你的公司最近上线了一个内部全能搜索系统,这是一个单体系统,采用检索增强生成(RAG)技术构建,可检索公司的待办事项、设计文档、发布文档、运维手册和纠错文档(COE)。工程师、产品经理和经理通过基于大语言模型的聊天界面进行查询,各团队还将其封装为 MCP 工具,让他们的 AI 编程助手可以直接获取上下文。
然后,生产支持组的一名值班人员输入:”在生产环境中启用 payment_v2_enforce 功能标志的运维手册“,聊天助手却提示应禁用该功能。在系统内部,文档根据嵌入相似度进行排名。
对于嵌入模型来说,这两份运维手册看起来几乎完全相同。它们有相同的功能标志名称、相同的服务、相同的词汇和相似的上下文。但值班工程师看不到这个排名,他们看到的是聊天助手根据检索器返回的前 K 条内容生成的回答(有时正确的运维手册甚至不在前 K 个结果里)。这类回答轻则信息失真,重则看似笃定却完全错误。
如果你构建过基于嵌入的搜索系统,对这类情况想必并不陌生。系统能把握整体方向,却忽略了关键的细节信息。
上述查询需要两样东西:对”功能标志运维手册“的语义理解,以及对操作(启用与禁用)的精确匹配。向量搜索只处理了前者。
这并非嵌入模型的缺陷,而是向量相似度的固有特性。嵌入机制会检索出和查询内容相似的结果,而非完全匹配的内容。由于检索将前 K 个结果作为上下文输入大语言模型,排名与召回同样重要。
即便正确答案在前 K 条结果里,若错误答案排序更靠前,依然无法解决问题。修复方案并不是要替换嵌入技术,而是将其与传统文本关键词匹配相结合,让概念相关性和精准术语匹配共同作用于最终的排序。
想要理解为什么会出现这个问题,不妨放眼审视一下完整的流程。如图 1 所示,RAG 流程共分为三个阶段。
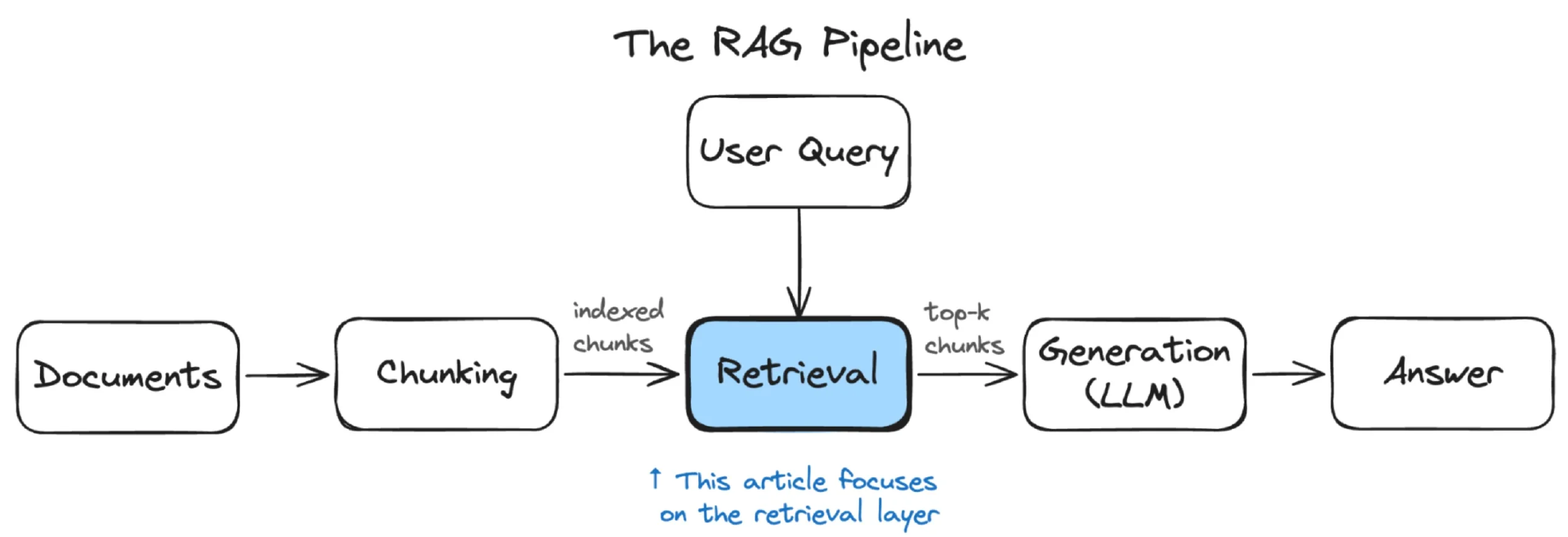
图 1. 典型的 RAG 管道有三个阶段:分块、检索和生成。(来源:作者创建)
图 1 中的元素定义如下:
分块:将原始语料库拆分为可用于索引的单元。
检索:接收用户查询,在分块内容中检索并返回相关性最高的前 K 个块。
生成:将这些分块内容作为上下文输入大语言模型,由模型生成答案。
假设第一、第三阶段均正常运行:文档按合理边界完成拆分,大语言模型根据提供的上下文生成答案,且不会产生幻觉。问题出在前文提及的检索阶段。检索器先对查询做嵌入处理,再将其与已建立索引的文档向量比对,返回嵌入空间距离最近的文档。嵌入空间距离相近,表示语义相似,而非内容完全一致。针对同一功能标志的两份运维手册,一份说明启用操作、一份说明禁用操作,二者在嵌入空间中距离极近。两份文本仅个别词汇存在差异,嵌入模型会为这类高度相似的文本生成近乎一致的向量,导致检索器难以精准区分。因此,当用户查询启用功能标志的运维手册时,禁用相关的手册有时反而距离更近,检索器会以同等置信度推送这份错误文档。这便是问题所在:依靠同一向量空间与评分机制,最终排在前面的却是错误的文档。
