jinaai/jina-reranker-v3 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.


GGUF quantizations and MLX support are available.
jina-reranker-v3: Last but Not Late Interaction for Document Reranking
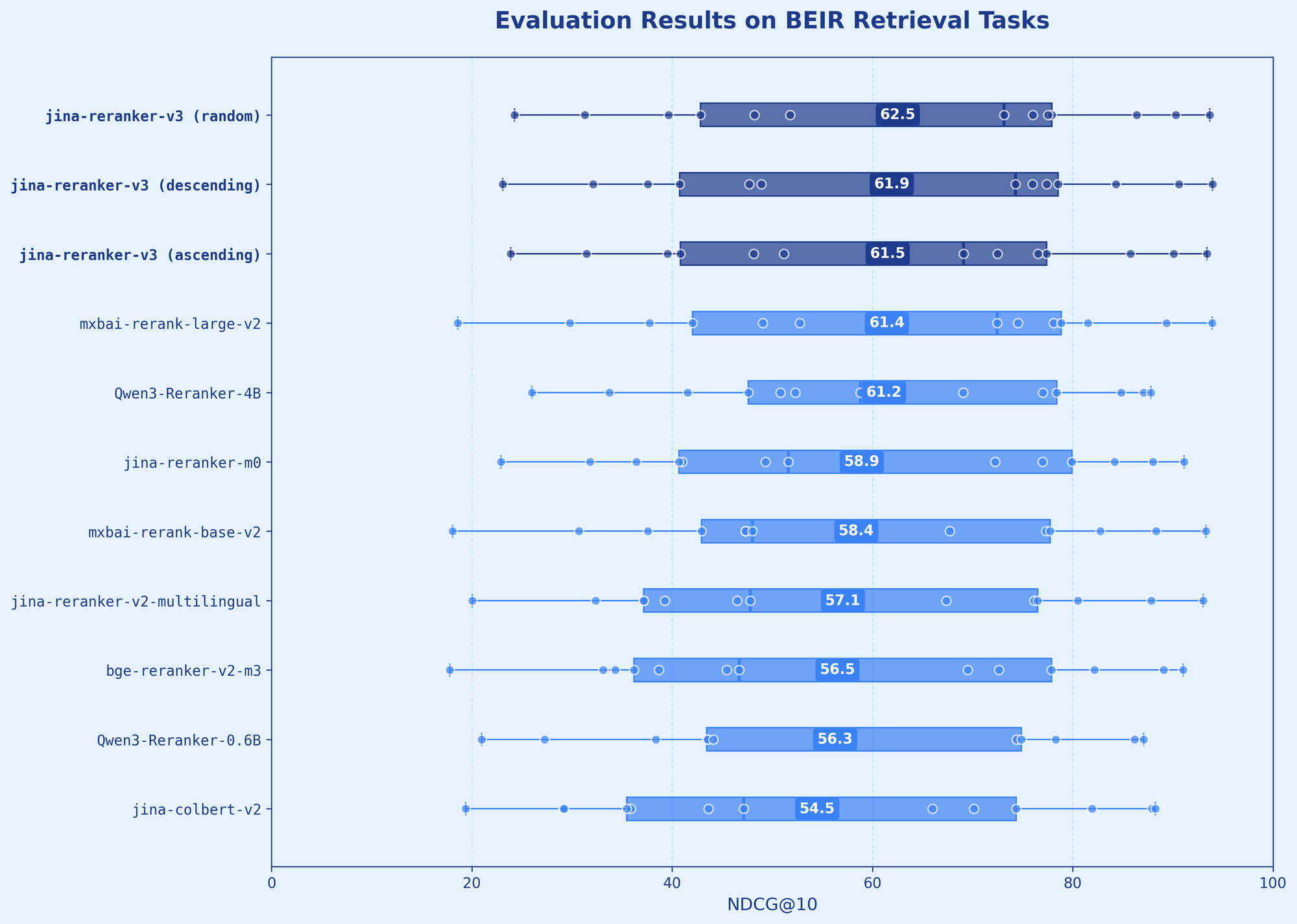
jina-reranker-v3 is a 0.6B parameter multilingual document reranker that introduces a novel last but not late interaction. Unlike late interaction models such as ColBERT that perform separate encoding followed by multi-vector matching, our approach conducts causal self-attention between query and documents within the same context window, enabling rich cross-document interactions before extracting contextual embeddings from the last token of each document. This compact architecture achieves state-of-the-art BEIR performance with 61.94 nDCG@10 while being ten times smaller than generative listwise rerankers.
