Embedding Fingerprint Demo
Paste any embedding vector and identify which model produced it.
Embedding models are black boxes. You send text in, you get a vector out. A list of floating-point numbers with no label, no watermark, no metadata telling you where it came from. If someone hands you a 1024-dimensional vector, can you tell whether it was produced by BGE-M3, jina-embeddings-v5-text-small, or Qwen3-Embedding? And even if two vectors come from the same model, can you tell whether they were generated with a retrieval or a classification instruction?
It turns out you can. The numerical patterns in an embedding vector carry a surprisingly strong fingerprint of the model that produced it, and even of the instruction prompt used during inference. We trained a small transformer classifier (800K parameters) to identify 68 different model-task combinations from 25+ embedding models, achieving 87% accuracy by reading nothing but raw floating-point digits. You can try the live demo yourself: paste any embedding vector and see which model and task the classifier thinks produced it.
Tokenization: Treating Numbers as Text
A 1024-dimensional embedding vector is a sequence of 1024 floating-point numbers. To feed it into a classifier, we need a representation that makes no assumptions about the structure of the values.
We take a bold approach: treat each float as a string of digit characters and tokenize it character by character. This may sound wasteful compared to more compact alternatives, but it turns out to be the right trade-off. For a value like -0.1234, the token sequence is:
- 0 . 1 2 3 4Dimensions are separated by a [SEP] token. The full sequence starts with [CLS]. The complete vocabulary has 15 tokens:
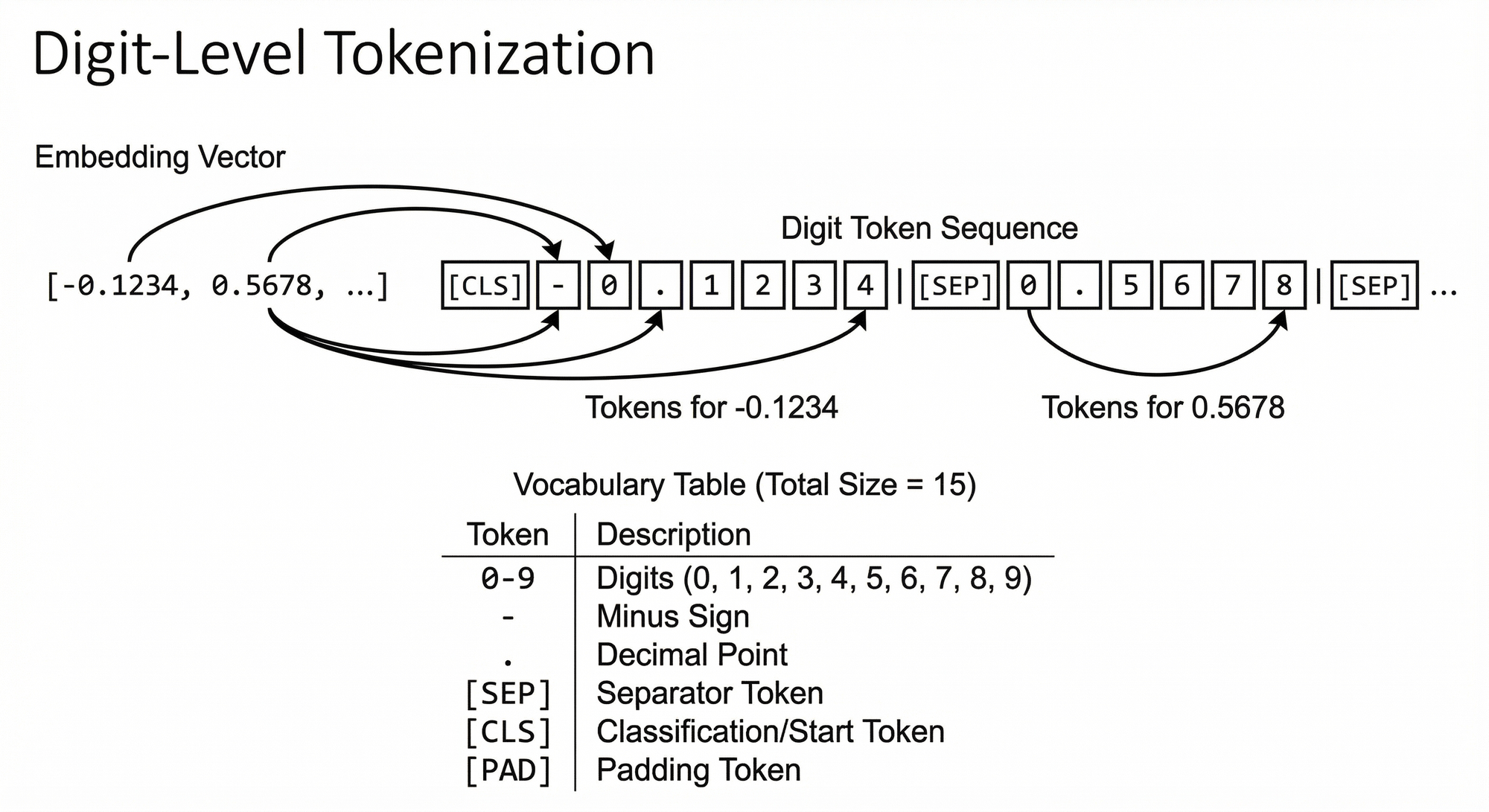
| Token ID | Meaning |
|---|---|
| 0-9 | Digits |
| 10 | Minus sign |
| 11 | Decimal point |
| 12 | [SEP] |
| 13 | [CLS] |
| 14 | [PAD] |
At 4 decimal places of precision, a 1024-dimensional vector produces roughly 7,700 tokens. A 384-dimensional vector produces about 2,900 tokens. The sequence length varies naturally with the embedding dimension, and no padding or truncation is needed across dimensions. Since the tokenizer is a direct integer mapping with no learned components, it is extremely efficient.