像 BERT 这样的嵌入模型将文本转换为固定维度的数值向量,并捕捉文本的语义信息。语义相似的文本生成相似的向量。”功能标志“、”终止开关“、”发布门“和”配置切换“在向量空间中紧密聚集。这种聚类在用户检索相关概念时能发挥很大作用,但当用户需要查找精确实体、特定功能标志名称、特定错误代码或特定部署版本时,问题就转到了检索精度层面。
相似的表现同样存在于各类不同失效模式中。当某人搜索 ERR_PAYMENT_GATEWAY_TIMEOUT 时,相关代码如 ERR_PAYMENT_GATEWAY_REJECTED 和 ERR_PAYMENT_GATEWAY_UNAUTHORIZED 等相关代码最终都会与查询向量趋近,因为它们有相同的 ERR_PAYMENT_GATEWAY 前缀并出现在同类故障排查文档中。区分它们尾部词汇的权重占比很低。嵌入模型的行为完全符合设计初衷,它的作用是检索相似内容,而非精准匹配完全一致的内容。当区分特征在文本中占比过低时,嵌入会抹平这种区别。
图 2 展示了嵌入空间的特征:语义相近的内容会聚集在一起。在同一个聚类内部,想要区分不同具体实体(比如介绍功能标志启用、禁用操作的运维手册)就会变得困难。而混合搜索,正是为了解决这类精度不足的问题。
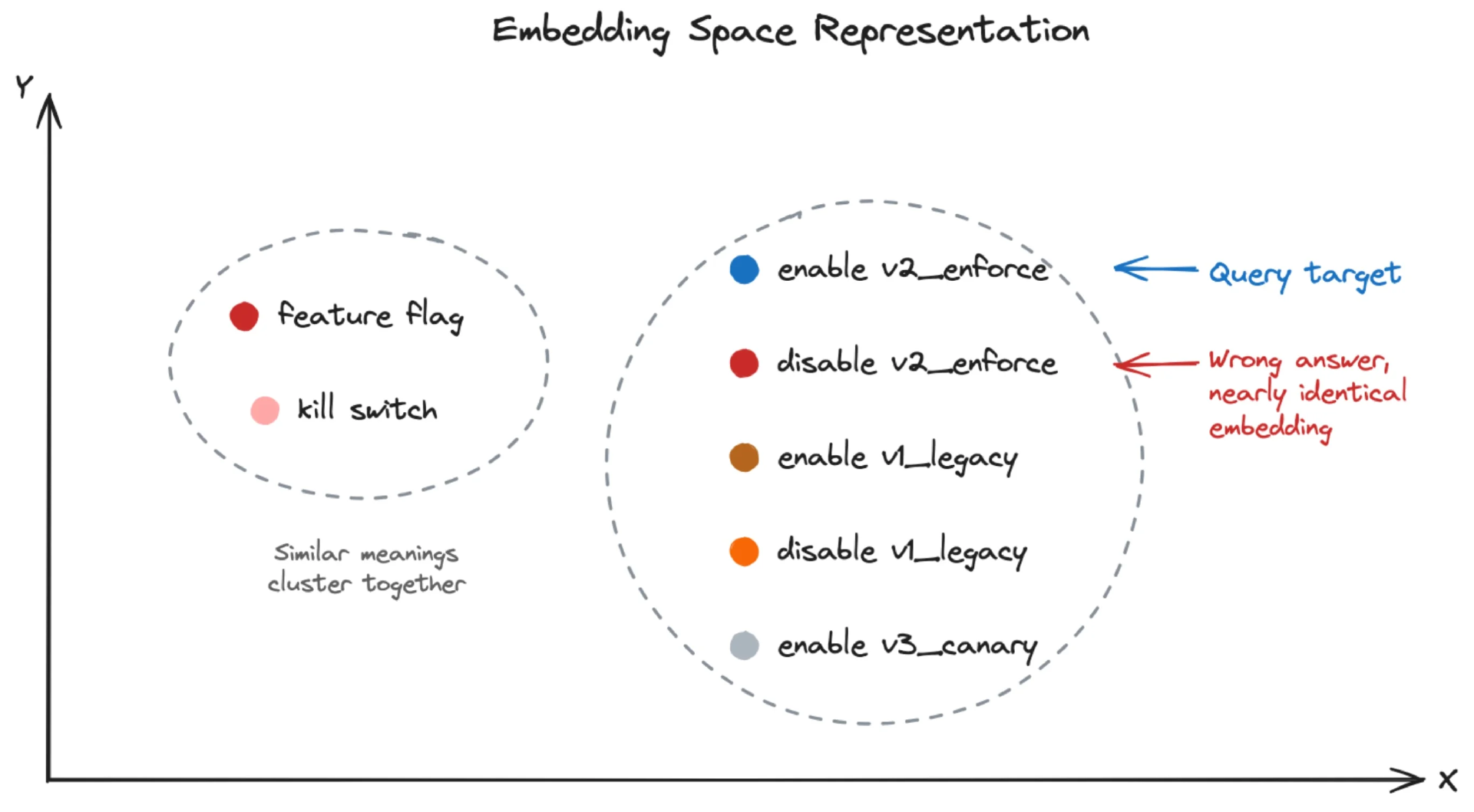
图 2. 语义相似的项目聚集在一起。并非每个查询都有相同的问题。(来源:作者创建)
根据检索方法的适用程度,搜索查询可以被分为三种类型。
用户的提问“当一个区域离线时,我们的协议是什么?”是概念类查询。标题为“灾难恢复架构”、“主主复制策略”、“故障转移运维手册”的文档,即便和查询没有共用词汇,也理应获得较高排名。嵌入模型能很好地应对这类场景,因为它捕捉的是语义,而非单纯匹配字面词汇。
这类查询在信息检索文献中也称为词汇查询。用户将堆栈跟踪或日志中的错误代码粘贴到搜索栏中,如 ERR_PAYMENT_GATEWAY_TIMEOUT,此时他们明确知晓自己要查找的标识。对于这些查询,语义相似性反而不是用户想要的。向量嵌入可能会推送语义相近但标识不同的文档(如包含 ERR_PAYMENT_GATEWAY_REJECTED 而非 TIMEOUT 的运维手册),影响了检索效果。关键词搜索则能高效、准确地处理这类查询。
