4.1-mini | なぜ重要か |
|---|---|---|---|
| HTTP success | 6/6 | 6/6 | 通信成功を示すだけで、モデルが画像を見た証明にはならない。 |
| 正しい画像認識 | 6/6 | 6/6 | image_url routing の最重要 smoke-test 指標。 |
| No-image failure claims | 0 | 0 | リクエストは通ったが画像が渡っていない経路を検出できる。 |
| Average latency | 3.819s | 1.491s | ユーザーが通常どれくらい待つかに直結する。 |
| Median latency | 3.493s | 1.292s | 平均よりも典型的な体験を表しやすい。 |
| Slowest request | 5.975s | 2.189s | tail latency は「固まった」と感じる原因になる。 |
| Input price / 1M tokens | $0.05 | $0.26 | image tagging、OCR pre-filtering、batch classification で重要。 |
| Output price / 1M tokens | $0.4 | $1.04 | 長めの画像説明を出す場合に効く。 |
| Estimated cost / 10k test-style calls | $0.0915 | $0.5226 | raw token price より実践的。観測された usage を含めている。 |
| Usage / image signal | usage metadata に image tokens の明示的なシグナルあり | image tokens が 0 または欠落。HTTP status だけでなく vision smoke test が必要 | usage metadata は HTTP 200 でも壊れた vision path を示すことがある。 |
これは意図的に vision API smoke test として設計しています。判断できるのは次のような点です。
image_url が動くか一方で、これは OCR、chart reasoning、手書き文字、医療画像、密な文書抽出、multi-image reasoning の完全評価ではありません。そのような workflow では、このテストを最初の routing check として使い、別途 domain-specific evaluation を追加してください。
| 指標 | qwen3-vl-flash | gpt-4.1-mini |
|---|---|---|
| HTTP success | 6/6 | 6/6 |
| Correct recognition | 6/6 | 6/6 |
| No-image replies | 0 | 0 |
| Average latency | 3.819s | 1.491s |
| Median latency | 3.493s | 1.292s |
| Fastest request | 2.529s | 1.239s |
| Slowest request | 5.975s | 2.189s |
| Avg prompt tokens observed | 111.0 | 159.0 |
| Avg completion tokens observed | 9.0 | 10.5 |
| タスク | モデル | 出力例 | レイテンシ | Prompt tokens |
|---|---|---|---|---|
logo_python | qwen3-vl-flash | Python programming language logo. | 3.217s | 111 |
logo_python | gpt-4.1-mini | Python programming language official logo with two snakes. | 1.69s | 159 |
logo_github | qwen3-vl-flash | GitHub logo: cat head with ears and whiskers. | 4.243s | 111 |
logo_github | gpt-4.1-mini | GitHub's black cat silhouette logo inside a circle. | 1.239s | 159 |
チャットアプリ、カスタマーサポート、ユーザー画像アップロードでは latency と reliability が最重要です。安いモデルでも、ユーザーが再試行したり、毎回 fallback が発生したりするなら、結果的に安くありません。
大量分類では、成功画像あたりのコストが重要です。タスクが単純で、回答形式を検証できるなら低コストルートを使い、empty answer、no-image claim、low-confidence classification のときだけ fallback します。
この benchmark は OCR quality を証明するものではありません。請求書、表、フォーム、レシート、テキスト量の多いスクリーンショットでは、実データで別の評価が必要です。ロゴを認識できるモデルが layout extraction に強いとは限りません。
Agent は入力の安定性を必要とします。HTTP 200 でも image content が落ちるルートでは、agent が自信を持って間違った判断をする可能性があります。Agent 用途では answer correctness、usage signals、疑わしい image path で fail closed する設計が必要です。
image_url support には複数の意味があります。クライアントから URL を受け取れるだけなのか、gateway が media を取得して変換するのか、upstream provider に元の URL を渡すのか。これは bandwidth、privacy、SSRF controls、latency、billing に影響します。Media behavior は model routing の一部として扱うべきです。
有効な HTTP response は、API が何かを返したことを示すだけです。画像がモデルに届いた証明にはなりません。Vision API monitoring では、小さな deterministic test image を送り、答えが決まっている質問をして、テキスト回答と usage metadata の両方を確認してください。
特に usage 上で image tokens が見えない場合や、モデルが「画像が提供されていない」と答える場合は注意が必要です。それはモデル品質の問題ではなく、adapter、media-fetch、payload conversion、routing の問題かもしれません。
コード内の API endpoint に UTM パラメータは付けません。人がクリックするリンクには UTM を付けられます。例:Crazyrouter Pricing。
最適な Vision API route は workflow によって変わります。リアルタイム対話では正しい認識と低 latency。大量分類では cost per successful image。Agent や document workflow では reliability、usage signals、fallback design が重要です。
つまり、vision model は名前だけで選ぶべきではありません。タスク、failure mode、media path、latency、そして有用な結果あたりのコストで選ぶべきです。
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。