Model Architecture
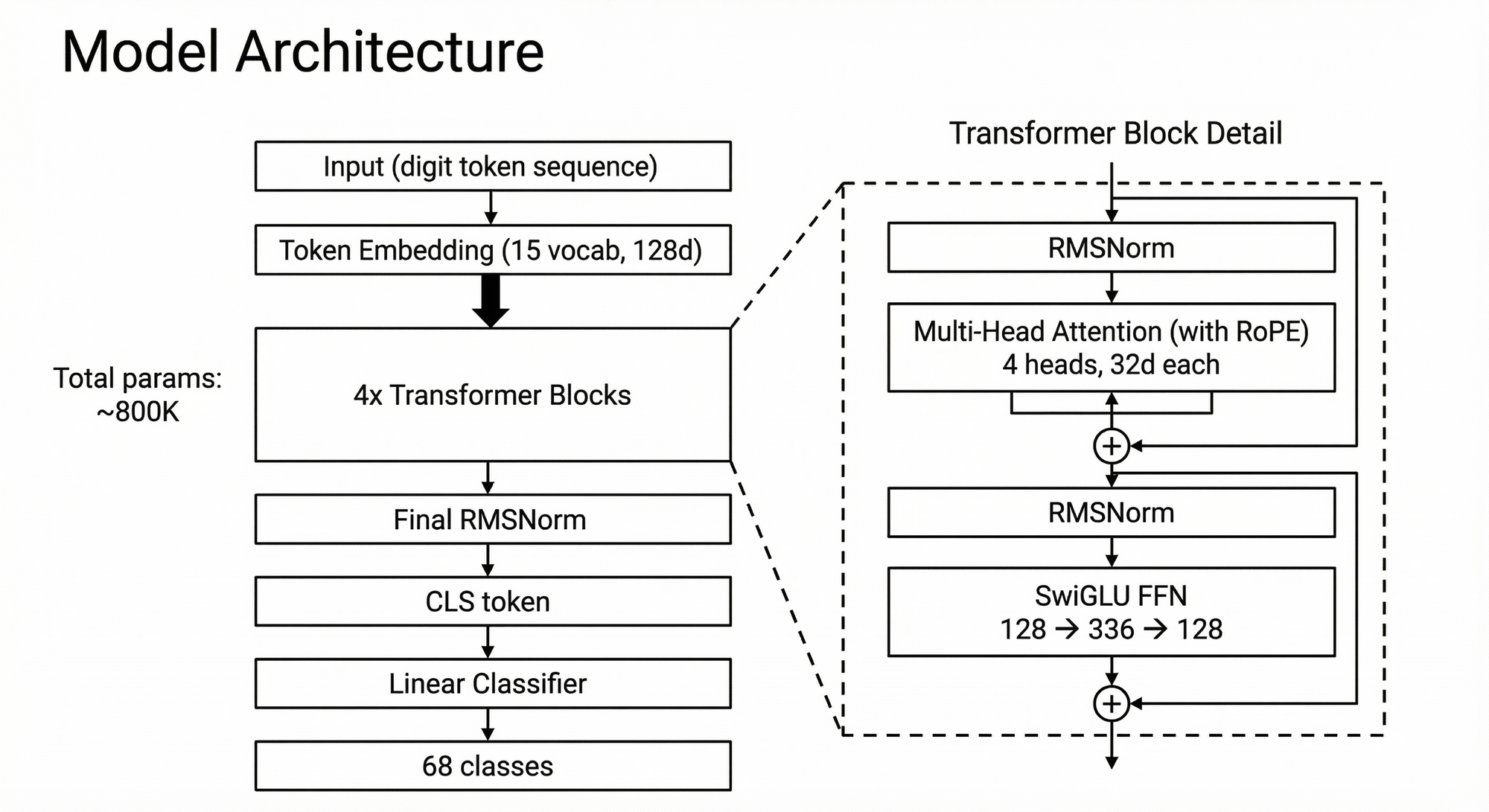
The classifier is a small encoder-only transformer with 4 layers, 128 dimensions, 4 attention heads with RoPE, SwiGLU FFN, and RMSNorm. The CLS token is pooled and projected into the 68-class output space. Total parameters are roughly 800K.