用户搜索 “v3.2 部署的回滚运维手册”时,既需要语义理解(即部署回滚相关的运维手册),也需要对区分标识做精确匹配:根据 “v3.2” 筛选对应版本,根据 “rollback” 区分 “rollout”。用户搜索 “Outlook 2019 同步错误 0x80004005 故障排除”,则需要对问题症状做语义匹配,同时精确匹配版本号和错误代码。这类查询同时依赖两种能力。结合我在生产级 RAG 系统的实践经验,这类查询占绝大多数。本文后续内容将围绕这类查询的处理方案展开。
向量搜索需要一个搭档,这个搭档就是 BM25 —— 经典信息检索领域核心的概率排名函数。它是 Elasticsearch、OpenSearch 和大多数词汇搜索引擎的默认评分器,也是三十多年来占据主导地位的关键词搜索算法。在向量搜索效果不佳的场景中,它总能精准发挥作用。它基于概率信息检索理论,提供了三个直接解决精确匹配问题的内置机制。
逆文档频率(IDF)用于衡量一个词在整个语料库中的稀有程度。常见词如 “service” 或 “deployment” 权重较低,而稀有的区分性标记如 “v3.2”、“ERR_PAYMENT_GATEWAY_TIMEOUT” 或 “payment_v2_enforce” 权重较高。这也是 BM25 在精确匹配查询中优于嵌入技术的原因。能够区分不同文档的稀有标识在 BM25 中会被赋予最高权重。
词频(TF)饱和用于控制重复术语带来的影响。术语的首次出现会显著影响得分,后续重复出现带来的增益则逐步递减。得分会趋近于一个上限,而非线性增长。这一特性能够避免文档依靠关键词堆砌来刻意操纵排名。
长度归一化用于解决文本检索中的另一种偏差。较长的文档仅仅因为包含更多词汇而倾向于获得更高分数,匹配查询术语的概率也更高。长度归一化通过在计算相关性得分时综合考虑文档长度来纠正这个问题,不仅会统计术语出现的次数,还会考虑相对于文档长度的频率。这一点在具有可变长度分块的 RAG 系统中尤为重要,如果没有这种调整,较大的分块始终会胜过较小的分块。
如图 3 所示,混合检索会并行执行 BM25 检索与向量检索,通过 RRF 融合两者的排序列表;在将前 K 个文本块输入大语言模型前,还可选用交叉编码器做二次重排序。
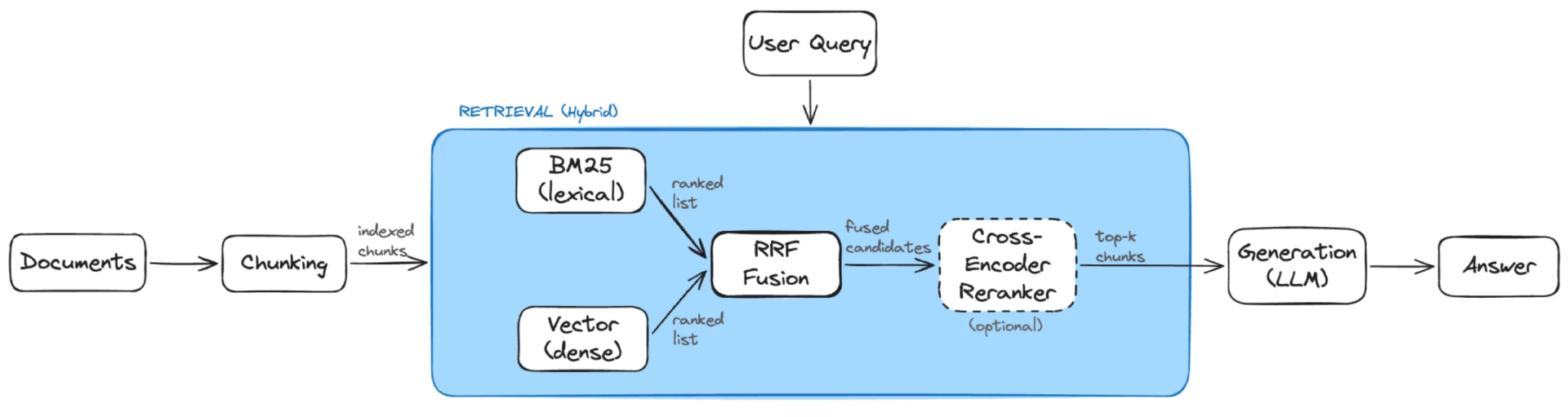
图 3. 混合检索(来源:作者创建)
现在我们有两个具有互补优势的检索器:向量搜索和 BM25。向量搜索捕捉语义信息,而 BM25 进行精准的词项匹配。每个产生自己的排名列表,要进行混合查询,这两个列表需要合并为一个。
合并列表是一个难点。向量余弦相似度介于 -1 和 1 之间,而 BM25 得分没有上下限,很难将它们归一化到同一量纲。权重适配会随查询内容变化:对于某一个查询,BM25 的合适权重可能是 0.7,但对于另一个可能是 0.3。在生产环境中为每个查询校准权重是不切实际的,而这正是倒数排名融合(RRF)发挥作用的地方。