 arXiv.orgFeng Wang
arXiv.orgFeng Wang

We're excited to release jina-reranker-v3, our latest-generation reranker that delivers state-of-the-art performance across multilingual retrieval benchmarks. This 0.6B-parameter document reranker introduces a novel last but not late interaction that takes a fundamentally different approach from existing methods. jina-reranker-v3 works listwise: it applies causal attention between the query and all candidate documents within a single context window, enabling rich cross-document interactions before extracting contextual embeddings from each document's final token. Our new model achieves 61.94 nDCG@10 on BEIR outperforming Qwen3-Reranker-4B while being 6× smaller in size.
| Model | Size | BEIR | MIRACL | MKQA | CoIR |
|---|---|---|---|---|---|
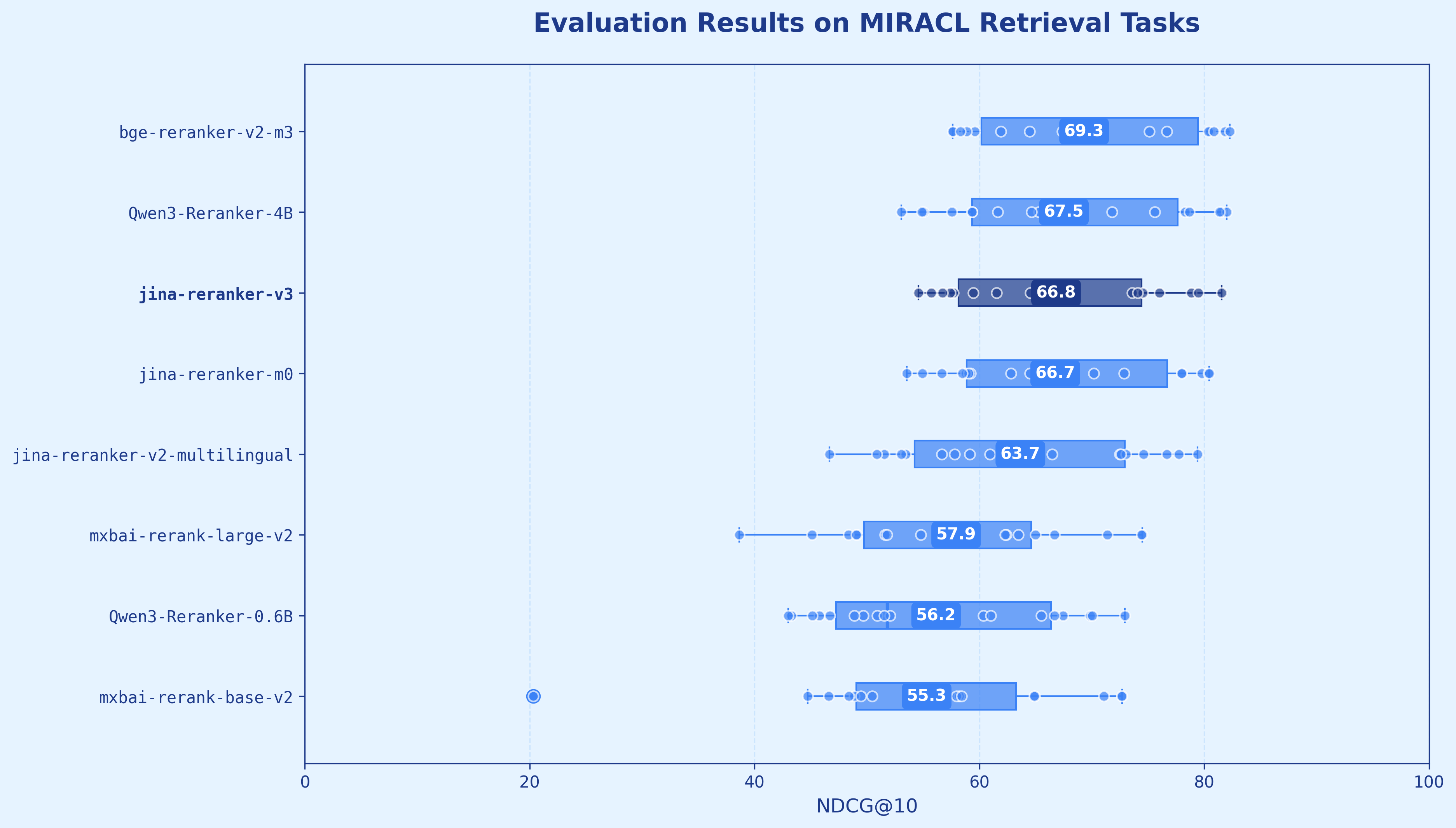
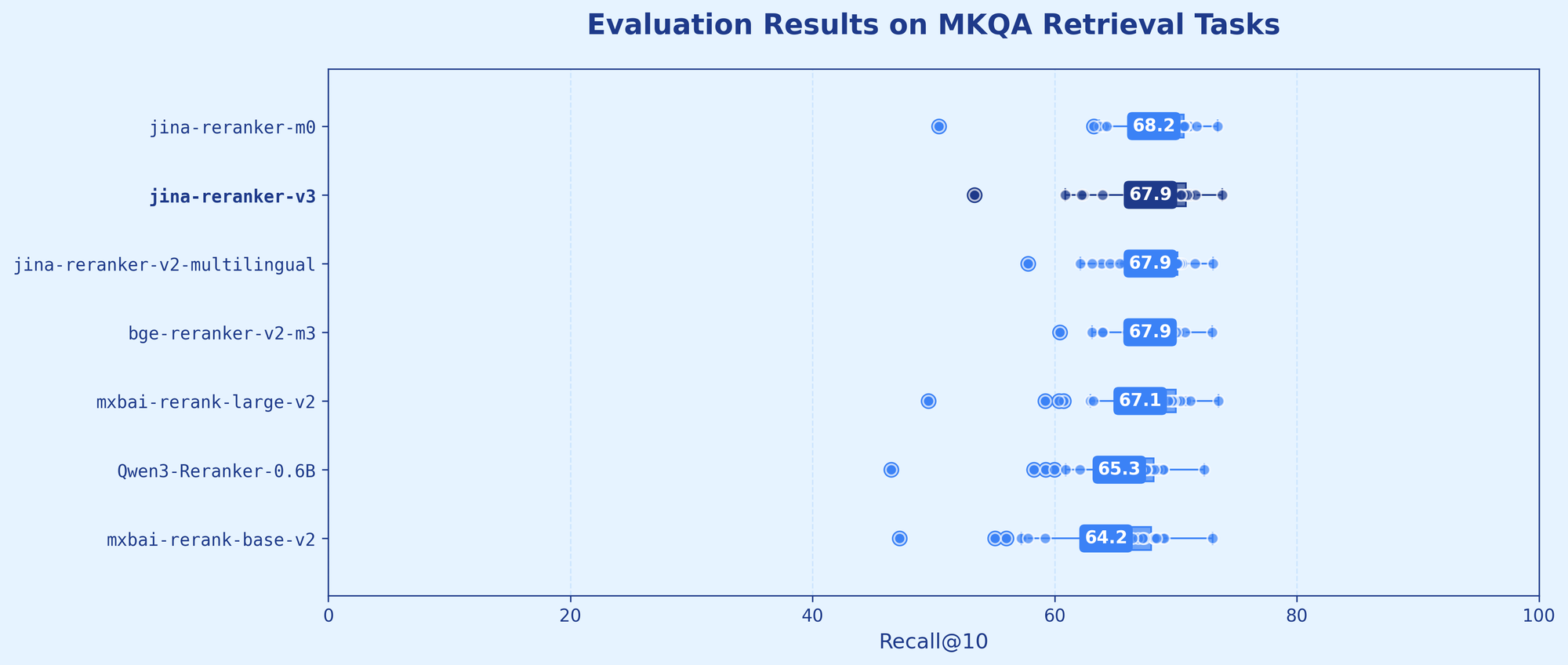
| jina-reranker-v3 | 0.6B | 61.94 | 66.83 | 67.92 | 70.64 |
| jina-reranker-v2 | 0.3B | 57.06 | 63.65 | 67.90 | 56.14 |
| jina-reranker-m0 | 2.4B | 58.95 | 66.75 | 68.19 | 63.55 |
| bge-reranker-v2-m3 | 0.6B | 56.51 | 69.32 | 67.88 | 36.28 |
| mxbai-rerank-base-v2 | 0.5B | 58.40 | 55.32 | 64.24 | 65.71 |
| mxbai-rerank-large-v2 | 1.5B | 61.44 | 57.94 | 67.06 | 70.87 |