Despite the tiny vocabulary of 15 tokens, this is fundamentally a long-sequence task. A single 1024-dim embedding becomes a 7,700-token sequence, longer than typical NLP inputs. The model must attend over thousands of digit tokens to pick up statistical patterns that distinguish one model's output from another. This makes efficient attention and positional encoding (RoPE) essential even at this small scale.
Data
We used 10,000 multilingual text samples, each embedded by 25+ models with various task prefixes such as retrieval.query, retrieval.document, classification, and clustering, producing 68 distinct classes. Importantly, the 68 classes include not just different models but also different instruction prompts applied to the same model. For example, jina-embeddings-v5-text-small with a retrieval instruction and jina-embeddings-v5-text-small with a classification instruction are treated as separate classes. The goal is to detect both model identity and task-specific behavior from the raw output alone.
Each class is split into 7,000 training and 3,000 validation samples. The models span five output dimensions.
| Dimension | Classes | Example Models |
|---|---|---|
| 384 | 8 | BGE-small, E5-small, MiniLM, GTE-small |
| 512 | 2 | BGE-small-zh |
| 768 | 24 | BGE-base, E5-base, jina-embeddings-v5-text-nano, Nomic, INSTRUCTOR, LaBSE |
| 1024 | 32 | BGE-M3, E5-large, jina-embeddings-v3, jina-embeddings-v5-text-small, Qwen3-0.6B, Snowflake, mxbai |
| 1536 | 2 | GTE-Qwen2-1.5B |
Within the 1024-dim group alone, there are 32 classes to separate, including models from the same family with different task prefixes. The classifier cannot rely on sequence length here; it must learn purely numerical patterns.
Training
Training ran on an A100 40GB with mixed precision, length-bucketed batching, and AdamW with cosine schedule, reaching about 340K tokens per second and 23,800 steps per epoch.
Experimental Results
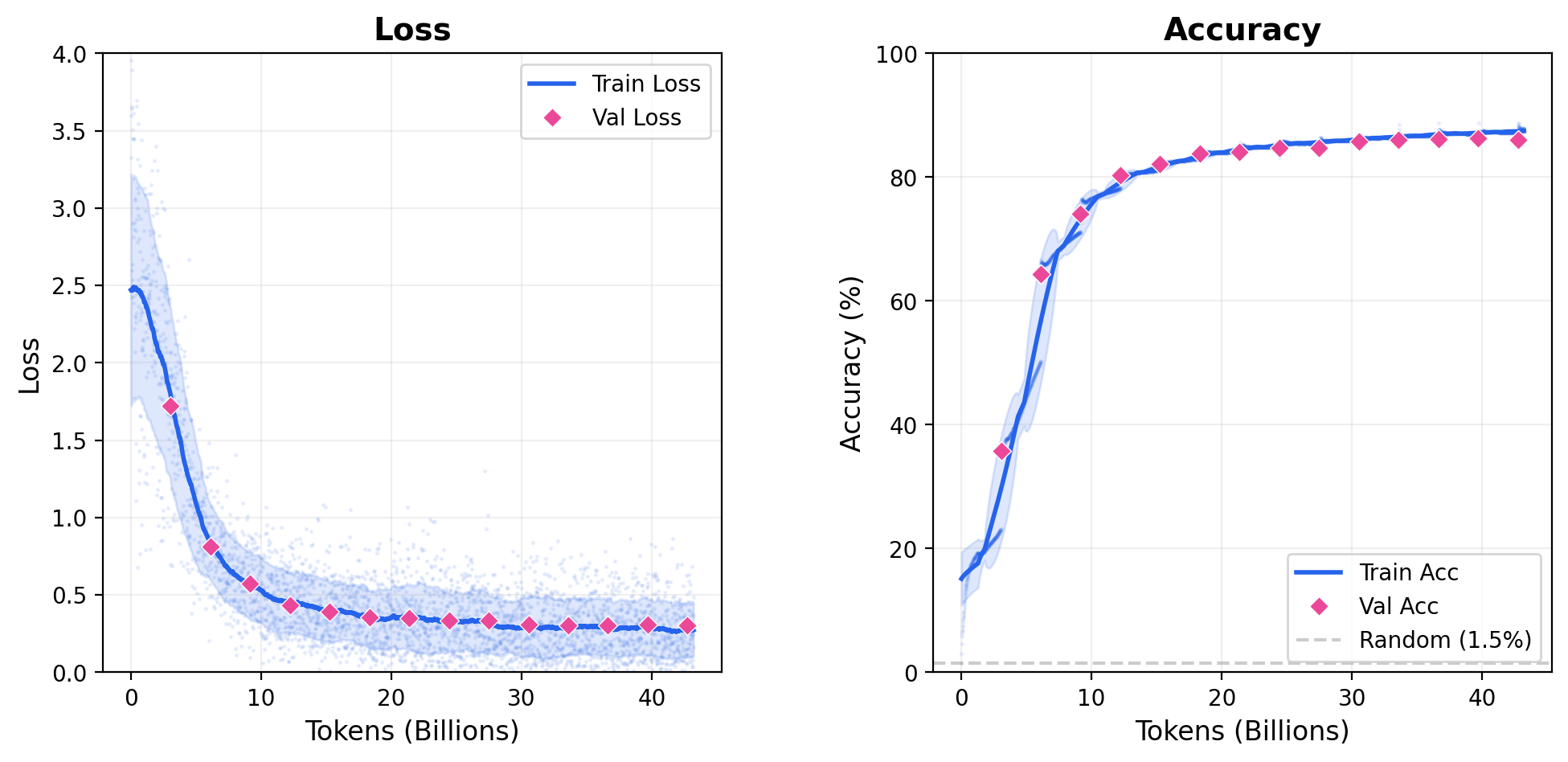