RRF 直接舍弃两个检索器的原始分数,绕过了归一化难题。它仅基于排名位置完成运算:
RRF_Score(d) = Σ 1 / (k + rank_r(d))
常数 k 通常为 60(Cormack、Clarke 和 Buettcher 2009),用于平滑不同排名位置的权重贡献。排名第 1 的文档贡献 1/61 ≈ 0.0164。排名第 10 的文档贡献 1/70 ≈ 0.0143。在检索器的前 K 个中缺失的文档贡献为 0。
该机制原理十分简单:同时在两个检索结果中排名靠前的文档,会因叠加得到非零分值,最终获得更高融合得分。即便某个文档在单个检索器中排名第一,若仅被一个检索器命中,综合得分也会被压低。RRF 本质是对检索结果一致性进行加权。
下方三张表格针对语义查询、精确匹配查询、混合查询三类查询场景,逐步演示上述情况。综合来看,表格分别展示了 RRF 表现明显占优、以微弱优势保留正确结果,以及本文核心论点所聚焦的场景。
解读排名列时需注意:两个检索器均在包含数千份文档的完整语料库中检索。表格内展示的 BM25 与向量检索排名是文档在全量检索结果中的位次,而非仅针对表格里的四份文档。因此,BM25 排名 12,表示该文档在整个语料库的检索结果中位列第 12。
下文演示的三类查询均可在本地 Elasticsearch 实例中端到端完整运行。示例应用代码与数据集可在该 GitHub 示例项目中获取。
这是一个概念性问题。对应的正确文档是名为《认证服务中的令牌刷新和过期处理》的运维手册。该文档与检索内容存在多处共用术语,包括 “token”、“expiration”/“expired”、“handling”/“handle”、“auth”,因此被 BM25 检索命中。但另一篇关联性较低的文档,因 “system” 和 “token” 两个词汇出现频次更高,最终在 BM25 排序中排在了前面。
BM25 检索到了目标文档,但置信度低于《系统令牌轮换运维手册》。后者虽然在通用术语上匹配度更高,但对应的业务操作并不相关。向量检索凭借语义层面的匹配将正确文档排在首位。RRF 算法会优先加权两个检索结果中排名均靠前的内容,因此该文档最终位列融合结果顶部。而紧随其后的两个 RRF 结果(《OAuth 流程设计文档》与《系统令牌轮换运维手册》)也都能为读取候选结果的大模型提供有效上下文信息。
用户粘贴了堆栈跟踪里的错误代码。由于标识符字符串唯一且完全逐字匹配,BM25 成功检索到对应的运维手册。但向量检索效果不佳,因为查询内容除了“支付服务的错误”外几乎没有有效语义,嵌入模型难以精准区分 ERR_PAYMENT_GATEWAY_TIMEOUT 和该服务下其他同类错误码。
