
原文:The Art of Loop Engineering·· 作者:Sydney Runkle (LangChain)·· 声明:本文由 AI 翻译,可能包含错误
Agent 之所以有用,是因为它们能通过在真实世界中采取行动来帮我们自动化工作。但要让 agent 可靠地完成有价值的工作,光有一个好模型是不够的——还需要一个精心设计的 harness(控制框架),且这个 harness 要适配具体的任务集。
核心 agent 算法很简单:给 LLM 上下文,让它在一个循环里反复调用工具,直到任务完成。这是最基本的循环。但远非驱动 agent 的唯一循环。@swyx 最近写了篇好文章叫 loopcraft:堆叠循环的艺术,核心思想是你可以通过堆叠和扩展循环来构建更有效的 agent。
下面是我们对这个堆栈的理解,以及如何用 LangChain 的各个原语来装备每一层。
在最底层,agent 就是一个模型在循环里反复调工具,直到任务完成。
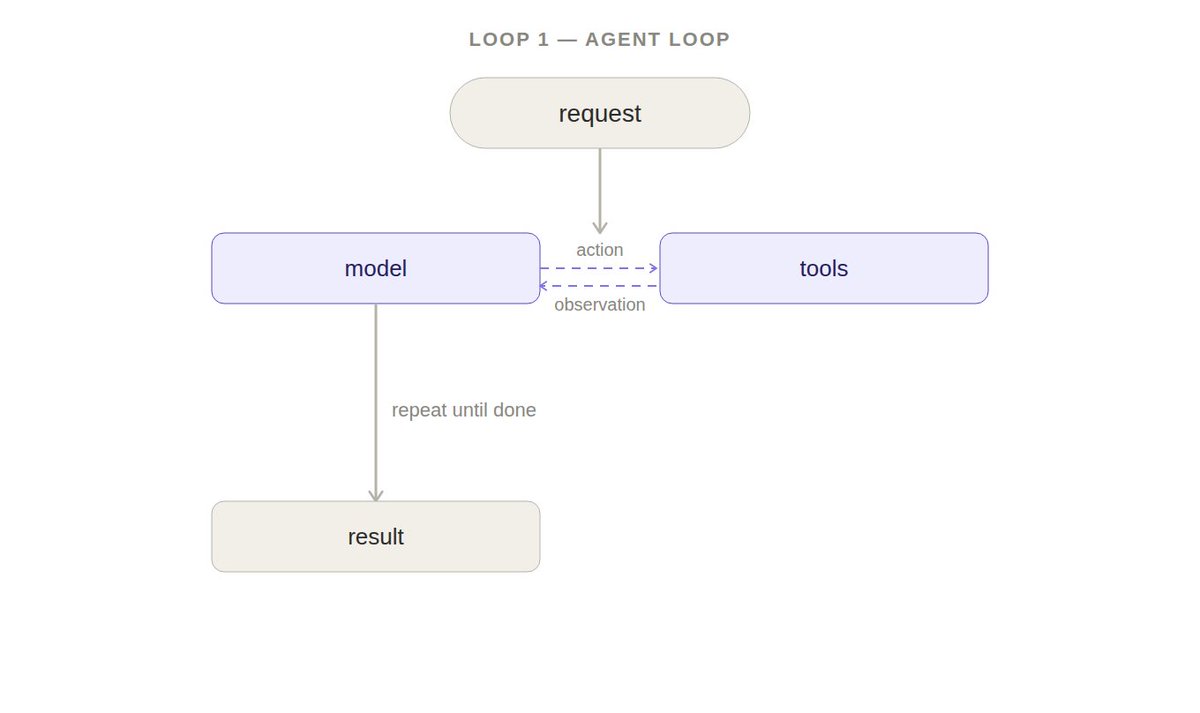
这就是 LangChain 的 create_agent 给你的东西。选任意模型,接入工具,就有了一个可以工作的 agent 循环。工具赋予了 agent 在真实世界采取行动的能力。
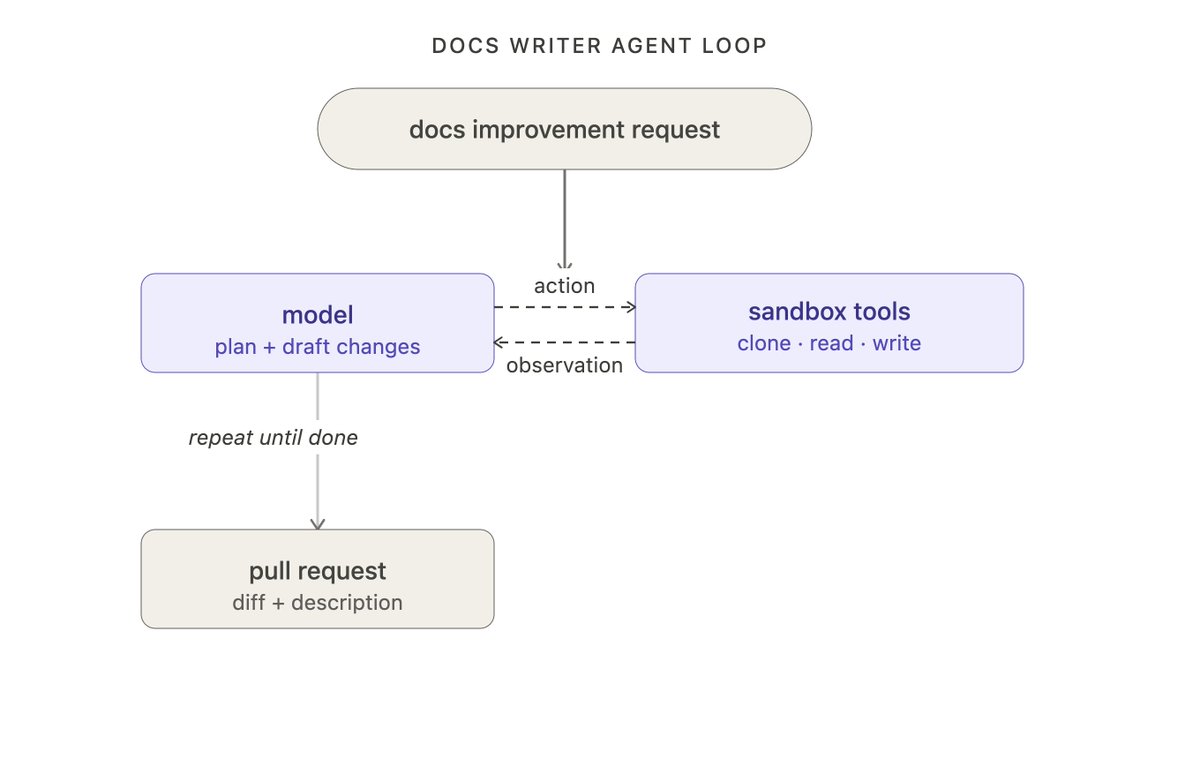
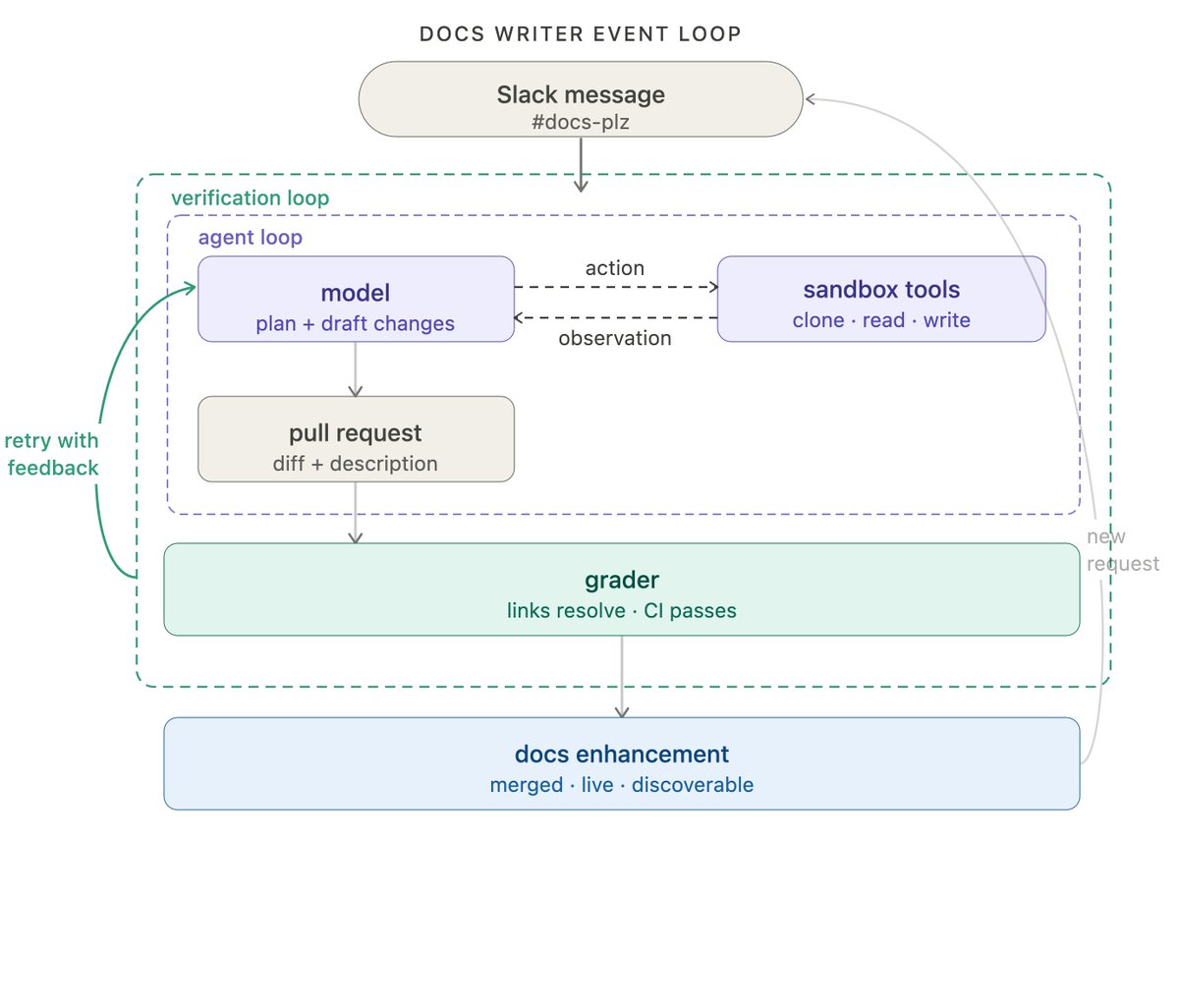
拿我们内部的文档 agent 举例(后面整篇文章都用它来做例子)。在第一层循环里,它收到一个文档改进的请求,模型规划并起草修改,然后用工具来克隆仓库、读文件、写文档、开 PR 等等。