The close train/val gap and continued improvement suggest generalizable learning rather than memorization. At 800K parameters, the model is approaching its capacity limit, and a larger model would likely push accuracy higher.
Confusion Matrix
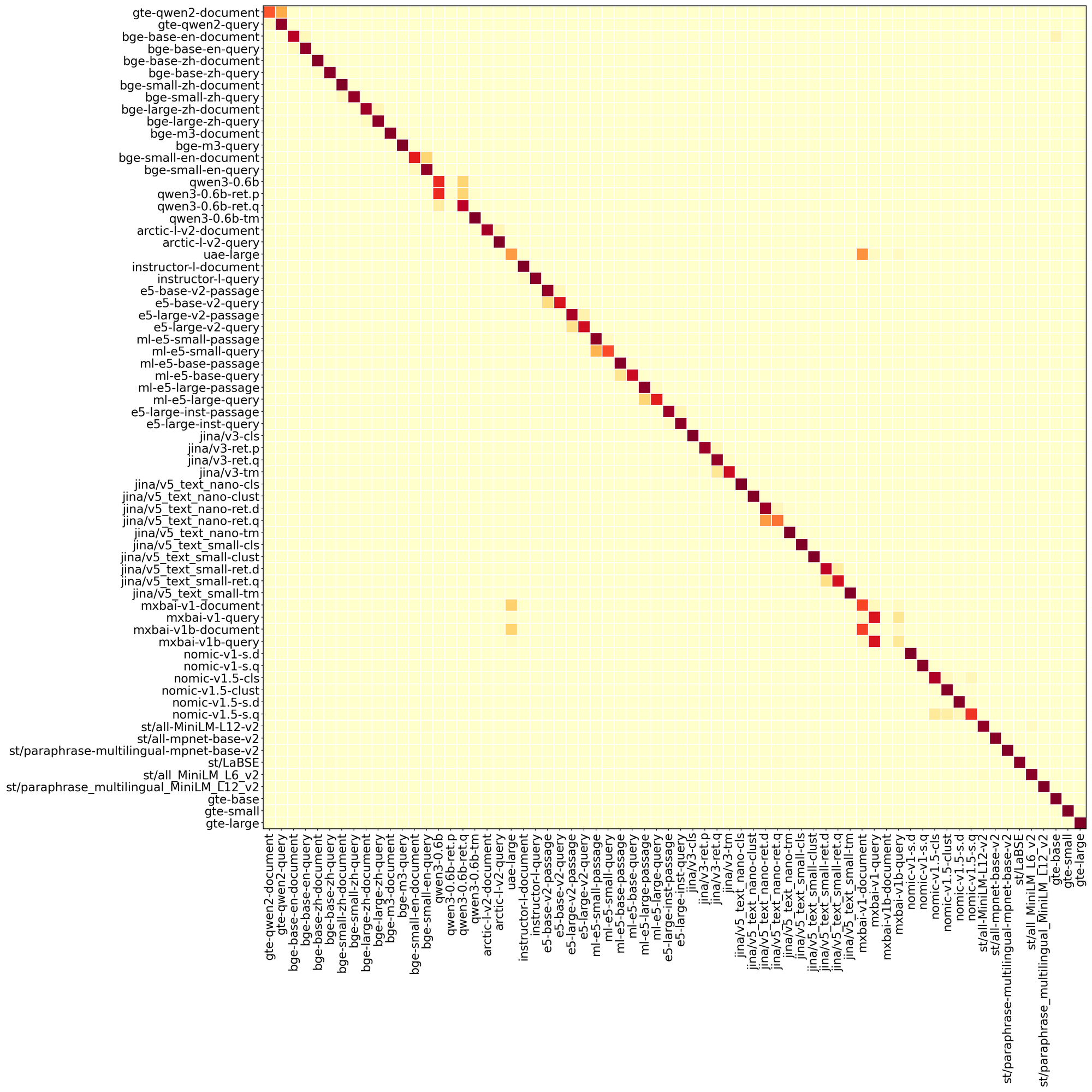
Overall accuracy is 87.0%, or 59x better than random chance at 1.5%. Several models are classified perfectly, including GTE-large, jina-embeddings-v3/jina-embeddings-v5-text-small classification variants, LaBSE, and Paraphrase MiniLM. The hardest cases are task-prefix variants of the same base model. Qwen3-0.6B has the most within-family confusion across its 4 task types, while jina-embeddings-v5-text-small achieves 92% within-family accuracy across 5 tasks. The fact that different instruction prompts on the same model produce distinguishable output patterns is itself a noteworthy finding, suggesting that task adaptation leaves a measurable numerical trace even when the base weights are identical.
Models from different families (BGE vs. Jina vs. E5 vs. Nomic) are much easier to separate than task variants of the same model. The core architecture and training methodology leave a stronger signature than task-specific adapters. The real challenge lies in the 1024-dim group (32 classes) and 768-dim group (24 classes), where the classifier must rely purely on numerical patterns rather than sequence length.
Alternative Approaches
Bucket Tokenizer
Quantize each dimension into one of K bins (say, 256), producing a compact sequence of length D, one token per dimension. This is the approach used by Embedding-Converter (ICLR 2025). For a 1024-dim vector, you get 1024 tokens instead of 7,700.