从逻辑合理性来看,邻近错误码对应的运维手册会出现在 BM25 检索结果中,这是因为相关手册的故障排查步骤通常会有交叉引用(例如“若出现 ERR_PAYMENT_GATEWAY_REJECTED,请参考本手册”),查询关键词恰好匹配了这类引用内容。如果没有这些交叉引用,BM25 就只会返回 TIMEOUT 对应的运维手册,邻近手册也不会出现在检索结果里。
RRF 将目标运维手册排在首位,但它与另一篇对应拒绝类错误码的手册得分差距很小,第二、第三名结果均为其他错误码对应的手册。针对这类纯标识符类查询,仅使用 BM25 检索得到的候选结果集质量反而优于混合检索。BM25 结果里的第二、第三位是明显无关的文档,大模型可直接过滤;但 RRF 排在第二、第三位的是内容相近的运维手册,容易让大模型误判用户实际提供的错误码。这也客观说明,混合检索的优势体现在整体数据分布层面,并不能对每一条查询都实现优化。
BM25 将目标文档排在首位,原因是文本中的 “rollback”、“v3.2”、“deployment”、“runbook” 全部精准匹配。向量检索则把 v3.2 版本的发布运维手册放在第一位,这并非因为嵌入模型判定发布内容比回滚内容与查询更相关,而是该查询与两份运维手册的余弦相似度差值仅在 0.01 至 0.02 之间。向量检索的这一排序结果更偏向随机噪声,不具备实际参考价值。再次运行查询或更换嵌入模型,二者的排名都可能发生颠倒。
这类因噪声导致核心操作意图无法区分的问题,正是混合检索所要解决的检索失效场景。BM25 倾向于匹配回滚相关的运维手册,打破了两项操作的排名胶着状态。RRF 会对两个检索器均位列前三的文档加权提权,最终将目标的 v3.2 版本回滚运维手册推至靠前位置。
三种查询的整体运行逻辑是一致的。对于语义查询,向量搜索能够定位到目标文档,RRF 会将这类结果置顶,同时添加 BM25 提供的匹配特征。对于精确匹配查询,BM25 可精准召回目标文档,RRF 同样将其保留在首位,只是第二名结果相比单独使用 BM25 时干扰信息会更多。对于混合查询,两类检索器各自存在不同的检索缺陷:BM25 的首位结果正确,但第二名返回了错误版本;向量搜索的首位结果则完全匹配错误。经过 RRF 融合后,最终首位结果准确,第二名虽存在偏差但具备相关性,也是三组结果中质量最优的一组。
根据我的经验,生产环境中的查询以第三种类型为主。大多数真实世界的查询将语义意图与特定标识符、版本号、错误代码或其他需要精确匹配的标记相结合,混合检索正是针对这类查询分布设计的工程解决方案。
目前业内主流的生产级 RAG 系统均普遍采用混合检索方案。Perplexity 在 Vespa 上结合了百亿级的 URL 词法检索与向量打分,并通过交叉编码器完成多阶段重排。Glean 则在企业搜索专属知识图谱之上叠加词法检索与稠密向量检索。二者应用场景不同,却采用了相同的架构思路。