agent 循环能把事情做完,但第一次跑的结果不一定总是正确或一致的。当一致性重要时,通常有必要在外面包一层验证循环:检查输出,不合格就把反馈送回模型重做。
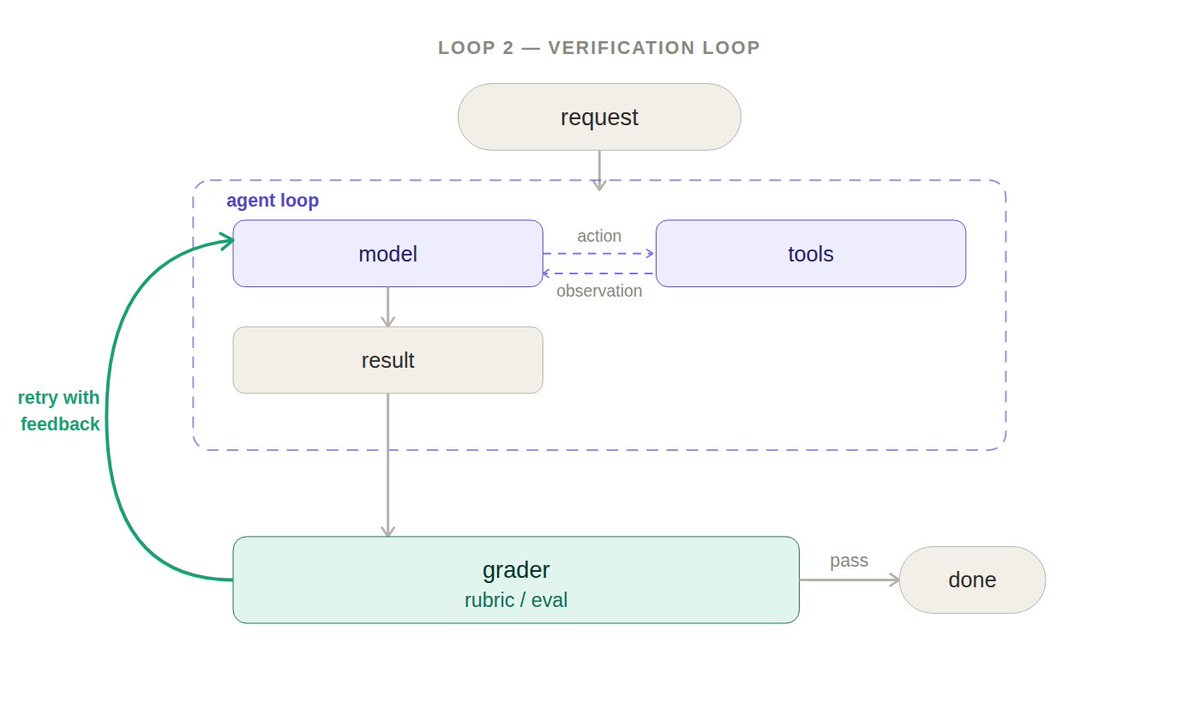
验证循环增加了一个评分器(grader):按评分标准检查 agent 的输出,如果不合格,带上反馈信息把结果发回去。评分器可以是确定性的,也可以是 agentic 的(LLM 当评委是经典案例)。
RubricMiddleware 处理这个模式,或者你也可以在 create_agent 上用 after_agent hook 来对接。
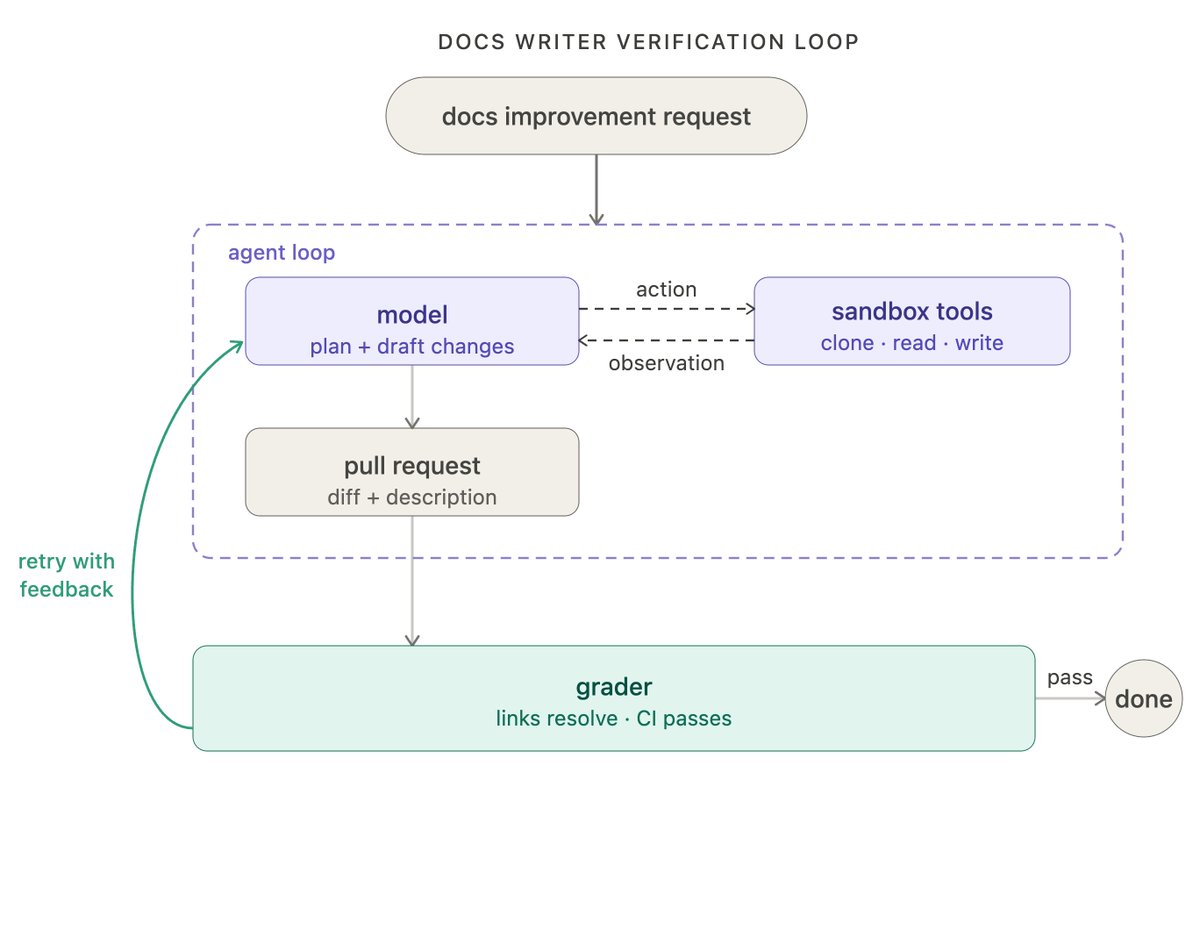
拿我们的文档 agent 来说,评分器在每次尝试后跑测试,检查所有链接是否能解析、所有 CI 检查是否通过、diff 的范围是否真的只是请求的内容。这类错误不需要人工审阅就能捕获。