| Qwen3-Reranker-0.6B | 0.6B | 56.28 | 57.70 | 65.34 | 65.18 |
| Qwen3-Reranker-4B | 4.0B | 61.16 | 67.52 | 67.52 | 73.91 |
| jina-code-embeddings-0.5b | 0.5B | - | - | - | 73.94 |
Model Architecture
jina-reranker-v3 is built on the Qwen3-0.6B backbone, a decoder-only transformer model with causal self-attention. The model processes multiple documents and query simultaneously, extracting contextual embeddings at designated token positions for efficient similarity computation.

| Parameter | Value |
|---|---|
| Total Parameters | 0.6B |
| Non-Embedding Parameters | 0.44B |
| Hidden Size | 1,024 |
| Number of Layers | 28 |
| Attention Heads (Q/KV) | 16/8 (GQA) |
| Context Length | 131,072 |
| MLP Projector | 1024→512→256 |
| Final Embedding Size | 256 |
Given a query and a set of candidate documents, jina-reranker-v3 processes the reranking task with a specialized prompt template that enables cross-document interactions within a single forward pass. The input construction follows a specific format:
<|im_start|>system
You are a search relevance expert who can determine
a ranking of passages based on their relevance to the query.
<|im_end|>
<|im_start|>user
I will provide you with k passages, each indicated by a numerical identifier.
Rank the passages based on their relevance to query: [QUERY]
<passage id="1">
[DOCUMENT_1]<|doc_emb|>
</passage>
<passage id="2">
[DOCUMENT_2]<|doc_emb|>
</passage>
...
<passage id="k">
[DOCUMENT_k]<|doc_emb|>
</passage>
<query>
[QUERY]<|query_emb|>
</query>
<|im_end|>
<|im_start|>assistant
<think></think>Each document is wrapped in passage tags with sequential IDs, enabling clear document boundaries within the shared context window. The model processes up to 64 documents simultaneously within its 131K token context capacity. For larger document collections, processing occurs in batches while maintaining query consistency across batches.
The query appears twice in the input structure - once at the beginning for task instructions and once at the end for final attention processing. This dual placement enables the final query position to attend to all preceding documents through causal attention. Two critical special tokens mark embedding extraction positions: the <|doc_emb|> token is placed after each document to mark document embedding extraction points, while the <|query_emb|> token is placed after the final query to mark query embedding extraction point. These embeddings capture both local document semantics and global cross-document context through the shared causal self-attention mechanism.