Elasticsearch 和 OpenSearch 都通过检索器 API 原生支持混合检索(Elasticsearch 8.13 及以上版本率先实现,OpenSearch 紧随其后)。原生支持意味着检索融合已在搜索引擎内部单次查询中完成,无需在应用层额外做结果合并。下面的示例使用了 Elasticsearch 语法,OpenSearch 语法与之基本一致。
你的索引需同时配置用于 BM25 检索的标准文本字段和用于向量检索的稠密向量字段:
PUT /rag_knowledge_base{ "mappings": { "properties": { "title": { "type": "text" }, "content": { "type": "text", "analyzer": "standard" }, "content_vector": { "type": "dense_vector", "dims": 768, "index": true, "similarity": "cosine" } } }}复制代码
图 4. Elasticsearch 索引映射,同时定义了用于 BM25 的文本字段以及用于语义检索的 768 维密集向量字段。
在单次请求中同时调用两类检索器,并完成结果融合:
POST /rag_knowledge_base/_search{ "retriever": { "rrf": { "retrievers": [ { "standard": { "query": { "match": { "content": "rollback runbook for v3.2 deployment" } } } }, { "knn": { "field": "content_vector", "query_vector": [0.12, -0.45, ...], "k": 50, "num_candidates": 100 } } ], "rank_constant": 60 } }}复制代码
图 5. 使用 Elasticsearch 的 RRF 检索器进行混合检索查询,并行运行 BM25 和 kNN 搜索,并在单个请求中融合排名。
上述的默认配置可以作为合理的参考,但生产系统几乎总是需要进一步调优。其中的三个核心参数基本决定了检索相关性与查询延迟之间的取舍关系。
排名常数是 RRF 公式中的平滑参数,用于控制排名权重的衰减速率。排名为 r 的文档,其权重按 1/(k + r) 计入融合得分。该参数默认值为 60,适用于通用检索场景。若将数值调至 2030,会强化高排名结果的权重,当 BM25 对错误码、版本号、功能标识等内容实现精准匹配时,该设置效果更佳。若调高至 80100,排名权重曲线会趋于平缓,更倾向于选取在两类检索结果中同时出现的文档,而非仅在单一列表里排名靠前的内容。参数取值需根据业务需求选择:追求高精度则选用较小的 k 值,侧重召回率则选用较大的 k 值。