一个权衡:加入验证会增加每次运行的延迟和成本。当质量比速度重要时值得——而大多数生产场景正是如此。
agent 开发中最重要的一部分是集成层:把你的 agent 接入生态系统,让它能在后台运行。
事件驱动循环把你的 agent 连到生态系统里。事件触发——新文档落地、定时任务触发、webhook 到达——agent 就开始运行。agent 不是你手动调用的东西;它是一个持续运行在更大系统内部的组件。
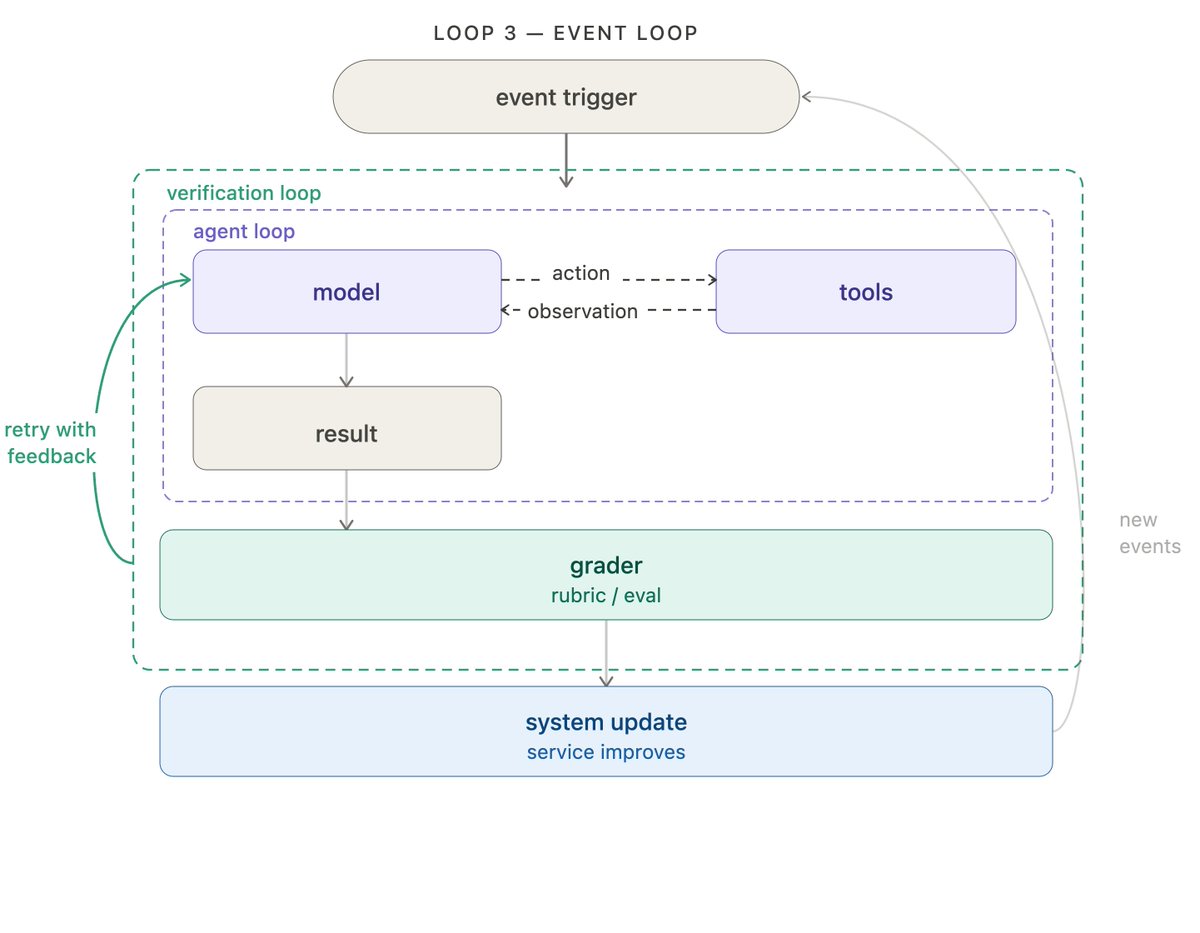
LangSmith Deployment 提供了触发器基础设施,包括 cron 定时和 webhook 支持。openclaw 中"心跳"(heartbeats)是 crons 的一个流行用法,它把你的 agent 变成了一个永远在线、主动出击的助手。