Bucketing imposes a prior on the value distribution. You must decide bin boundaries before seeing the data. But different models distribute their values in fundamentally different ways. Some concentrate mass in a narrow range around zero, others spread values across [-1, 1] uniformly, and the distribution varies by dimension within a single model. Any fixed binning scheme either wastes resolution where values cluster or under-resolves where they spread. Adaptive binning per model defeats the purpose, since it requires knowing the model identity beforehand.
Fixed-Length MLP
Feed the raw embedding vector directly into an MLP classifier. The fundamental problem goes beyond the variable-dimension issue (our models produce vectors of 384 to 1536 dimensions). Even if you pad everything to a fixed length, you are implicitly assuming that dimension indices are semantically aligned across models, that dimension 1 of BGE-M3 corresponds to dimension 1 of jina-embeddings-v5-text-small. This assumption is false. Different architectures, training data, and training objectives produce entirely different internal representations.
Both alternatives impose structural assumptions that the model must work around. Digit-level tokenization avoids all of them. It is the most assumption-free representation we could find: here are the exact digits of each number, in order, separated by markers. Figure out the rest yourself.
Conclusion
Embedding models are trained to map semantically similar texts to nearby vectors. The training objective says nothing about making the vectors identifiable, nothing about encoding a model signature. Yet the signature is there, strong enough for a tiny classifier to detect. The "style" of an embedding model, the specific numerical patterns it uses to represent meaning, is as distinctive as handwriting. Even the choice of instruction prompt leaves a detectable trace.
This has practical value for auditing vector databases when the source model is unknown, verifying that an API actually uses the model it claims, and detecting model version changes. More fundamentally, it tells us that embedding models encode meaning in structurally distinct ways, even when producing vectors of the same dimensionality.