num_candidates 参数用于设定 HNSW 图遍历过程中获取前 K 个结果前需要检索的向量数量,控制近似最近邻搜索在召回率与查询延迟之间的权衡。将 k 设为 50、num_candidates 设为 100 效果较好。若发现向量搜索召回率偏低,即相关文档频繁排在前 50 名之外,可将 num_candidates 调至 200~300。该操作通常能在延迟小幅增加的前提下提升召回率,因为额外计算仅在向量索引内部完成,不会产生额外网络请求。
基于 RRF 的混合检索能获得优质的候选结果,而交叉编码器重排可进一步显著提升最终检索相关性。双编码器会分别为查询和文档生成嵌入向量,交叉编码器则将完整的查询-文档对输入 Transformer 进行联合处理,实现查询词与文档内容的细粒度标记交互。正是这一架构差异让交叉编码器的检索效果始终优于双编码器——它能够捕捉到独立嵌入无法识别的语义细节和关联关系。
在实践中,常规方案是先通过 RRF 筛选出 20 至 50 条候选结果,再使用 ms-marco-MiniLM-L-6-v2 这类交叉编码器完成最终重排。交叉编码器并不适合用于首轮检索,因为它需要对每一组查询-文档对执行前向计算,耗时较长;但对小规模候选集做重排时延迟完全可控,在 GPU 环境下处理 50 条候选结果通常耗时不足 100 毫秒。在 BEIR 等主流检索基准测试中,交叉编码器的表现始终优于双编码器:大模型在跨领域查询场景下提升尤为明显,轻量模型则能在同领域场景下带来可观效果增益。对于每一点检索相关性都至关重要的生产系统而言,这一重排环节很有价值。
稠密向量嵌入可解决检索的泛化问题,即便查询词与文档用词不一致,也能匹配到概念相关的内容。BM25 则解决了基于稀有、区分性标记找到精确匹配的精度问题。但二者单独使用都无法满足生产环境下 RAG 系统的需求。
向量嵌入属于近似检索,这既是它的优势,也带来了固有局限。基于 RRF 的混合搜索并非弥补模型性能短板的临时方案,而是面向同时兼容语义查询与精确匹配查询的系统,在架构层面的最优选择。
若 RAG 流程仅依靠向量嵌入完成检索,会损失检索效果。建议加入 BM25 检索,通过 RRF 融合结果,并使用交叉编码器实现重排。
查看英文原文:https://www.infoq.com/articles/vector-search-hybrid-retrieval-rag/
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。