我们的文档 agent 由 Fleet 驱动,这是一个无代码 agent 构建器。Fleet 的 channels 和 schedules 处理事件驱动和 cron 类的触发器。我们用一个 channel,当 #docs-plz Slack 频道里有消息发出时,就触发文档 agent。
前三个循环自动化工作。第四个——可以说最重要的——自动化改进本身!
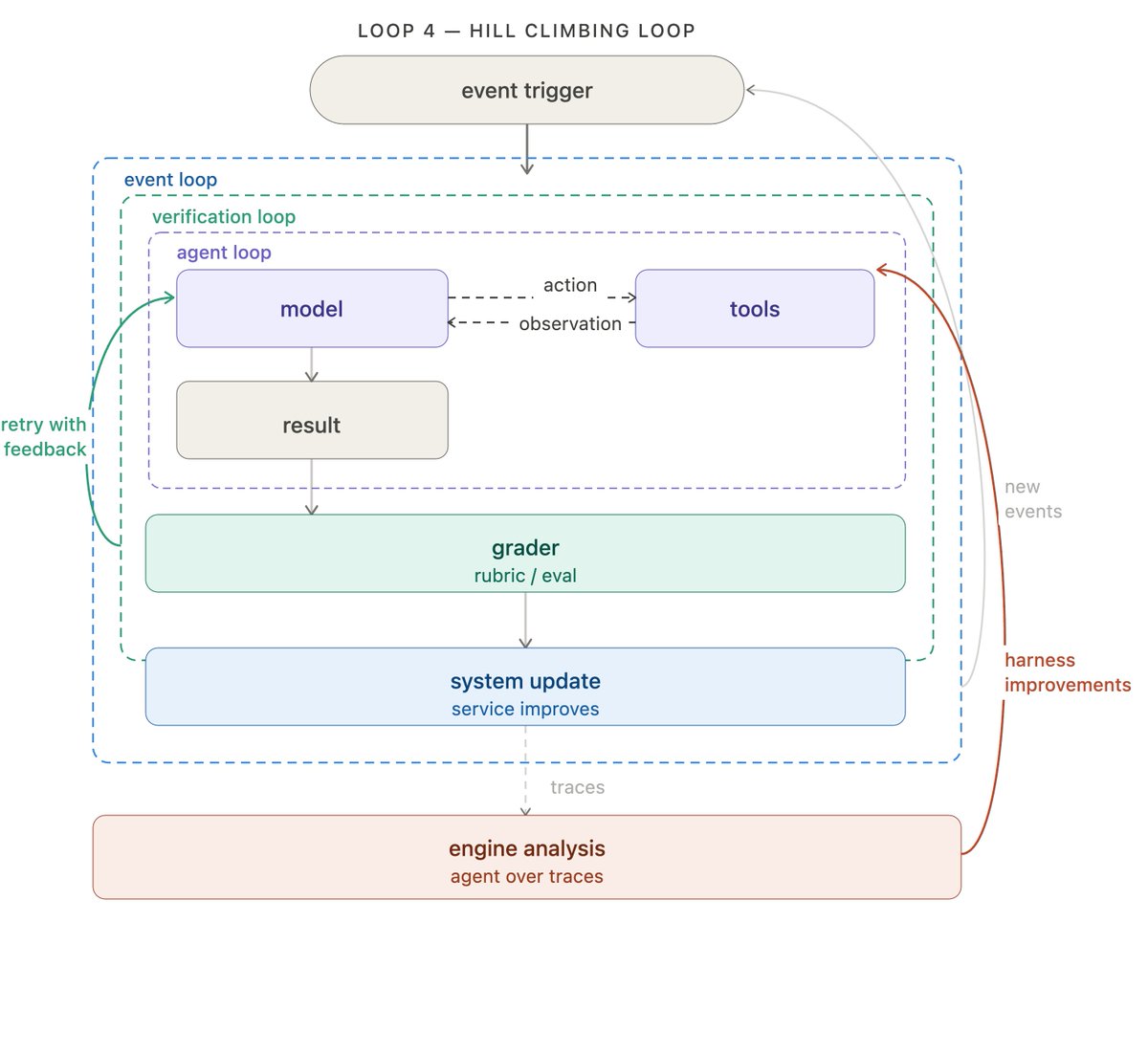
每次 agent 运行都会产生一条 trace(追踪记录):记录了模型做了什么、调用了哪些工具、评分器的反馈等等。这些 trace 里包含了关于什么在起作用、什么不起作用的高价值信号。爬坡循环运行一个分析 agent 来分析这些 trace,并根据发现重写 harness 的配置。这可以包括 prompt 调整、工具调整或评分器调整。