We call this query-document interaction "last but not late." It's "last" because <|doc_emb|> is placed as the final token of each document. It's "not late" because, unlike late interaction models such as ColBERT that separately encode documents before multi-vector matching, we enable query-document and document-document interactions within the same context window during the forward pass.
Finally, a two-layer MLP projector with ReLU activation maps the 1024-dimensional hidden states to a 256-dimensional ranking space. Relevance scoring is computed using cosine similarity between the projected query embedding and each projected document embedding. This produces a relevance score for each document in the input set.
Getting Started
Via API
The easiest way to use jina-reranker-v3 is via our Search Foundation API.
curl -X POST \
https://api.jina.ai/v1/rerank \
-H "Content-Type: application/json" \
-H "Authorization: Bearer JINA_API_KEY" \
-d '{
"model": "jina-reranker-v3",
"query": "slm markdown",
"documents": [
...
],
"return_documents": false
}'{
"model":"jina-reranker-v3",
"usage": {
"total_tokens":2813
},
"results":[
{
"index":1,
"relevance_score":0.9310624287463884
},
{
"index":4,
"relevance_score":0.8982678574191957
},
{
"index":0,
"relevance_score":0.890233167219021
},
...
]
}The relevance_score field indicates the relevance of each document to the query, with higher scores indicating greater relevance.
Via transformers
from transformers import AutoModel
model = AutoModel.from_pretrained(
'jinaai/jina-reranker-v3',
dtype="auto",
trust_remote_code=True,
)
model.eval()Now you can use the model's rerank function to compute relevance scores for a query and a list of documents:
query = "What are the health benefits of green tea?"
documents = [
"Green tea contains antioxidants called catechins that may help reduce inflammation and protect cells from damage.",
"El precio del café ha aumentado un 20% este año debido a problemas en la cadena de suministro.",
"Studies show that drinking green tea regularly can improve brain function and boost metabolism.",
"Basketball is one of the most popular sports in the United States.",
"绿茶富含儿茶素等抗氧化剂,可以降低心脏病风险,还有助于控制体重。",
"Le thé vert est riche en antioxydants et peut améliorer la fonction cérébrale.",
]
# Rerank documents
results = model.rerank(query, documents)
# Results are sorted by relevance score (highest first)
for result in results:
print(f"Score: {result['relevance_score']:.4f}")
print(f"Document: {result['document'][:100]}...")
print()
Conclusion
jina-reranker-v3 is a new 0.6B parameter multilingual listwise reranker that introduces last but not late interaction for efficient document reranking. Documents can attend to each other during encoding, establishing interaction that inform the final ranking.
One of the primary concerns is whether such interaction is resilient to input permutation—that is, if we shuffle the input order, will the rankings stay the same? We tested this with a query against 110 candidate documents using random permutation and plotted the variance at each rank position in the figure below.
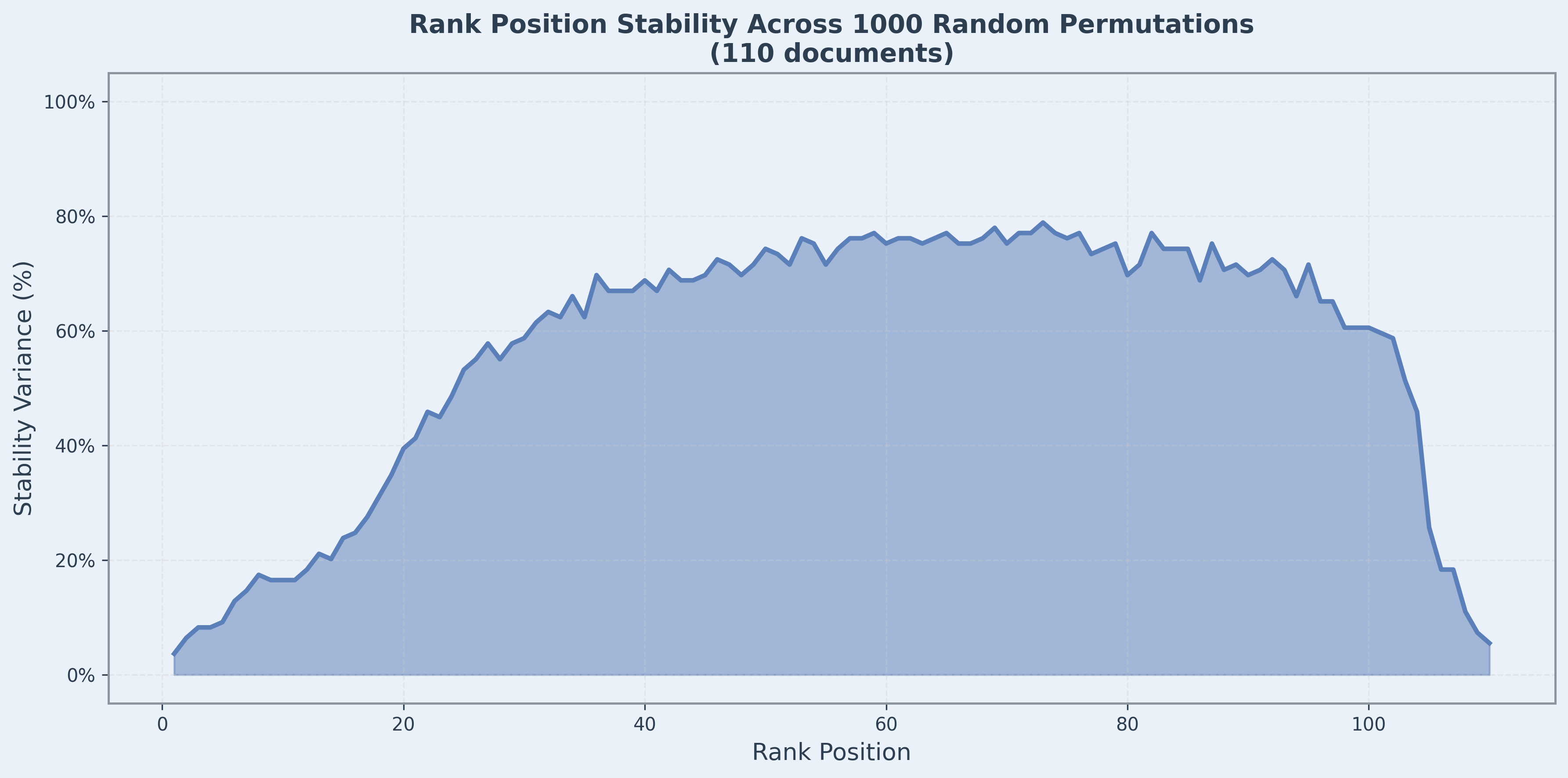
The critical finding is that top-ranked positions show excellent stability. Ranks 1-10 exhibit minimal variance, with the most relevant documents consistently ranking at the top regardless of input order. This is crucial for nDCG@10 and similar top-k metrics. Irrelevant documents consistently stay at the bottom, creating clear separation between relevant and irrelevant content.
The middle section shows significant position swapping, which is expected and acceptable. The model uses causal self-attention and encodes different contextual information based on what appears before them in the sequence.
In practice, where we care about the top-most results, such behavior is completely acceptable. Our evaluation shows jina-reranker-v3 outperforming our earlier generations, including jina-reranker-v2-base-multilingual and jina-colbert-v2, as well as much larger alternatives such as Qwen3-Reranker-4B and jina-reranker-m0 further confirming this.