在 LangSmith 中,你可以用 Engine(我们的 trace 分析 agent)来装备这第四层循环。
回到文档 agent 的例子:我们在文档 agent 的 trace 上跑 Engine 来检测问题。当多条 trace 指示出潜在问题时,就会开一个 issue,要求修改有问题的 prompt 或工具。
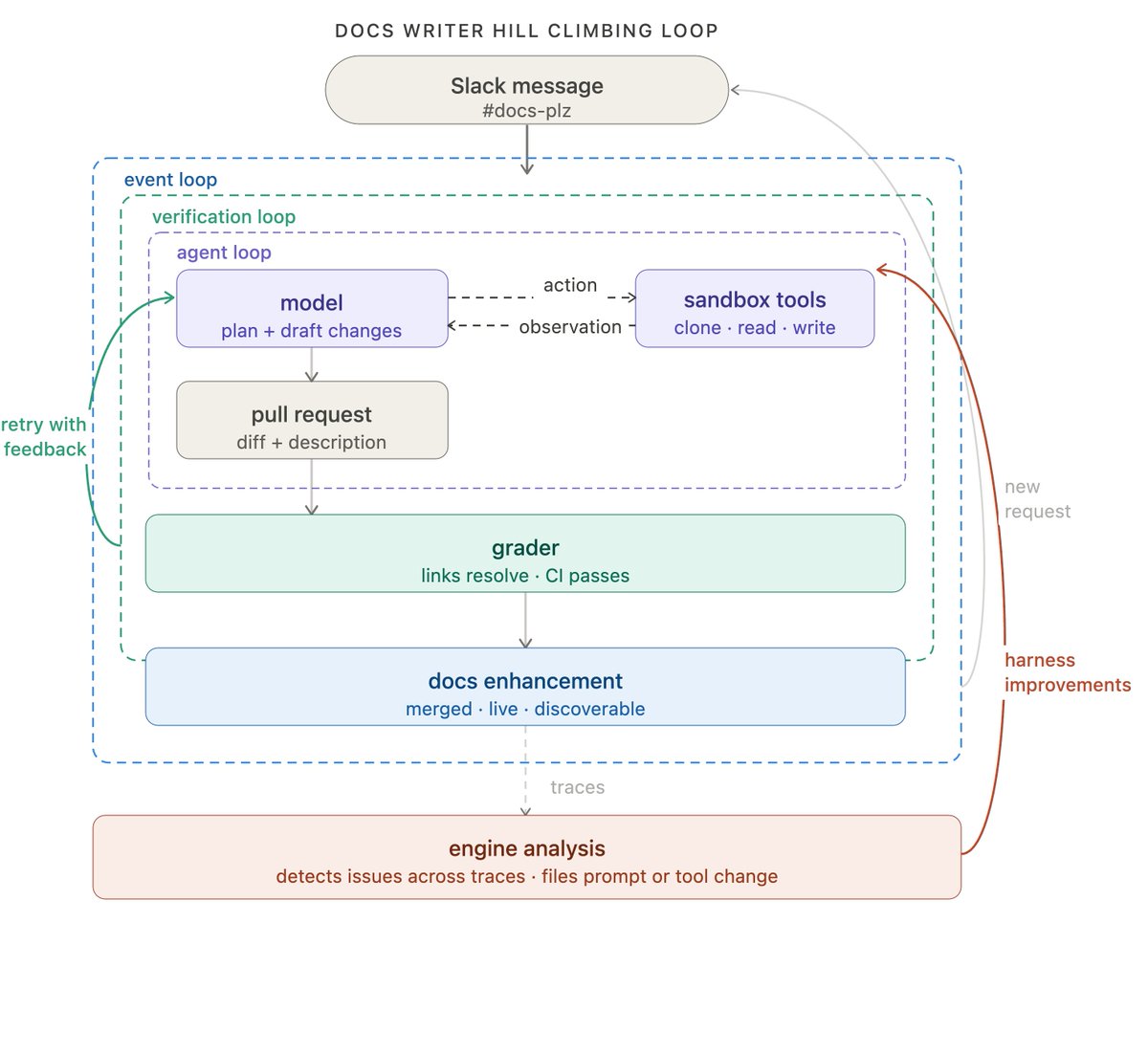
关键点在于:返回箭头不只是回到顶层——它向内伸进去,直接更新 agent 循环本身。外循环的每轮迭代都让内循环变得更好。
展望:prompt 和工具配置是最容易改进的东西,但并非唯一选项。对于跑开源模型的团队,爬坡循环可以喂给 RL 微调管线,用 trace 或评估结果作为训练信号来改进模型本身。辅助上下文(如记忆层和检索技能)也可以用同样的方式改进。循环是模式;它优化什么,取决于你。
自动化不意味着把人从循环中移除。在每一层,都有自然的位置让人参与进来产生价值。自动评分器能检查链接是否能解析;但需要人来发现框架对受众来说不对味。这种判断力——来自上下文、经验和品味的积累——正是人工审阅不可替代的地方。
一些专业知识应该固化到 prompt/工具本身,但对于敏感操作,实时人工审阅是必要的(想想金融交易、数据库操作等)。LangChain 在每个循环中都提供了简单的方式来设置这些接触点:
LangChain 的所有开源框架都把"人在回路"作为一等公民原语来支持。
为了方便,这里用列表来展示四个循环如何堆叠:
create_agentRubricMiddleware这就是 loop engineering——或者说 @swyx 称之为 loopcraft——在实际中的样子。AI 领域的前沿人物如 Steipete、Boris 和 Andrej 都得出了相同的结论:agent 的潜力在于你围绕它们构建的循环。
我们思考循环 1 和 2 已经有一段时间了。但焦点应该转向循环 3 和 4——通过将 agent 嵌入你的生态系统并让它们根据你的标准持续改进,价值在这里复利增长。
Satya 点出了这个组织层面的意义:那些早期就构建学习循环的公司——人的判断和 token 资本在其中复合增长——将建立难以复制的优势。
感谢 @Vtrivedy10、@masondrxy、@hwchase17 和 @huntlovell 的有益审阅。
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。